

1



Prometheus一条告警是怎么触发的 - 爱可生开源社区 - OSCHINA - 中文开源技术交流社区.pdf
5墨值下载
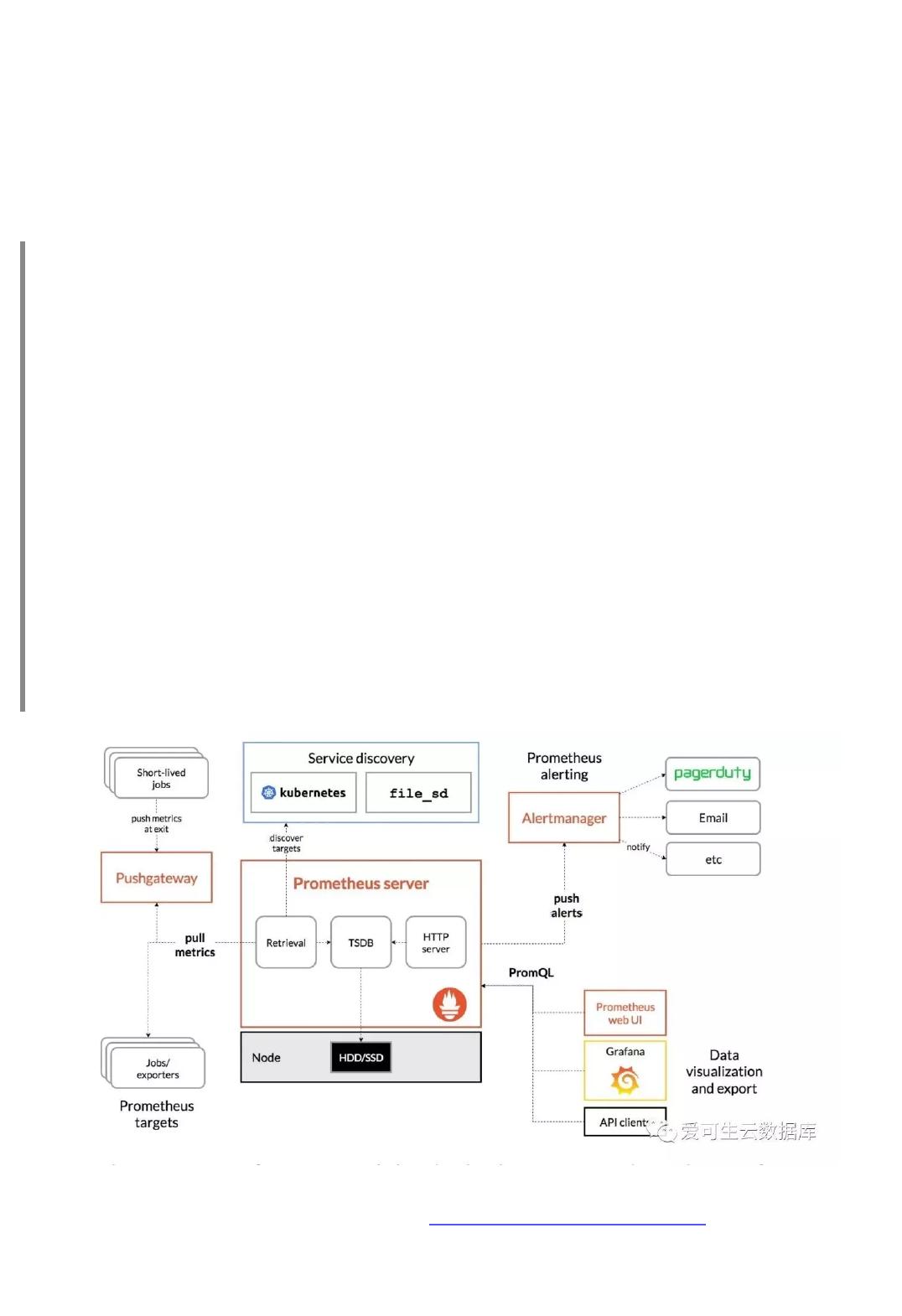

今天我们聊一些Prometheus几个有意思的特性,这些特性能帮助大家更深入的了解Prometheus的一条告警是
怎么触发的;本文提纲如下:
监控采集,计算和告警
告警分组,抑制和静默
告警延时
第一节 监控采集、计算和告警
Prometheus以scrape_interval(默认为1m)规则周期,从监控目标上收集信息。其中scrape_interval可以基
于全局或基于单个metric定义;然后将监控信息持久存储在其本地存储上。
Prometheus以evaluation_interval(默认为1m)另一个独立的规则周期,对告警规则做定期计算。其中
evaluation_interval只有全局值;然后更新告警状态。
其中包含三种告警状态:
inactive:没有触发阈值
pending:已触发阈值但未满足告警持续时间
firing:已触发阈值且满足告警持续时间
举一个例子,阈值告警的配置如下:
groups:
- name: example
rules:
- alert: mysql_uptime
expr: mysql:server_status:uptime < 30
for: 10s
labels:
level: "CRITICAL"
annotations:
detail: 数据库运行时间
收集到的mysql_uptime>=30,告警状态为inactive
收集到的mysql_uptime<30,且持续时间小于10s,告警状态为pending
收集到的mysql_uptime<30,且持续时间大于10s,告警状态为firing
of 10
5墨值下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

评论