

1



(1条消息)如何优化MySQL千万级大表,我写了6000字的解读_数据库_杨建荣的学习笔记-CSDN博客.pdf
5墨值下载
(1条消息)如何优化MySQL千万级大表,我写了6000字的解读_
数据库_杨建荣的学习笔记-CSDN博客
这是学习笔记的第 2138 篇文章
千万级大表如何优化,这是一个很有技术含量的问题,通常我们的直觉思维都会跳转到拆分或者数据分区,在
此我想做一些补充和梳理,想和大家做一些这方面的经验总结,也欢迎大家提出建议。
从一开始脑海里开始也是火光四现,到不断的自我批评,后来也参考了一些团队的经验,我整理了下面的大纲
内容。
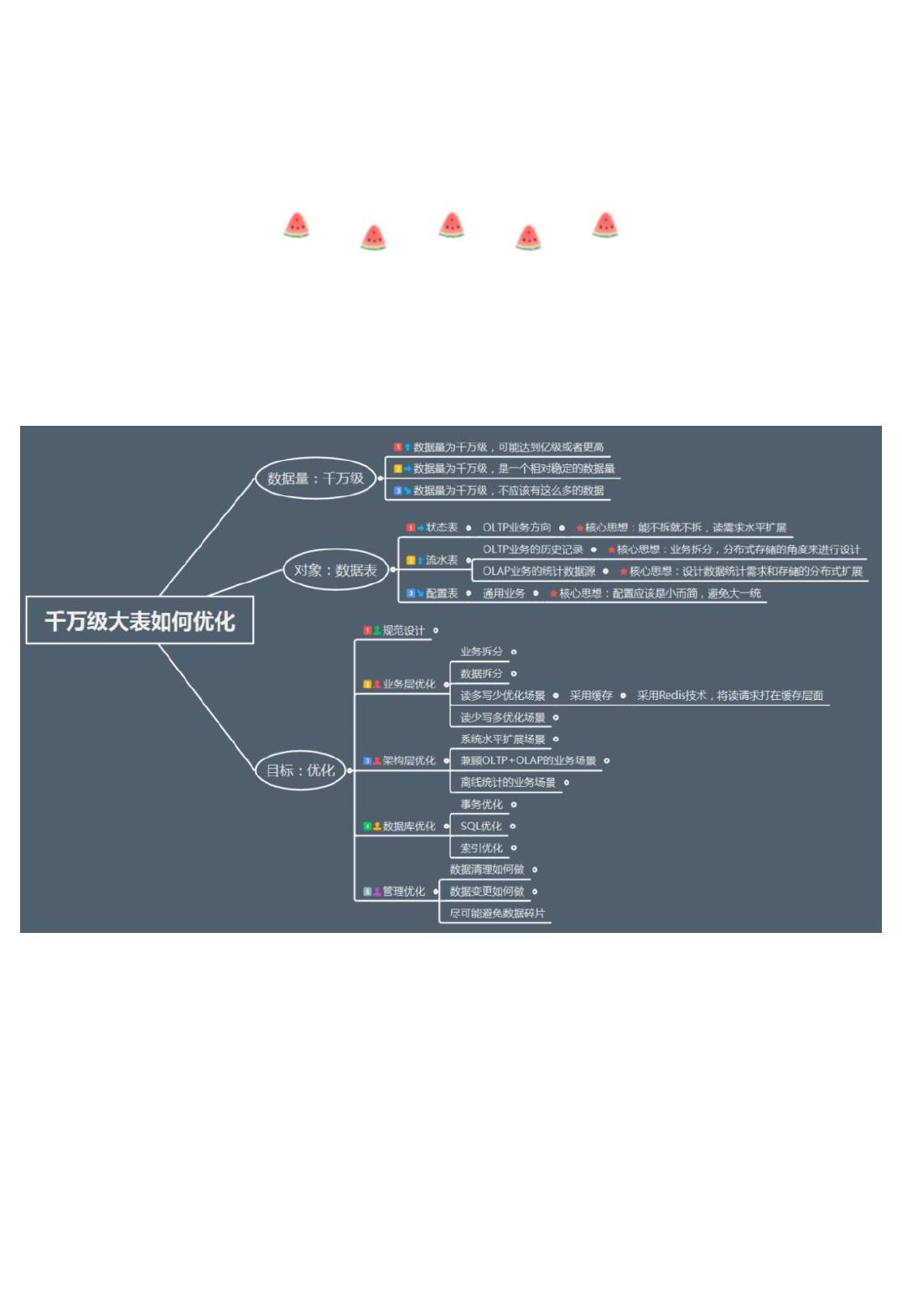
既然要吃透这个问题,我们势必要回到本源,我把这个问题分为三部分:
“千万级”,“大表”,“优化”,
也分别对应我们在图中标识的
“数据量”,“对象”和“目标”。
我来逐步展开说明一下,从而给出一系列的解决方案。
1.数据量:千万级
千万级其实只是一个感官的数字,就是我们印象中的数据量大。 这里我们需要把这个概念细化,因为随着业务
和时间的变化,数据量也会有变化,我们应该是带着一种动态思维来审视这个指标,从而对于不同的场景我们

应该有不同的处理策略。
1) 数据量为千万级,可能达到亿级或者更高
通常是一些数据流水,日志记录的业务,里面的数据随着时间的增长会逐步增多,超过千万门槛是很容易的一
件事情。
2) 数据量为千万级,是一个相对稳定的数据量
如果数据量相对稳定,通常是在一些偏向于状态的数据,比如有1000万用户,那么这些用户的信息在表中都有
相应的一行数据记录,随着业务的增长,这个量级相对是比较稳定的。
3) 数据量为千万级,不应该有这么多的数据
这种情况是我们被动发现的居多,通常发现的时候已经晚了,比如你看到一个配置表,数据量上千万;或者说一
些表里的数据已经存储了很久,99%的数据都属于过期数据或者垃圾数据。
数据量是一个整体的认识,我们需要对数据做更近一层的理解,这就可以引出第二个部分的内容。
2.对象:数据表
数据操作的过程就好比数据库中存在着多条管道,这些管道中都流淌着要处理的数据,这些数据的用处和归属
是不一样的。
一般根据业务类型把数据分为三种:
(1)流水型数据
流水型数据是无状态的,多笔业务之间没有关联,每次业务过来的时候都会产生新的单据,比如交易流水、支
付流水,只要能插入新单据就能完成业务,特点是后面的数据不依赖前面的数据,所有的数据按时间流水进入
数据库。
(2)状态型数据
状态型数据是有状态的,多笔业务之间依赖于有状态的数据,而且要保证该数据的准确性,比如充值时必须要
拿到原来的余额,才能支付成功。
(3)配置型数据
此类型数据数据量较小,而且结构简单,一般为静态数据,变化频率很低。
至此,我们可以对整体的背景有一个认识了,如果要做优化,其实要面对的是这样的3*3的矩阵,如果要考虑表
的读写比例(读多写少,读少写多...),那么就会是3*3*4=24种,显然做穷举是不显示的,而且也完全没有必
要,可以针对不同的数据存储特性和业务特点来指定不同的业务策略。
对此我们采取抓住重点的方式,把常见的一些优化思路梳理出来,尤其是里面的核心思想,也是我们整个优化
设计的一把尺子,而难度决定了我们做这件事情的动力和风险。
数据量增长情况 数据表类
型
业务特点 优化核心思想 优化难
度
of 15
5墨值下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

评论