




SadTalker Learning Realistic 3D Motion Coefficients for Stylized Audio-Driven.pdf
100墨值下载
SadTalker: Learning Realistic 3D Motion Coefficients for Stylized Audio-Driven
Single Image Talking Face Animation
Wenxuan Zhang
*
, 1
Xiaodong Cun
*
, 2
Xuan Wang
3
Yong Zhang
2
Xi Shen
2
Yu Guo
1
Ying Shan
2
Fei Wang
† , 1
1
Xi’an Jiaotong University
2
Tencent AI Lab
3
Ant Group
https://sadtalker.github.io
15 45
133
65
Input Image
Style 1
Style 2
Style 3
Input Audio
27
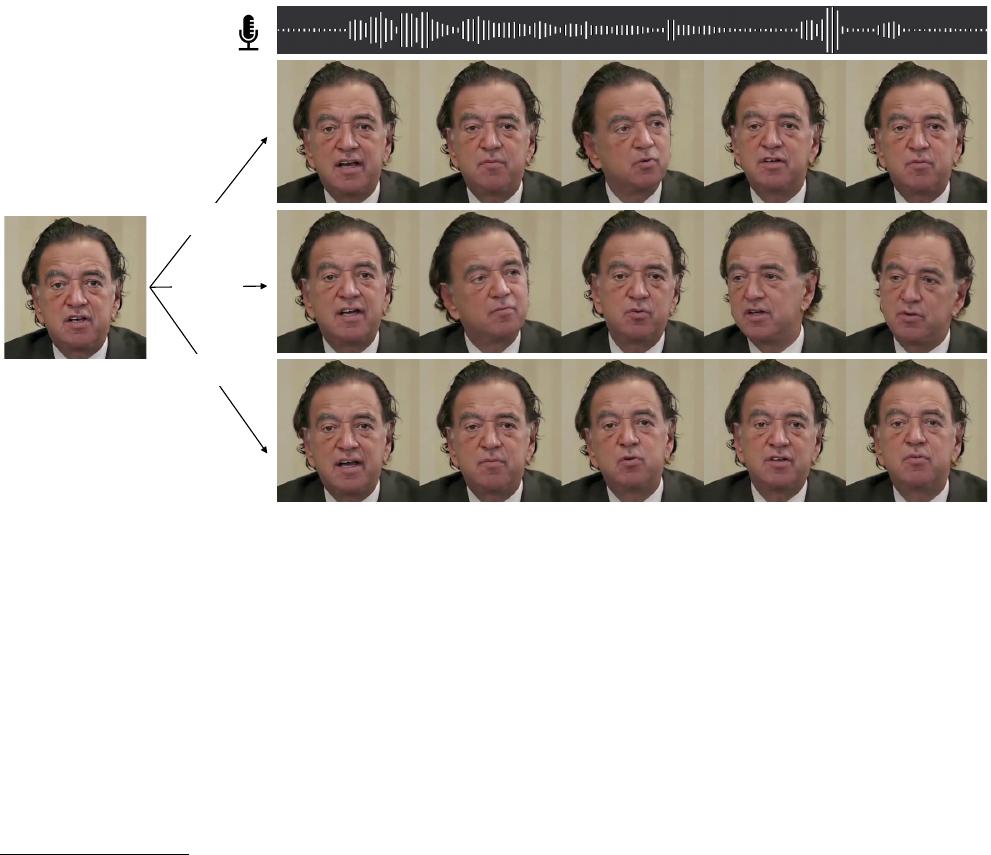
Figure 1. The proposed SadTalker produces diverse, realistic, synchronized talking videos from an input audio and a single reference image.
Abstract
Generating talking head videos through a face image
and a piece of speech audio still contains many challenges.
i.e., unnatural head movement, distorted expression, and
identity modification. We argue that these issues are mainly
because of learning from the coupled 2D motion fields. On
the other hand, explicitly using 3D information also suffers
problems of stiff expression and incoherent video. We present
SadTalker, which generates 3D motion coefficients (head
pose, expression) of the 3DMM from audio and implicitly
modulates a novel 3D-aware face render for talking head
*
Equal Contribution
†
Corresponding Author
generation. To learn the realistic motion coefficients, we
explicitly model the connections between audio and differ-
ent types of motion coefficients individually. Precisely, we
present ExpNet to learn the accurate facial expression from
audio by distilling both coefficients and 3D-rendered faces.
As for the head pose, we design PoseVAE via a conditional
VAE to synthesize head motion in different styles. Finally,
the generated 3D motion coefficients are mapped to the un-
supervised 3D keypoints space of the proposed face render,
and synthesize the final video. We conducted extensive ex-
periments to demonstrate the superiority of our method in
terms of motion and video quality.
1
arXiv:2211.12194v2 [cs.CV] 13 Mar 2023
1. Introduction
Animating a static portrait image with speech audio is
a challenging task and has many important applications
in the fields of digital human creation, video conferences,
etc. Previous works mainly focus on generating lip mo-
tion [2, 3, 30, 31, 51] since it has a strong connection with
speech. Recent works also aim to generate a realistic talking
face video containing other related motions, e.g., head pose.
Their methods mainly introduce 2D motion fields by land-
marks [52] and latent warping [39, 40]. However, the quality
of the generated videos is still unnatural and restricted by
the preference pose [17, 51], month blur [30], identity modi-
fication [39, 40], and distorted face [39,40, 49].
Generating a natural-looking talking head video contains
many challenges since the connections between audio and
different motions are different. i.e., the lip movement has
the strongest connection with audio, but audio can be talked
via different head poses and eye blink. Thus, previous facial
landmark-based methods [2, 52] and 2D flow-based audio to
expression networks [39,40] may generate the distorted face
since the head motion and expression are not fully disentan-
gled in their representation. Another popular type of method
is the latent-based face animation [3, 17, 30, 51]. Their meth-
ods mainly focus on the specific kind of motions in talking
face animation and struggle to synthesize high-quality video.
Our observation is that the 3D facial model contains a highly
decoupled representation and can be used to learn each type
of motion individually. Although a similar observation has
been discussed in [49], their methods also generate inaccu-
rate expressions and unnatural motion sequences.
From the above observation, we propose SadTalker, a
S
tylized
A
udio-
D
riven
Talk
ing-head video generation sys-
tem through implicit 3D coefficient modulation. To achieve
this goal, we consider the motion coefficients of the 3DMM
as the intermediate representation and divide our task into
two major components. On the one hand, we aim to generate
the realistic motion coefficients (e.g., head pose, lip motion,
and eye blink) from audio and learn each motion individu-
ally to reduce the uncertainty. For expression, we design a
novel audio to expression coefficient network by distilling
the coefficients from the lip motion only coefficients from
[30] and the perceptual losses (lip-reading loss [1], facial
landmark loss) on the reconstructed rendered 3d face [5].
For the stylized head pose, a conditional VAE [6] is used
to model the diversity and life-like head motion by learning
the residual of the given pose. After generating the realistic
3DMM coefficients, we drive the source image through a
novel 3D-aware face render. Inspired by face-vid2vid [42],
we learn a mapping between the explicit 3DMM coefficients
and the domain of the unsupervised 3D keypoint. Then, the
warping fields are generated through the unsupervised 3D
keypoints of source and driving and it warps the reference im-
age to generate the final videos. We train each sub-network
of expression generation, head poses generation and face
renderer individually and our system can be inferred in an
end-to-end style. As for the experiments, several metrics
show the advantage of our method in terms of video and
motion methods.
The main contribution of this paper can be summarized
as:
•
We present SadTalker, a novel system for a stylized
audio-driven single image talking face animation using
the generated realistic 3D motion coefficients.
•
To learn the realistic 3D motion coefficient of the
3DMM model from audio, ExpNet and PoseVAE are
presented individually.
•
A novel semantic-disentangled and 3D-aware face ren-
der is proposed to produce a realistic talking head video.
•
Experiments show that our method achieves state-of-
the-art performance in terms of motion synchronization
and video quality.
2. Related Work
Audio-driven Single Image Talking Face Generation.
Early works [3, 30, 31] mainly focus on producing accu-
rate lip motion with a perception discriminator. Since the
real videos contain many different motions, ATVGnet [2]
uses the facial landmark as the intermediate representation
to generate the video frames. A similar approach has been
proposed by MakeItTalk [52], differently, it disentangles the
content and speaker information from the input audio signal.
Since facial landmarks are still a highly coupled space, gen-
erating the talking head in the disentangled space is also pop-
ular recently. PC-AVS [51] disentangles the head pose and
expression using implicit latent code. However, it can only
produce low-resolution image and need the control signal
from another video. Audio2Head [39] and Wang et al. [40]
get inspiration from the video-driven method [36] to produce
the talking-head face. However, these head movements are
still not vivid and produce distorted faces with inaccurate
identities. Although there are some previous works [33, 49]
use 3DMMs as an intermediate representation, their method
still faces the problem of inaccurate expressions [33] and
obvious artifacts [49].
Audio-driven Video Portrait.
Our task is also related to
visual dubbing, which aims to edit a portrait video through
audio. Different from audio-driven single image talking face
generation, this task is typically required to be trained and
edited on the specific video. Following previous work of deep
video portrait [19], these methods utilize 3DMM informa-
tion for face reconstruction and animation. AudioDVP [45],
NVP [38], AD-NeRF [11] learn to reenact the expression to
2
of 14
100墨值下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

评论