




SDFusion.pdf
100墨值下载
SDFusion: Multimodal 3D Shape Completion, Reconstruction, and Generation
Yen-Chi Cheng
1
Hsin-Ying Lee
2
Sergey Tulyakov
2
Alexander Schwing
1∗
Liangyan Gui
1∗
1
University of Illinois Urbana-Champaign
2
Snap Research
{yenchic3,aschwing,lgui}@illinois.edu {hlee5,stulyakov}@snap.com
https://yccyenchicheng.github.io/SDFusion/
Shape
Completion
Missing
3D
Recon.
Multi
-condition
Text-guided Colorization
Text
-guided
Generation
a rocking chair square table, curved legs
a chair with arms
condition
strength
Text-guided
Completion
ice cream summer house Japanese castle
square couch with shelf table with net
table tennis tablewooden tablecheesecake
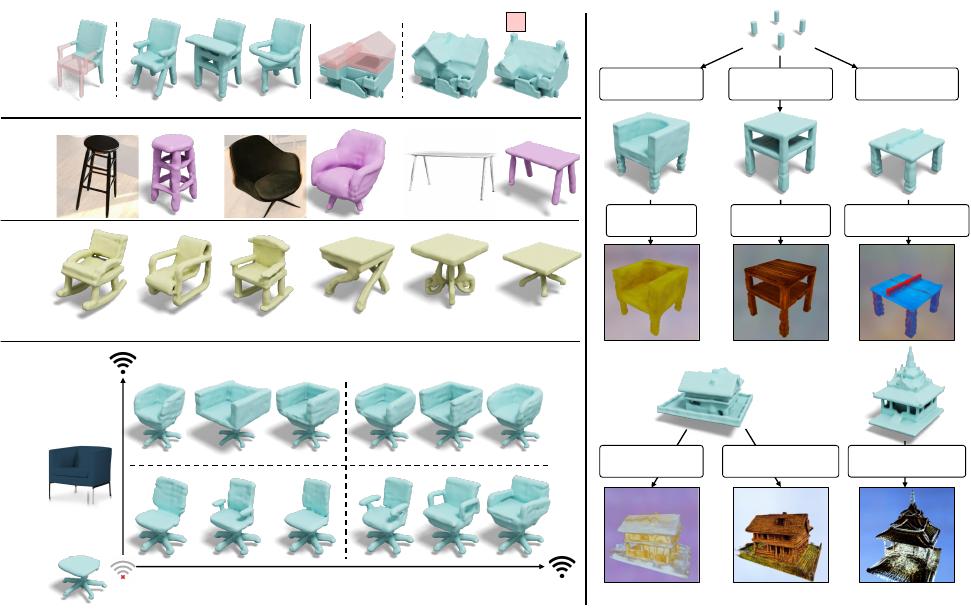
Figure 1. Applications of SDFusion. The proposed diffusion-based model enables various applications. (left) SDFusion can generate
shapes conditioned on different input modalities, including partial shapes, images, and text. SDFusion can even jointly handle multiple
conditioning modalities while controlling the strength for each of them. (right) We leverage pretrained 2D models to texture 3D shapes
generated by SDFusion.
Abstract
In this work, we present a novel framework built to sim-
plify 3D asset generation for amateur users. To enable in-
teractive generation, our method supports a variety of in-
put modalities that can be easily provided by a human, in-
cluding images, text, partially observed shapes and com-
binations of these, further allowing to adjust the strength
of each input. At the core of our approach is an encoder-
decoder, compressing 3D shapes into a compact latent rep-
resentation, upon which a diffusion model is learned. To
enable a variety of multi-modal inputs, we employ task-
specific encoders with dropout followed by a cross-attention
mechanism. Due to its flexibility, our model naturally sup-
ports a variety of tasks, outperforming prior works on shape
completion, image-based 3D reconstruction, and text-to-
3D. Most interestingly, our model can combine all these
tasks into one swiss-army-knife tool, enabling the user to
perform shape generation using incomplete shapes, images,
and textual descriptions at the same time, providing the rel-
ative weights for each input and facilitating interactivity.
Despite our approach being shape-only, we further show an
efficient method to texture the generated shape using large-
scale text-to-image models.
1
arXiv:2212.04493v2 [cs.CV] 22 Mar 2023
1. Introduction
Generating 3D assets is a cornerstone of immersive aug-
mented/virtual reality experiences. Without realistic and di-
verse objects, virtual worlds will look void and engagement
will remain low. Despite this need, manually creating and
editing 3D assets is a notoriously difficult task, requiring
creativity, 3D design skills, and access to sophisticated soft-
ware with a very steep learning curve. This makes 3D asset
creation inaccessible for inexperienced users. Yet, in many
cases, such as interior design, users more often than not
have a reasonably good understanding of what they want to
create. In those cases, an image or a rough sketch is some-
times accompanied by text indicating details of the asset,
which are hard to express graphically for an amateur.
Due to this need, it is not surprising that democratizing
the 3D content creation process has become an active re-
search area. Conventional 3D generative models require
direct 3D supervision in the form of point clouds [2, 21],
signed distance functions (SDFs) [9, 25], voxels [42, 47],
etc. Recently, first efforts have been made to explore the
learning of 3D geometry from multi-view supervision with
known camera poses by incorporating inductive biases via
neural rendering techniques [5, 6, 14, 37, 52]. While com-
pelling results have been demonstrated, training is often
very time-consuming and ignores available 3D data that can
be used to obtain good shape priors. We foresee an ideal
collaborative paradigm for generative methods where mod-
els trained on 3D data provide detailed and accurate geom-
etry, while models trained on 2D data provide diverse ap-
pearances. A first proof of concept is shown in Figure 1.
In our pursuit of flexible and high-quality 3D shape gen-
eration, we introduce SDFusion, a diffusion-based genera-
tive model with a signed distance function (SDF) under the
hood, acting as our 3D representation. Compared to other
3D representations, SDFs are known to represent well high-
resolution shapes with arbitrary topology [9, 18, 23, 30].
However, 3D representations are infamous for demanding
high computational resources, limiting most existing 3D
generative models to voxel grids of 32
3
resolution and point
clouds of 2K points. To side-step this issue, we first uti-
lize an auto-encoder to compress 3D shapes into a more
compact low-dimensional representation. Because of this,
SDFusion can easily scale up to a 128
3
resolution. To
learn the probability distribution over the introduced la-
tent space, we leverage diffusion models, which have re-
cently been used with great success in various 2D genera-
tion tasks [4,19,22,26,35,40]. Furthermore, we adopt task-
specific encoders and a cross-attention [34] mechanism to
support multiple conditioning inputs, and apply classifier-
free guidance [17] to enable flexible conditioning usage.
Because of these strategies, SDFusion can not only use a va-
riety of conditions from multiple modalities, but also adjust
their importance weight, as shown in Figure 1. Compared
to a recently proposed autoregressive model [25] that also
adopts an encoded latent space, SDFusion achieves supe-
rior sample quality, while offering more flexibility to handle
multiple conditions and, at the same time, features reduced
memory usage. With SDFusion, we study the interplay be-
tween models trained on 2D and 3D data. Given 3D shapes
generated by SDFusion, we take advantage of an off-the-
shelf 2D diffusion model [34], neural rendering [24], and
score distillation sampling [31] to texture the shapes given
text descriptions as conditional variables.
We conduct extensive experiments on the ShapeNet [7],
BuildingNet [38], and Pix3D [43] datasets. We show that
SDFusion quantitatively and qualitatively outperforms prior
work in shape completion, 3D reconstruction from images,
and text-to-shape tasks. We further demonstrate the capa-
bility of jointly controlling the generative model via multi-
ple conditioning modalities, the flexibility of adjusting rela-
tive weight among modalities, and the ability to texture 3D
shapes given textual descriptions, as shown in Figure 1.
We summarize the main contributions as follows:
• We propose SDFusion, a diffusion-based 3D genera-
tive model which uses a signed distance function as its
3D representation and a latent space for diffusion.
• SDFusion enables conditional generation with multi-
ple modalities, and provides flexible usage by adjust-
ing the weight among modalities.
• We demonstrate a pipeline to synthesize textured 3D
objects benefiting from an interplay between 2D and
3D generative models.
2. Related Work
3D Generative Models. Different from 2D images, it is
less clear how to effectively represent 3D data. Indeed,
various representations with different pros and cons have
been explored, particularly when considering 3D genera-
tive models. For instance, 3D generative models have been
explored for point clouds [2, 21], voxel grids [20, 42, 47],
meshes [51], signed distance functions (SDFs) [9, 11, 25],
etc. In this work, we aim to generate an SDF. Compared
to other representations, SDFs exhibit a reasonable trade-
off regarding expressivity, memory efficiency, and direct
applicability to downstream tasks. Moreover, conditioning
3D generation of SDFs on different modalities further en-
ables many applications, including shape completion, 3D
reconstruction from images, 3D generation from text, etc.
The proposed framework can handle these tasks in a single
model which makes it different from prior work.
Recently, thanks to the advancement of neural render-
ing [24], a new stream of research has emerged to learn
3D generation and manipulation from only 2D supervi-
sion [1, 5, 6, 28, 37, 39, 41, 49]. We believe the interplay
between two streams of work is promising in the foresee-
able future.
2
of 10
100墨值下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

评论