




41丨十字路口上的Kubernetes默认调度器.pdf
10墨值下载

41 | 十字路口上的Kubernetes默认调度器
2018-11-26 张磊
深入剖析Kubernetes
进入课程
讲述:张磊
时长 09:51 大小 4.52M
你好,我是张磊。今天我和你分享的主题是:十字路口上的 Kubernetes 默认调度器。
在上一篇文章中,我主要为你介绍了 Kubernetes 里关于资源模型和资源管理的设计方
法。而在今天这篇文章中,我就来为你介绍一下 Kubernetes 的默认调度器(default
scheduler)。
在 Kubernetes 项目中,默认调度器的主要职责,就是为一个新创建出来的 Pod,寻找一
个最合适的节点(Node)。
而这里“最合适”的含义,包括两层:
1. 从集群所有的节点中,根据调度算法挑选出所有可以运行该 Pod 的节点;
下载APP
2. 从第一步的结果中,再根据调度算法挑选一个最符合条件的节点作为最终结果。
所以在具体的调度流程中,默认调度器会首先调用一组叫作 Predicate 的调度算法,来检
查每个 Node。然后,再调用一组叫作 Priority 的调度算法,来给上一步得到的结果里的每
个 Node 打分。最终的调度结果,就是得分最高的那个 Node。
而我在前面的文章中曾经介绍过,调度器对一个 Pod 调度成功,实际上就是将它的
spec.nodeName 字段填上调度结果的节点名字。
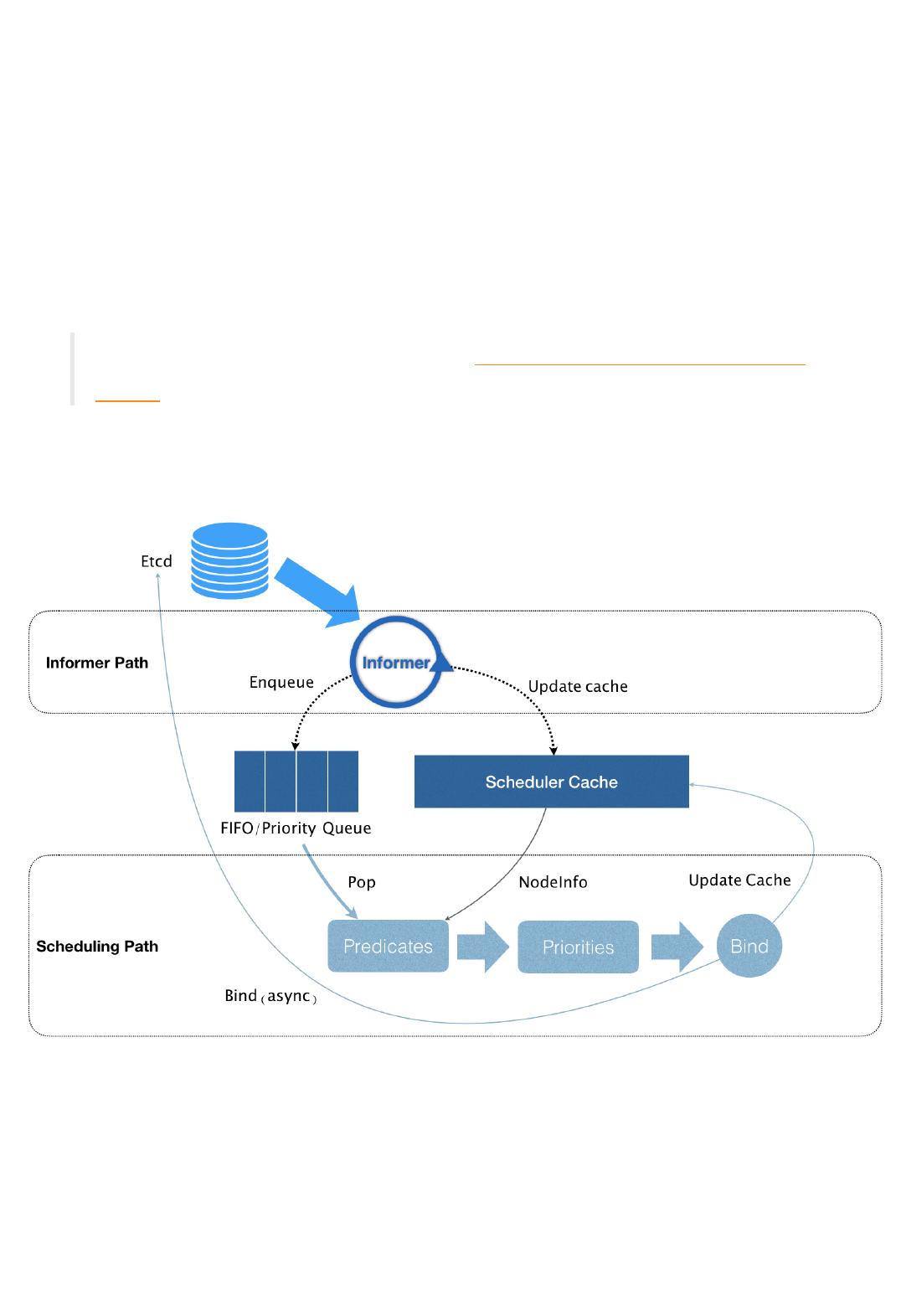
在 Kubernetes 中,上述调度机制的工作原理,可以用如下所示的一幅示意图来表示。
可以看到,Kubernetes 的调度器的核心,实际上就是两个相互独立的控制循环。
其中,第一个控制循环,我们可以称之为 Informer Path。它的主要目的,是启动一系列
Informer,用来监听(Watch)Etcd 中 Pod、Node、Service 等与调度相关的 API 对象
的变化。比如,当一个待调度 Pod(即:它的 nodeName 字段是空的)被创建出来之
后,调度器就会通过 Pod Informer 的 Handler,将这个待调度 Pod 添加进调度队列。
备注:这里你可以再回顾下第 14 篇文章《深入解析 Pod 对象(一):基本
概念》中的相关内容。
of 9
10墨值下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

文档被以下合辑收录
评论