




EdgeDB- An Efficient Time-Series Database for Edge Computing.pdf
免费下载

Received July 30, 2019, accepted September 21, 2019, date of publication September 26, 2019, date of current version October 11, 2019.
Digital Object Identifier 10.1109/ACCESS.2019.2943876
EdgeDB: An Efficient Time-Series Database
for Edge Computing
YANG YANG
1
, QIANG CAO
1
, (Senior Member, IEEE), AND HONG JIANG
2
, (Fellow, IEEE)
1
Wuhan National Laboratory for Optoelectronics, Key Laboratory of Information Storage System, Ministry of Education, Huazhong University of Science and
Technology, Wuhan 430074, China
2
Department of Computer Science and Engineering, University of Texas at Arlington, Arlington, TX 76019, USA
Corresponding author: Qiang Cao (caoqiang@hust.edu.cn)
This work was supported in part by the Creative Research Group Project of NSFC under Grant 61821003, in part by the NSFC under
Grant 61872156, in part by the National Key Research and Development Program of China under Grant2018YFA0701804, in part by
the Fundamental Research Funds for the Central Universities under Grant 2018KFYXKJC037, in part by the U.S. NSF under
Grant CCF-1704504 and Grant CCF-1629625, and in part by the Alibaba Group through Alibaba Innovative Research (AIR) Program.
ABSTRACT Massive time-series data streams from high-sampling-frequency sensors in Internet of
Things (IoT) can overwhelm the networks connecting the sensors to centralized clouds. Thus, edge com-
puting servers have to be introduced to locally store and analyze growing time-series data. Unfortunately,
conventional time-series databases exhibit low efficiency on edge nodes with limited resources for both
computation and storage. In this paper, we propose a highly efficient time-series database, called EdgeDB,
to fully utilize the capacity of the edge nodes. EdgeDB effectively improves the performances of both
inserting and retrieving data from ingest streams by efficiently merging multiple streams and optimizing
the storage data structure concurrently. EdgeDB first compactly organizes multiple online streams into
a tablet within a time window and embeds predefined aggregate query results together. EdgeDB adopts
Time Partitioned Elastic Index (TPEI) to build indexing on all tablets, enhancing the time-range query
performance while reducing the memory usage by optimizing the indexing storage. EdgeDB further develops
Time Merged Tree (TMTree) to combine a set of tablets into a large one, significantly boosting the write
throughput and potentially strengthening the performance of inter-tablet query. Extensive experiments based
on real-world datasets show that, compared with the state-of-the-art time-series database BTrDB, EdgeDB
achieves performance improvements of up to 2.2× in insert throughput, 3.6× in write throughput, and 67%
in query latency with lower memory consumption.
INDEX TERMS Time-series database, edge computing, time partitioned elastic index, I/O optimization.
I. INTRODUCTION
Internet of Things (IoT) applications, commonly deploying
a myriad of sensors to collect a large amount of time-series
data from physical environments around human beings, are
designed to help us monitor [22], [31], analyze [10], [34],
forecast our concerned events [14], [28], and then make
timely and correct responses.
With the explosive growth of time-series data generated
by high-sampling-frequency sensors, the long-distance net-
works between sensors and data centers have become a per-
formance bottleneck for traditional data management systems
running in the datacenter-based cloud environment, as illus-
trated in Figure 1a, due to high data transfer overhead [3].
The associate editor coordinating the review of this manuscript and
approving it for publication was Shaojun Wang.
This necessitates IoT infrastructures to embrace edge com-
puting that locally processes the data on edge nodes effi-
ciently, in order to improve the responsiveness and prevent
sensor-generated data from flooding the centralized cloud.
Although existing databases have the ability to process
large-scale time-series data streams on cloud-based infras-
tructure, they are not well designed to run on the edge nodes
with limited hardware resources, power budget, and scalabil-
ity. Existing time-series databases [2], [12], [22] separately
ingest, organize, store, and query data of each stream in a
rational table. And they provide standard inter-table opera-
tions to enable inter-stream data retrieval and processing, but
at very high resource cost. This limitation can be overcome by
scaling resources up and/or out to ensure high overall perfor-
mance, a solution that is clearly not suitable nor applicable
for emerging edge nodes with limited hardware resources.
VOLUME 7, 2019
This work is licensed under a Creative Commons Attribution 4.0 License. For more information, see http://creativecommons.org/licenses/by/4.0/
142295
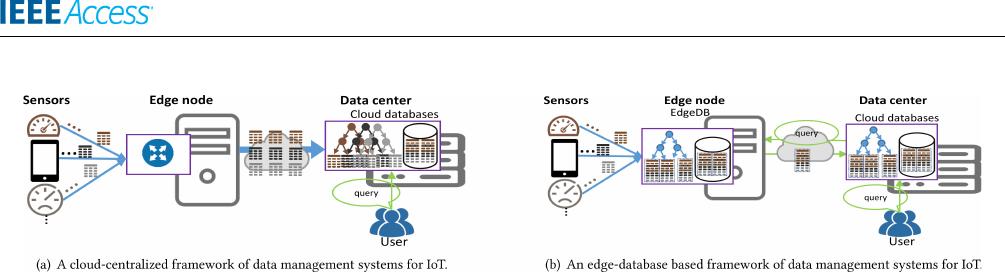
Y. Yang et al.: EdgeDB: Efficient Time-Series Database for Edge Computing
FIGURE 1. A comparison of cloud-centralized framework vs edge-database based framework for IoT. Cloud-centralized framework needs to
transfer all time-series data to remote cloud for data management with significant network overhead. Edge-database based framework can utilize
the edge node to locally process the collected data, and transfers important data and aggregated values to cloud, then collaborates with the
centralized databases to perform detailed queries.
Nevertheless, it is desirable for the edge nodes to accommo-
date not only high-throughput data ingestion but also real-
time data retrieval from both fresh and historical data in local
storage to satisfy the requirements of IoT applications.
In this paper, we present EdgeDB, an efficient time-series
database with edge servers (shown in Figure 1b) designed to
manage thousands of high-sampling-frequency sensors while
providing higher insert performance, query performance, and
write speed, with lower resource requirement than existing
databases. The key idea behind EdgeDB is to design an opti-
mal organization and process flow by efficiently combining
multiple online streams in both query-friendly and store-
friendly ways, enabled by the three key mechanisms of multi-
stream merging, indexing, and storing. The multi-stream
merging mechanism is designed to compactly re-organizes
multiple correlated data streams within a time window into
a tablet. Then, the multi-stream indexing mechanism, called
Time Partitioned Elastic Index (TPEI), is proposed to index
these tablets efficiently, enabling real-time queries. Finally,
a write-optimized strategy is developed to combine multiple
tablets into a group to allow fast inter-stream accesses.
In summary, the contributions of this paper are as follows:
1) We propose a multi-stream merging mechanism
to compactly organize multiple correlated streams
together at runtime, supporting highly efficient inser-
tion and join query operations; and introduce Time
Partitioned Elastic Index to accelerate time-range
queries with small memory overheads.
2) We present Time Merged Tree to merge multiple tablets
into a large group to flush to the storage devices with a
single write operation, to improve the write throughput
and to speed up inter-tablet join query operations.
3) We implement and evaluate the EdgeDB prototype.
The experimental results driven by real-world datasets
demonstrate that EdgeDB outperforms a state-of-the-
art time-series database BTrDB by up to 3.6× in write
throughput, 2.2× in insert throughput, and up to 67%
in query latency, with lower memory consumption.
The remainder of this paper is organized as follows:
Section II presents background and motivation. The design
details of EdgeDB are described in Section III. In Section IV,
we evaluate EdgeDB with experimental results. Section V
concludes this paper.
II. BACKGROUND AND MOTIVATION
A. EDGE COMPUTING OF IoT
Internet of Things (IoT) is poised to fundamentally
change how we interact with our surrounding environments
[31], [35]. By deploying a variety of increasing numbers of
sensors with high-sampling-frequency, we are able to per-
ceive the surrounding environment quickly and clearly. More
importantly, we can make informed and timely decisions
in emergency situations using the sensor-generated data.
However, the considerable volumes of data make the long-
distance networks a severe performance bottleneck, as illus-
trated in Figure 1a, because of a long time required for data
transfer to remote servers. For example, a small electricity
grid with 1,000 smart meters will produce 22.4 MB data
per second, and the data must be transferred to datacenters
over intermittent LTE with high transmission delays [2]. Even
though these servers have powerful hardware, the high trans-
fer latency makes it difficult, if not impossible, for the cloud
to make real-time decisions based on these data. To overcome
this problem, edge computing is introduced to provide near-
data processing [15], [33].
With the help of edge computing, we have the poten-
tial to store and process all collected data in a timely
manner on the edge nodes, instead of remote servers. For
example, an autonomous vehicle generates gigabytes of
data every second [6] that require real-time processing to
make correct decisions under various circumstances. The
vehicle-mounted computer is a typical edge node, which can
manage and analyze these data locally, and provide quick
responses or advance warnings for the driver.
Therefore, edge nodes should be able to support extremely
high insertion throughput, as well as real-time responses to
various types of queries. For instance, users not only need to
query the raw data tuples of any time-series stream to analyze
detailed phenomena, but also need to get the time-range based
aggregated values to see the holistic views, or perform join
query to get the correlated data tuples from a number of
streams within a period of time to further comprehensively
analyze these streams. As a concrete example, in order to cal-
culate the Pearson Correlation Coefficients among all streams
within a (T1, T2) time period, we need to first perform
‘‘Select * from all streams where Time>T1 & Time<T2’’
to get the data of these streams for further processing.
142296 VOLUME 7, 2019
of 13
免费下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

评论