

1



Apache Doris 2 如何实现导入性能提升 2-8 倍.pdf
免费下载

Apache Doris 2.0 如何实现导入性能提
升 2-8 倍
数据导入吞吐是 OLAP 系统性能的重要衡量标准之一,高效的数据导
入能力能够加速数据实时处理和分析的效率。随着 Apache Doris 用户
规模的不断扩大, 越来越多用户对数据导入提出更高的要求,这也为
Apache Doris 的数据导入能力带来了更大的挑战。
为提供快速的数据写入支持,Apache Doris 存储引擎采用了类似 LS
M Tree 结构。在进行数据导入时,数据会先写入 Tablet 对应的 M
emTable 中,MemTable 采用 SkipList 的数据结构。当 MemTabl
e 写满之后,会将其中的数据刷写(Flush)到磁盘。数据从 MemTa
ble 刷写到磁盘的过程分为两个阶段,第一阶段是将 MemTable 中的
行存结构在内存中转换为列存结构,并为每一列生成对应的索引结构;
第二阶段是将转换后的列存结构写入磁盘,生成 Segment 文件。
具体而言,Apache Doris 在导入流程中会把 BE 模块分为上游和下
游,其中上游 BE 对数据的处理分为 Scan 和 Sink 两个步骤:首先
Scan 过程对原始数据进行解析,然后 Sink 过程将数据组织并通过
RPC 分发给下游 BE。当下游 BE 接收数据后,首先在内存结构 Mem
Table 中进行数据攒批,对数据排序、聚合,并最终下刷成数据文件(也
称 Segment 文件)到硬盘上来进行持久化存储。
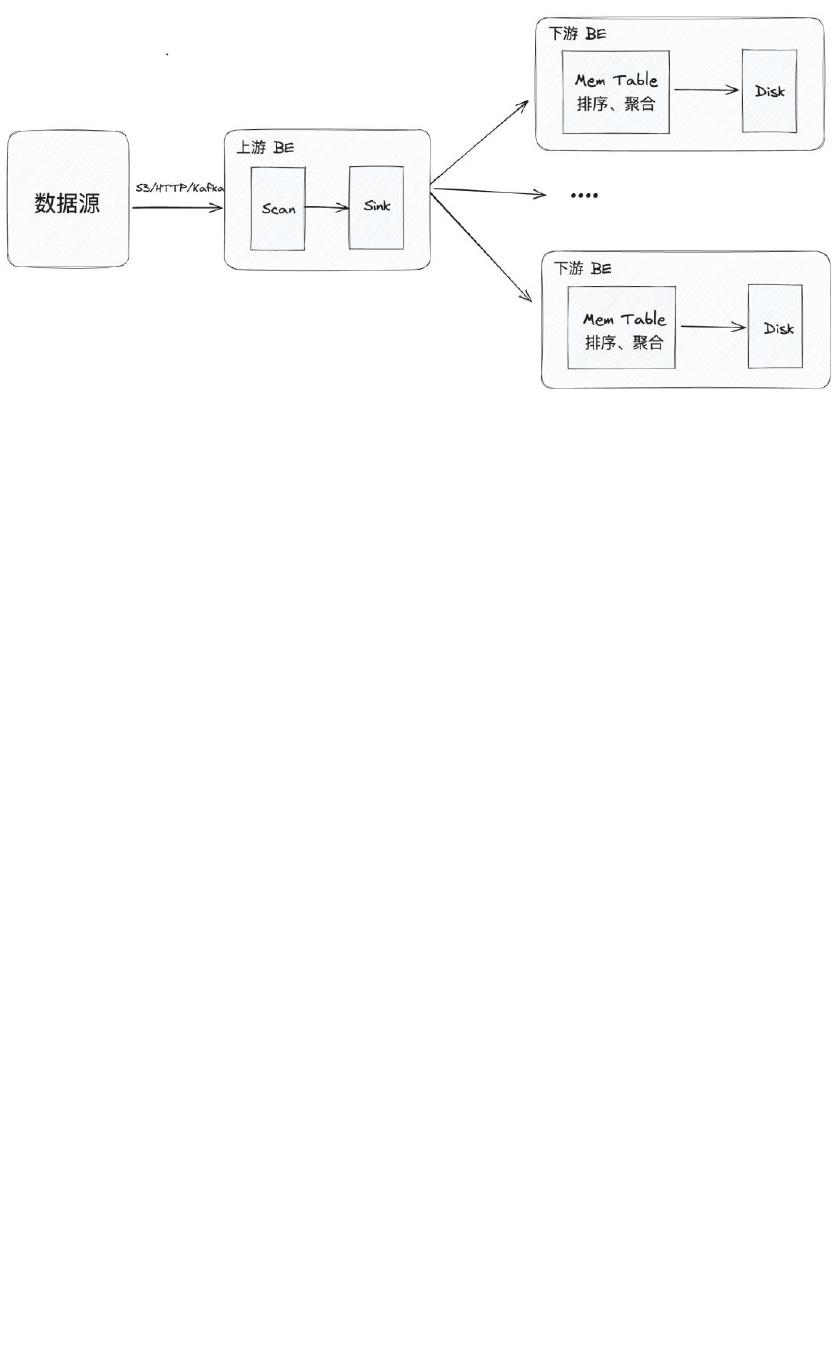
而我们在实际的数据导入过程中,可能会出现以下问题:
• 因上游 BE 跟下游 BE 之间的 RPC 采用 Ping-Pong 的模式,
即下游 BE 一个请求处理完成并回复到上游 BE 后,上游 BE
才会发送下一个请求。如果下游 BE 在 MemTable 的处理过程
中消耗了较长的时间,那么上游 BE 将会等待 RPC 返回的时间
也会变长,这就会影响到数据传输的效率。
• 当对多副本的表导入数据时,需要在每个副本上重复执行 Mem
Table 的处理过程。然而,这种方式使每个副本所在节点都会消
耗一定的内存和 CPU 资源,不仅如此,冗长的处理流程也会影
响执行效率。
为解决以上问题,我们在刚刚发布不久 Apache Doris 2.0 版本中(h
ttps://github.com/apache/doris/tree/2.0.1-rc04 ),对导入过程中
MemTable 的攒批、排序和落盘等流程进行优化,提高了上下游之间
数据传输的效率。此外我们在新版本中还提供 “单副本导入” 的数据
of 10
免费下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

评论