




Stable Diffusion 推理加速技巧解析.pdf
免费下载

Stable Diffusion 推理加速技巧解析
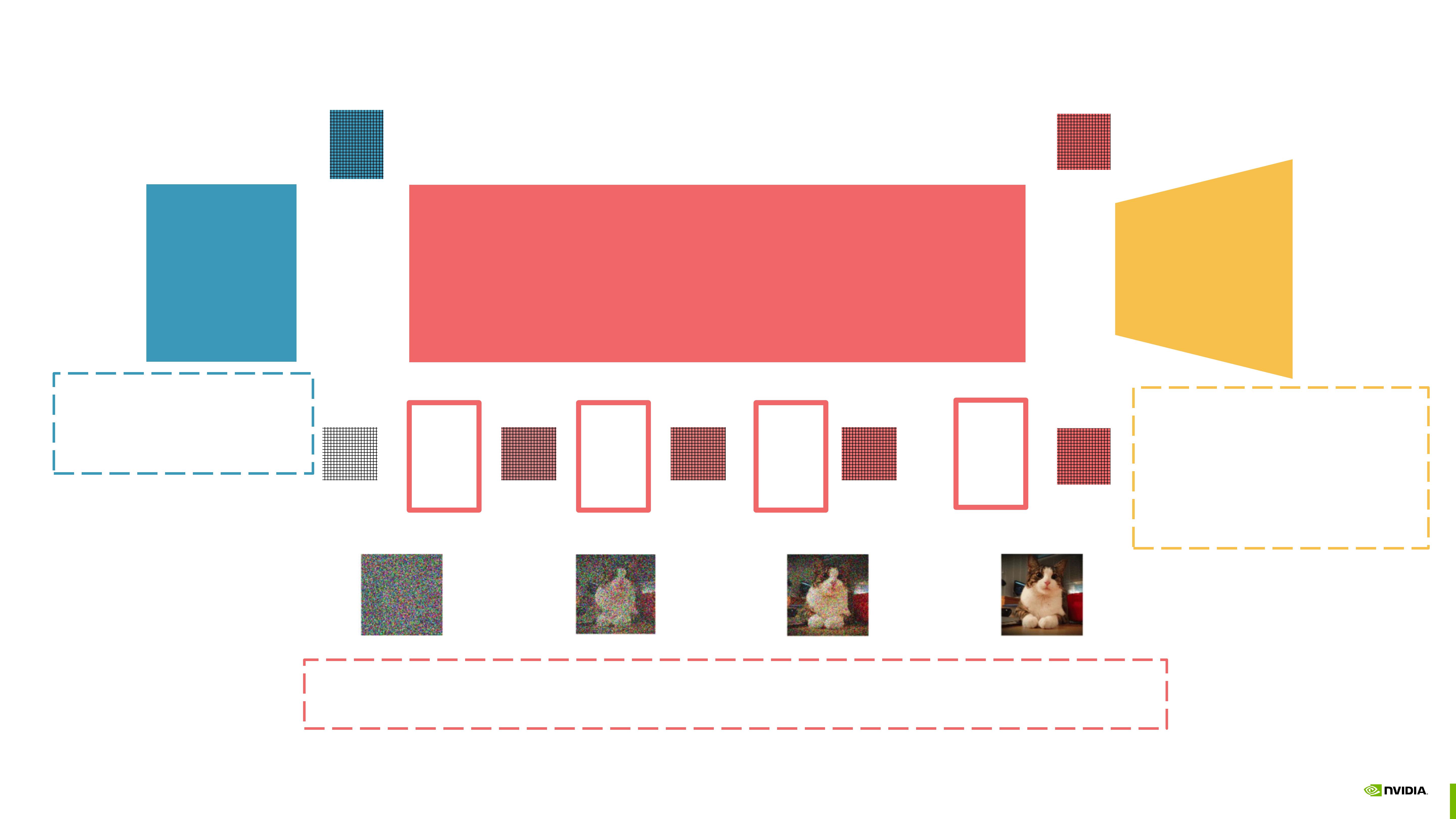
Stable Diffusion
process
Text Encoder
(CLIP Text)
Image Information Creator
(Unet + Scheduler)
Image Decoder
(Autoencoder
decoder)
77 x 768
Token embeddings
4 x 64 x 64
Processed image
information tensor
Unet
Step
1
Unet
Step
2
Unet
Step
3
Unet
Step
50
…
UNet + Scheduler to gradually process/diffuse information in the information (latent) space.
• Input: text embeddings and a starting multi-dimensional array made up of noise.
• Output: A processed information array
ClipText for text encoding.
• Input: text.
• Output: 77 token embeddings
vectors, each in 768 dimensions
Autoencoder Decoder that paints the
final image using the processed
information array.
• Input: The processed information array
(dimensions: (4,64,64))
• Output: The resulting image
(dimensions: (3, 512, 512) which are
(red/green/blue, width, height))
of 23
免费下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

文档被以下合辑收录
评论