




本章我们将会介绍pandas数据结构的许多常见的基本功能函数。我们先创建几个示例对象:
index = pd.date_range("1/1/2000", periods=8) # 日期索引
s = pd.Series(np.random.randn(5), index=["a", "b", "c", "d", "e"])
df = pd.DataFrame(np.random.randn(8, 3), index=index, columns=["A", "B", "C"])
前N条和后N条
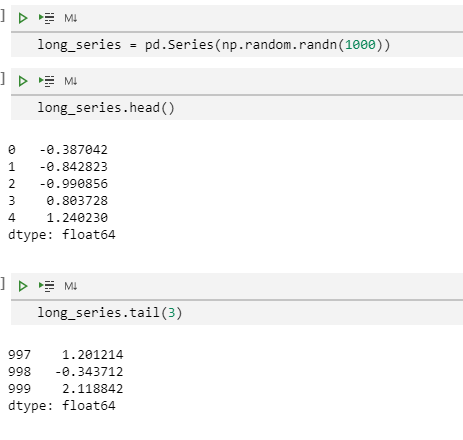
想要查看Series或者DataFrame的小部分示例内容,我们可以使用head()和tail()方法。默认显示5条数据,当然我们可以更改默认值以显示更多行数据。
long_series = pd.Series(np.random.randn(1000))
long_series.head() # 默认获取前5行数据
long_series.tail(3) # 获取后3行数据
属性和隐藏数据
Pandas对象有很多属性能让我们获取到它的元数据
shape:给出对象的轴维度
轴标签:
Series:index
DataFrame:index(行索引名称)和columns(列索引名称)
注意,下面这些属性可以安全地给出!
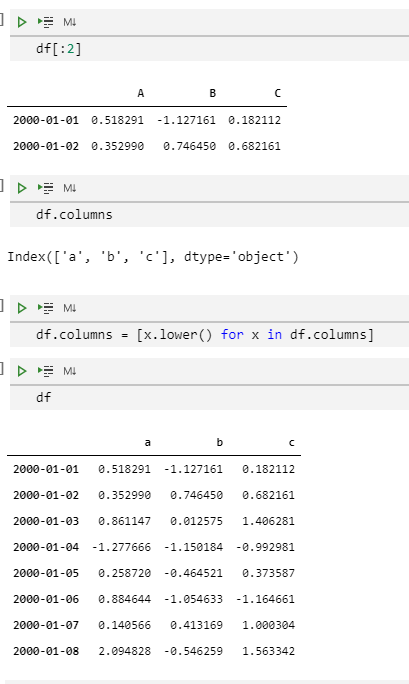
df[:2]
df.columns
df.columns = [x.lower() for x in df.columns]
df
我们可以把pandas对象(Index、Serires、DataFrame)看做是数组的容器,它里面装着数据,并对数据进行计算。
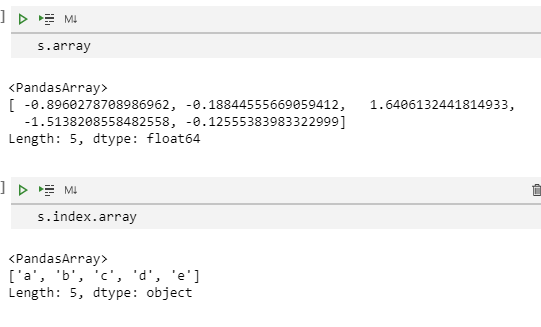
要想获得Index或者Series的数据,可以使用.array属性
s.array
s.index.array
加速操作
灵活的二元运算操作
对两个pandas数据结构进行二元运算操作时,有两个点需要特别注意:
在高维对象和低维对象之间的广播行为
缺失值运算
我们下面来演示下如何分别处理这些问题,当然他们其实是可以同时被处理的。
匹配和广播行为
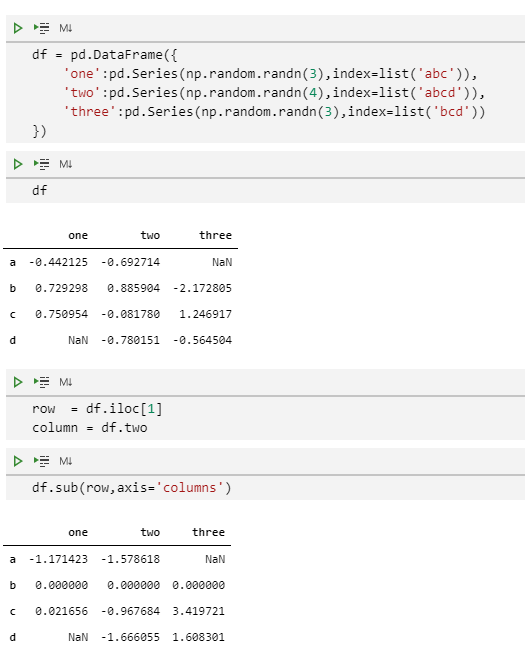
DataFrame拥有方法add()(加法)、sub()(减法)、mul()(乘法)、div()(除法),还有相关联的radd()、rsub()等方法来执行二元运算操作。对于广播操作来说,Series的输入是我们主要关注的。使用这些方法,我们可以通过axis关键词来匹配到index或者columns上。
df = pd.DataFrame({
'one':pd.Series(np.random.randn(3),index=list('abc')),
'two':pd.Series(np.random.randn(4),index=list('abcd')),
'three':pd.Series(np.random.randn(3),index=list('bcd'))
})
df
row = df.iloc[1]
column = df["two"]
df.sub(row, axis="columns")
df.sub(row, axis=1)
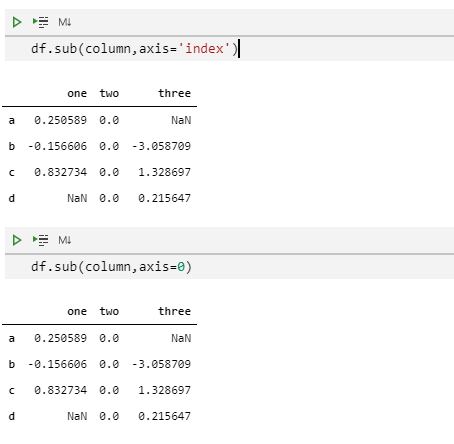
df.sub(column, axis="index")
df.sub(column, axis=0)
而且,我们可以将Series对齐到多级索引的DataFrame上。
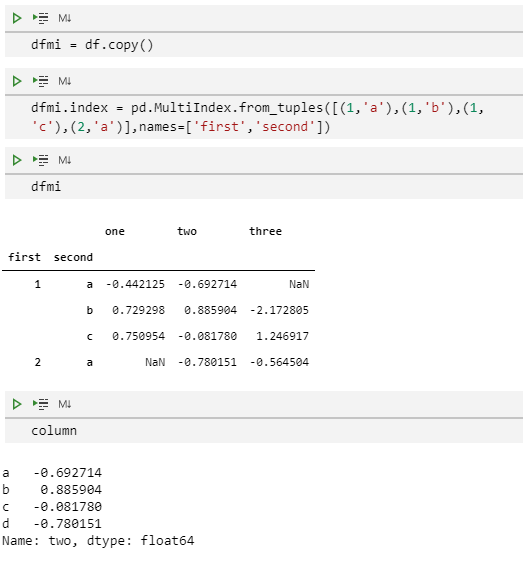
dfmi = df.copy()
dfmi.index = pd.MultiIndex.from_tuples([(1,'a'),(1,'b'),(1,'c'),(2,'a')],names=['first','second'])
dfmi
column
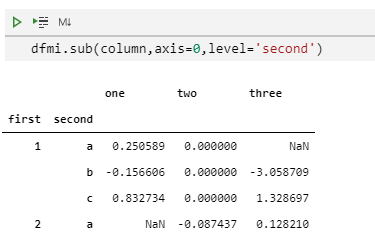
dfmi.sub(column,axis=0,level='second')
缺失值的填充操作
在Series和DataFrame中,四则运算函数都有个fill_value选项,当参与运算的对象中有缺失值时用这个参数进行填充,然后再进行四则运算计算。
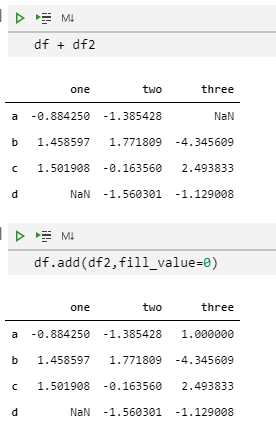
例如,当对两个DataFrame进行加法运算时,我们希望把NaN当做0来进行计算,除非两个对象的对应位置都为NaN,这时得到的结果就是NaN(然后我们可以使用fillna函数来替换结果中的NaN)。
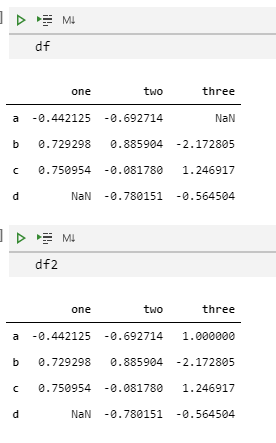
df
df2
df + df2
df.add(df2, fill_value=0)
布尔缩减
我们可以使用缩减函数:empty()、all()和bool()来提供总结凝练布尔运算结果的途径。
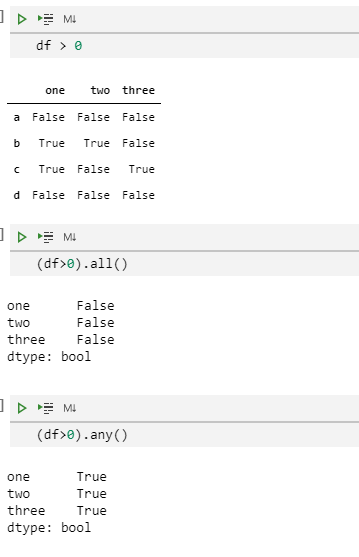
df > 0
(df > 0).all()
(df > 0).any()
我们可以缩减到只有一个结果
(df > 0).any().any()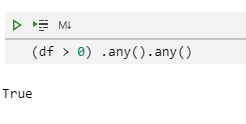
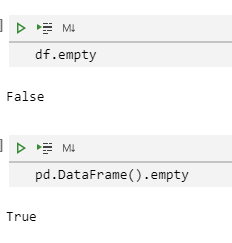
我们可以使用empty属性来判断pandas是否为空
df.empty
pd.DataFrame().empty
比较两个对象是否相等
我们会发现,有多种方法可以得到相同的结果。例如,df + df 和 df * 2 。为了测试下我们用上面这个方式能否得到两个相同的结果,我们可能会采用( df + df == df * 2 ).all() 。但实际上,这个表达式的结果并不是我们期望的:
df + df == df * 2
(df + df == df * 2).all()
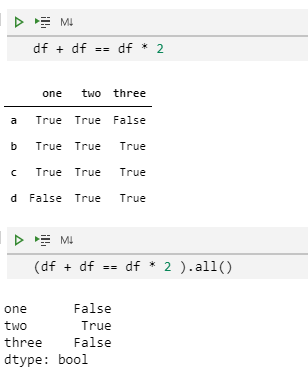
请注意,df + df == df * 2 得到的布尔DataFrame结果里面包含了False值!这是因为NaN是无法进行相等比较操作的:
In : np.nan == np.nan
Out: False
因此pandas对象(Series、DataFrame)有方法equals()来确定两个对象是否相等。它会将对应位置的NaN视为相等。
In [60]: (df + df).equals(df * 2)
Out[60]: True
注意,Series/DataFrame的index需要按顺序排序并且对应位置的index要相等。
In [61]: df1 = pd.DataFrame({"col": ["foo", 0, np.nan]})
In [62]: df2 = pd.DataFrame({"col": [np.nan, 0, "foo"]}, index=[2, 1, 0])
In [63]: df1.equals(df2)
Out[63]: False
In [64]: df1.equals(df2.sort_index())
Out[64]: True
比较两个类数组对象
我们可以方便地对一个pandas对象和一个标量值进行元素比较:
pd.Series(["foo", "bar", "baz"]) == "foo"
pd.Index(["foo", "bar", "baz"]) == "foo"
pd.DataFrame({
'a':['foo','bar','baz'],
'b':['baz','foo','bar']
}) == 'foo'

pandas还可以对两个等长的不同的类数组对象进行元素比较:
pd.Series(['foo','bar','baz']) == pd.Index(['foo','bar','qux'])
pd.Series(['foo','bar','baz']) == np.array(['foo','bar','qux'])
pd.Series(['foo','bar','baz']) == ['foo','bar','baz']

如果我们想比较两个不等长的Index或Series对象时,将会报出ValueError错误:
pd.Series(['foo', 'bar', 'baz']) == pd.Series(['foo', 'bar'])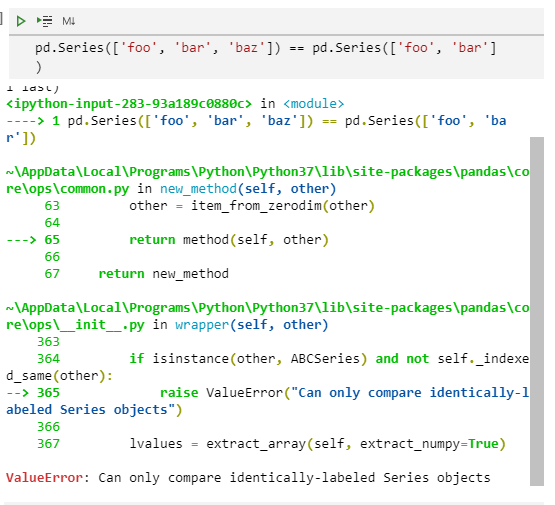
合并重叠数据集
我们经常会遇到这样的问题,想要比较两个相似的数据集,其中一个比另一个要更优质。例如,代表一个经济指标的两个相似数据集,其中一个数据质量要更高。然而低质量的数据集拥有更久远的历史数据或者具有更完整的数据范围。像这样的场景,我们想要合并两个DataFrame对象,把一个DataFrame的缺失值用另一个DataFrame对应位置的值来进行填充。能做到这个操作的函数是combine_first(),我们举例说明:
df1 = pd.DataFrame(
{
'A':[1.0,np.nan,3.0,5.0,np.nan],
'B':[np.nan,2.0,3.0,np.nan,6.0]
}
)
df2 = pd.DataFrame(
{
'A':[5.0, 2.0, 4.0, np.nan, 3.0, 7.0],
'B':[np.nan, np.nan, 3.0, 4.0, 6.0, 8.0],
}
)


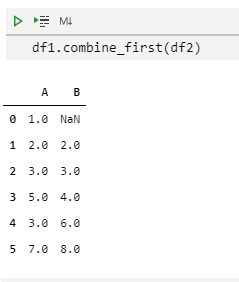
一般的数据合并
上面介绍的combine_first()函数调用更普通的DataFrame.combine()函数。这个方法需要给出另外一个DataFrame和一个组合器函数。它会根据对应的index来应用组合器函数(列名称要保证一致)。
我们举例来说明用这个函数生成跟combine_first()作用一样的结果:
def combiner(x, y):
return np.where(pd.isna(x), y, x)
df1.combine(df2, combiner)
A B
0 1.0 NaN
1 2.0 2.0
2 3.0 3.0
3 5.0 4.0
4 3.0 6.0
5 7.0 8.0
描述性统计
pandas拥有大量的方法和相关的操作可以对Series、DataFrame进行描述性统计分析。其中大多数为聚合操作(可以产生一个低维结果),类似sum()(求和函数),mean()(平均数函数)和quantile()(计算分位数的函数),但是类似cumsum()(移动累计求和)和cumprod()(移动累计乘积)这样的函数可以产生一个等大小的对象。一般来说,这些函数方法都有一个axis参数,可以通过名称或整数值来指定它。
Series:不需要axis参数
DataFrame:"index"(axis=0,默认值);"columns"(axis=1)
例如:
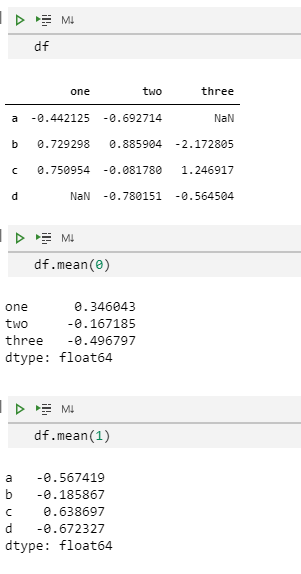
df
df.mean(0)
df.mean(1)
这些方法都有一个skipna选项表示在进行统计计算时是否包含缺失值(默认值为True,也就是计算不含缺失值)
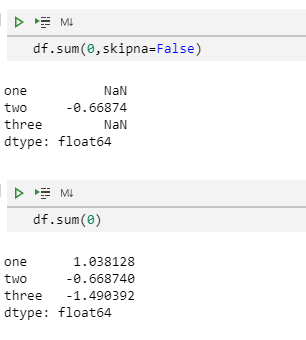
df.sum(0, skipna=False)
df.sum(0)
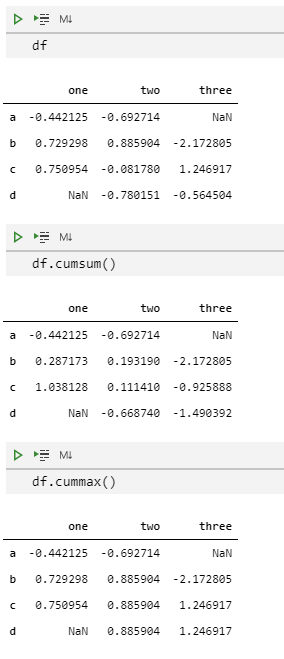
类似cumsum()和cumprod()这样的累计计算方法,它们会保留NaN值的位置。这种处理NaN的方式跟expanding()和rolling()函数不同,它俩会通过min_periods参数来控制NaN的处理方式。
df
df.cumsum()
df.cummax()
描述性统计计算函数将会在后面的章节统计详细讲解。
数据总结:describe函数
有一个非常方便的函数——describe(),可以计算Series/DataFrame的不同的描述性统计指标。
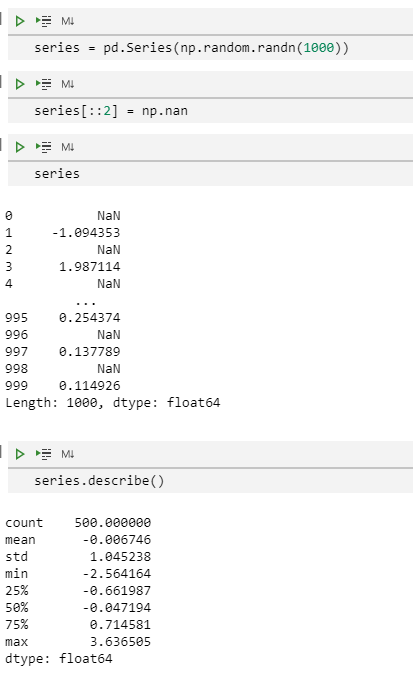
series = pd.Series(np.random.randn(1000))
series[::2] = np.nan # 每两个元素值赋值NaN
series.describe()
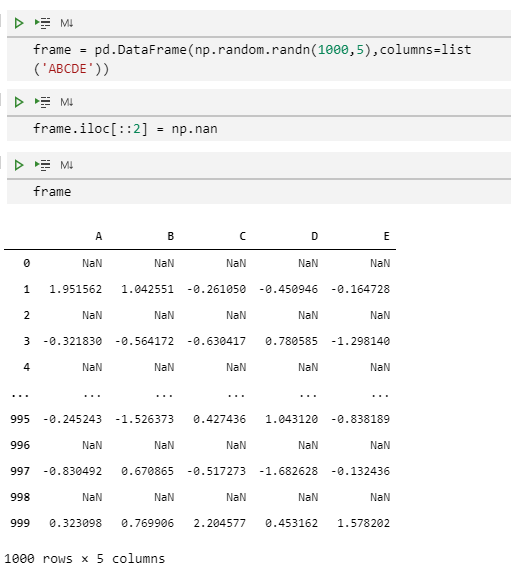
frame = pd.DataFrame(np.random.randn(1000,5),columns=list('ABCDE'))
frame.iloc[::2] = np.nan
frame
frame.describe()
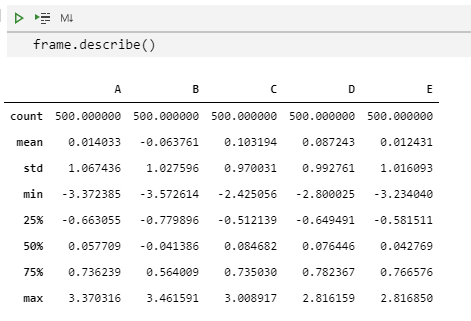
我们可以指定输出的结果中包含的百分位:
frame.describe(percentiles=[0.05,0.25,0.75,0.95])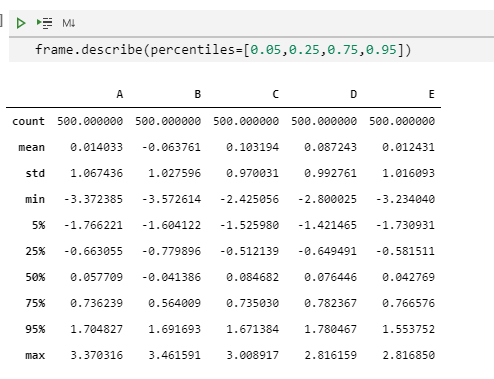
从结果中,我们可以看到,虽然我们并没有指定50%位值,但是这个中位数是默认包含在结果中的。
对于一个非数值型的Series对象,describe()可以给出它的值中唯一值的数量、出现频次最高的值等指标:
s = pd.Series(['a','a','b','a','a',np.nan,'c','d','a'])
s.describe()
count 8
unique 4
top a
freq 5
dtype: object
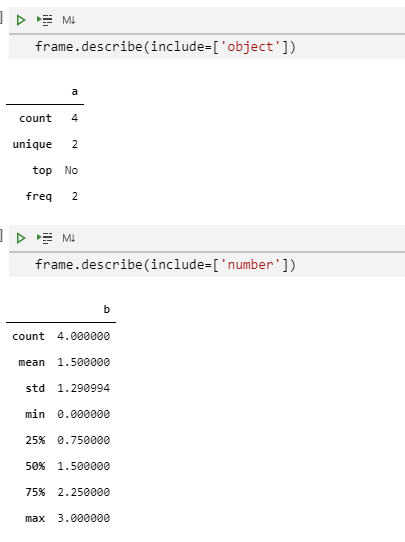
请注意:如果是一个包含多种数据类型的DataFrame对象,describe()函数将会只返回包含数值型数据的列的结果,如果没有数值型的列,那么就返回category类型的列:
frame = pd.DataFrame({'a':['Yes','Yes','No','No'],'b':range(4)})
frame.describe()

上面的这个行为可以通过输入include/exclude参数列表来控制。特殊值all也可以被使用。
frame.describe(include=["object"])
frame.describe(include=["number"])
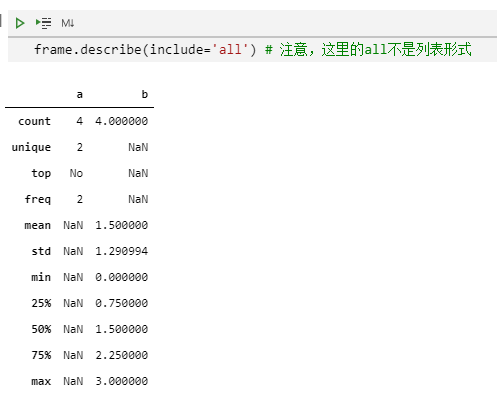
frame.describe(include='all') # 注意,这里的all不是列表形式
最大最小值的索引
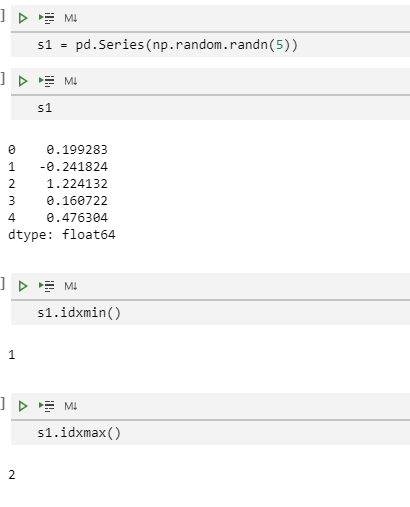
idxmin()和idxmax()函数可以获取Serires/DataFrame对象的最大最小值的索引值:
s1 = pd.Series(np.random.randn(5))
s1
s1.idxmin()
s1.idxmax()
df1 = pd.DataFrame(np.random.randn(5, 3), columns=["A", "B", "C"])
df1
df1.idxmin(axis=0)
df1.idxmax(axis=1)
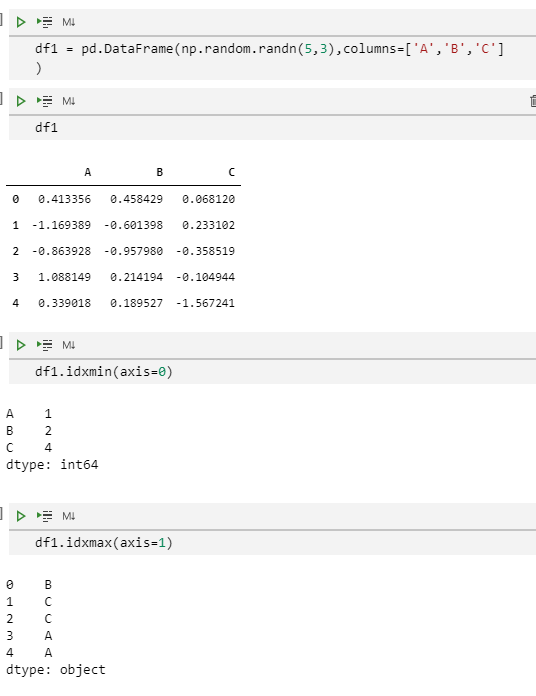
当数据集中有多行或多列可以匹配最大最小值时,idxmin()和idxmax()将会返回第一个匹配值的位置。
值计数(直方图)模式
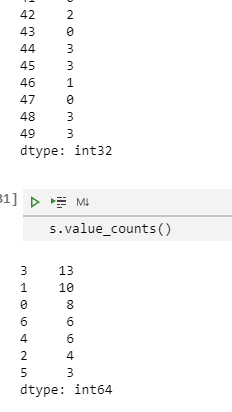
value_counts()这个Series方法和高阶函数可以计算一维数据集的直方图。它也可以被用在数组矩阵上:
s = pd.Series(np.random.randint(0,7,50))
s.value_counts()

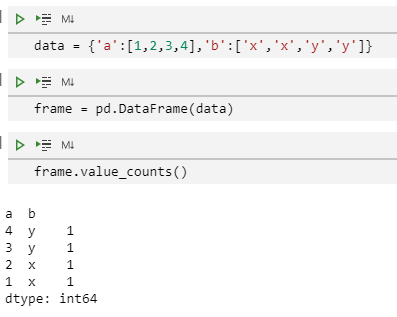
value_couonts()方法也可以用在多列组合结果上。默认计算所有的列,但是可以通过subset参数来选择列的子集
data = {"a": [1, 2, 3, 4], "b": ["x", "x", "y", "y"]}
frame = pd.DataFrame(data)
frame.value_counts()
离散化和分位数
我们可以使用cut()(基于值装箱子)、qcut()(基于样本分位数装箱子)函数来将连续的值离散化。
arr = np.random.randn(20)
arr
factor = pd.cut(arr,4)
factor

qcut()基于样本分位数进行分箱计算。例如,我们可以把正态分布的数据四等分:
pd.value_counts(pd.qcut(np.random.randn(30),[0,0.25,0.5,0.75,1]))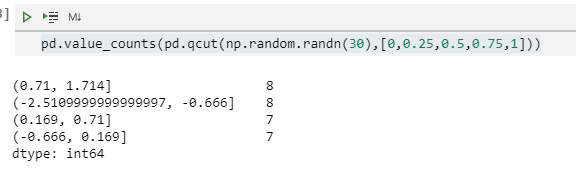
我们也可以传递无穷大值来定义切分值的箱子:
In [140]: factor = pd.cut(arr, [-np.inf, 0, np.inf])
In [141]: factor
Out[141]:
[(-inf, 0.0], (0.0, inf], (0.0, inf], (-inf, 0.0], (-inf, 0.0], ..., (-inf, 0.0], (-inf, 0.0], (-inf, 0.0], (0.0, inf], (0.0, inf]]
Length: 20
Categories (2, interval[float64]): [(-inf, 0.0] < (0.0, inf]]
