




openGauss鲲鹏多核优化解读.docx
免费下载
openGauss
鲲鹏多核优化解读
从集成电路诞生到现在,
CPU
主要经历了三个发展阶段,第一阶段是提升
CPU
的主频。
在集成电路问世
6
年后,摩尔就提出了摩尔定律,预言了芯片上集成的晶体管数量将每两年翻
一番。摩尔定律不是自然定律,但半导体芯片发展的事实证明,摩尔的预言是准确的。芯片的
技术进步主要受益于两个方面:制程变小和硅片变大。但当芯片工艺规格小于
7nm
的时候,
就会出现量子隧穿效应,芯片量产变得困难,导致制造成本急剧上升。
第二阶段是增加核数,在单核
CPU
频率无法继续增加的情况下,可以通过增加
CPU
的核
数来提升算力。但
CPU
只是逻辑计算单元,必须把内存中的程序和数据加载到
CPU
中才能进
行计算。所有
CPU
核都是通过共享一个北桥来读取内存,随着核数的快速发展,北桥在响应时
间上的性能瓶颈越来越明显。
第三阶段是
CPU
核
NUMA
化,为了解决北桥中读取内存的部分即内存控制器的瓶颈,可
以把内存平均分配在各个
die
上,但这导致了不同
CPU
核访问不同内存时延的非对称性。原因
是虽然内存直接
attach
在
CPU
上,但当
CPU
访问自身直接
attach
内存对应的物理地址时
(即
Local Access
),响应时间较短。如果访问其他
CPU attach
的内存数据(即
Remote
Access
),就需要通过
inter-connect
通道访问,响应时间就会变慢。这也是
NUMA
(
Non-
Uniform Memory Access
)名称的由来。在
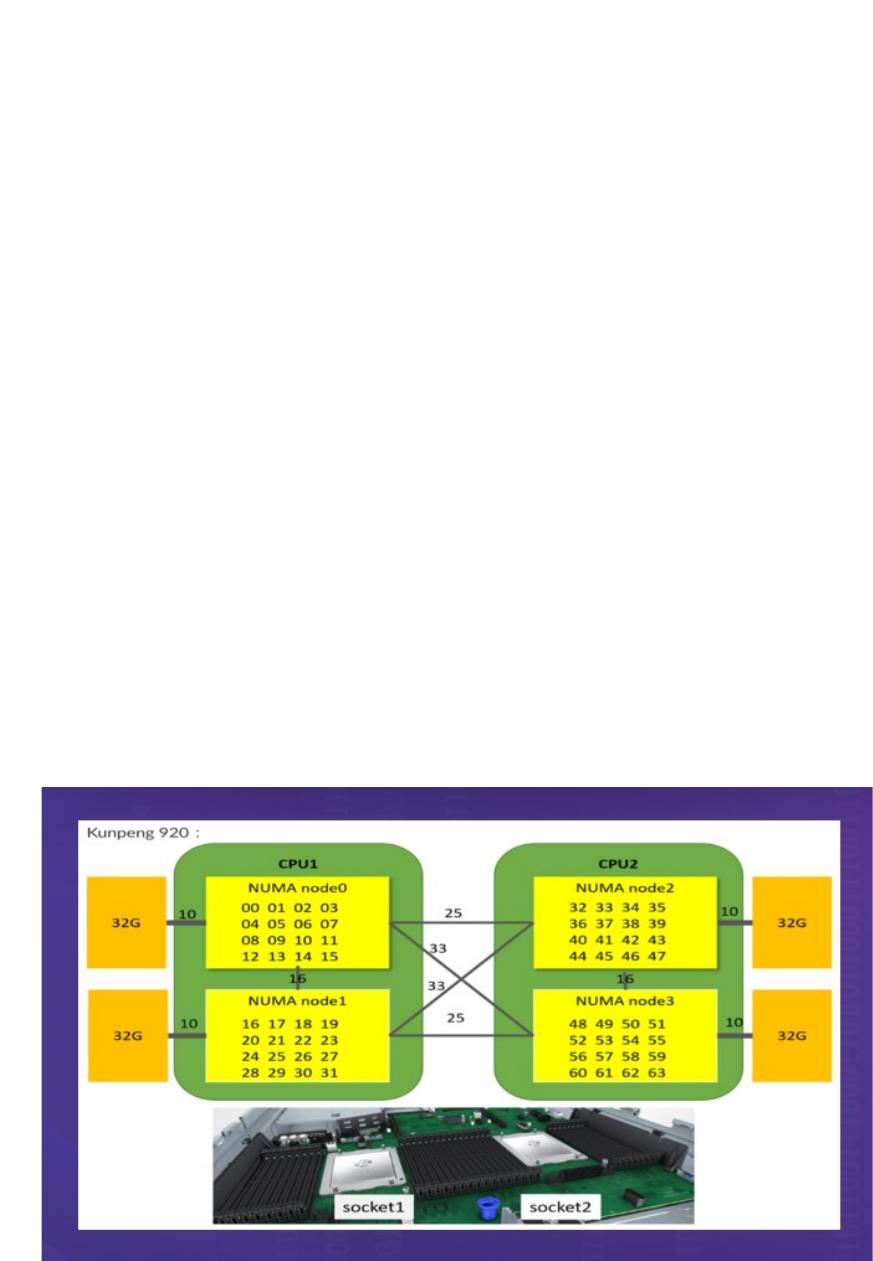
NUMA
架构下,
NUMA Node
的处理器和内存
块的物理距离被称为
NUMA
距离,通过
numactl
工具可以查询到
CPU
访问的距离信息。以鲲
鹏服务器为例,图示如下:
CPU NUMA
化给服务器带来澎湃算力的同时,也给软件开发带来了很大挑战。从整个
IT
软件栈来看,首先需要对
NUMA
化进行支持的是操作系统,现在通用的企业操作系统是
Linux
操作系统。在
NUMA
出现后,
Linux
也提供了针对性的优化方案,优先尝试在请求线程当前所
处的
CPU
的
Local
内存上分配空间。如果
local
内存不足,优先淘汰
local
内存中无用的
Page
。但
Linux
提供的
NUMA
内存使用方式并不适合数据库,因为数据库是一个数据密集型
高并发的应用,内部有很多的内核数据结构,这些数据结构既会被本核的
CPU
访问,也会被远
程的
CPU
核访问。为了提高数据访问性能,数据库还有自己的共享数据缓冲区,这些共享缓冲
区是随机的被各个
CPU
核上的业务线程访问。从
IT
软件栈来看,数据库是处于企业应用的核
心位置,很多应用后台都有一个数据库,数据库的性能决定了很多应用的整体吞吐量。因此如
果数据库无法在
NUMA
下发挥最大性能,实现随着核数的增加,性能呈现一定的线性比,那么
CPU NUMA
虽然算力很丰富,但可能没有企业愿意买单。
反过来,
NUMA
作为
CPU
发展的一种必然趋势,一款企业级的数据库如果不能适应硬件
的 发展,在企业的数据库选型中,这款数据库也将被淘汰出局。
openGauss
作为一款开源关系型数据库管理系统,针对
CPU NUMA
化的硬件发展趋势,
从并发控制算法,内核数据结构,数据访问等全方位进行了优化,释放处理器多核算力,实现
两路鲲鹏
128
核场景
150
万
tpmC
性能。本文深度解读
openGauss
在鲲鹏服务器上的
NUMA
多核优化技术,同时也为其他数据库在鲲鹏上进行性能优化提供借鉴和参考,面向数据
库性能优化的数据库开发人员。
1 openGauss
鲲鹏多核优化解读
of 7
免费下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

评论