




Generative Semantic Segmentation.pdf
50墨值下载
Generative Semantic Segmentation
Jiaqi Chen
1
Jiachen Lu
1
Xiatian Zhu
2
Li Zhang
1
*
1
Fudan University
2
University of Surrey
https://github.com/fudan-zvg/GSS
Abstract
We present
Generative Semantic Segmentation
(GSS),
a generative learning approach for semantic segmenta-
tion. Uniquely, we cast semantic segmentation as an
image-
conditioned mask generation problem
. This is achieved by
replacing the conventional per-pixel discriminative learn-
ing with a latent prior learning process. Specifically, we
model the variational posterior distribution of latent vari-
ables given the segmentation mask. To that end, the seg-
mentation mask is expressed with a special type of image
(dubbed as maskige). This posterior distribution allows to
generate segmentation masks unconditionally. To achieve
semantic segmentation on a given image, we further intro-
duce a conditioning network. It is optimized by minimizing
the divergence between the posterior distribution of maskige
(i.e. segmentation masks) and the latent prior distribution
of input training images. Extensive experiments on standard
benchmarks show that our GSS can perform competitively to
prior art alternatives in the standard semantic segmentation
setting, whilst achieving a new state of the art in the more
challenging cross-domain setting.
1. Introduction
The objective of semantic segmentation is to predict a
label for every single pixel of an input image [32]. Condi-
tioning on each pixel’s observation, existing segmentation
methods [4,9,52,58] naturally adopt the discriminative learn-
ing paradigm, along with dedicated efforts on integrating
task prior knowledge (e.g., spatial correlation) [9, 23, 47, 58].
For example, existing methods [4, 52, 58] typically use a
linear projection to optimize the log-likelihood classification
for each pixel. Despite the claim of subverting per-pixel clas-
sification, the bipartite matching-based semantic segmenta-
tion [8, 9] still cannot avoid the per-pixel max log-likelihood.
In this paper, we introduce a new approach,
Generative
Semantic Segmentation
(GSS), that formulates semantic
*
Li Zhang (lizhangfd@fudan.edu.cn) is the corresponding author with
School of Data Science, Fudan University.
learning
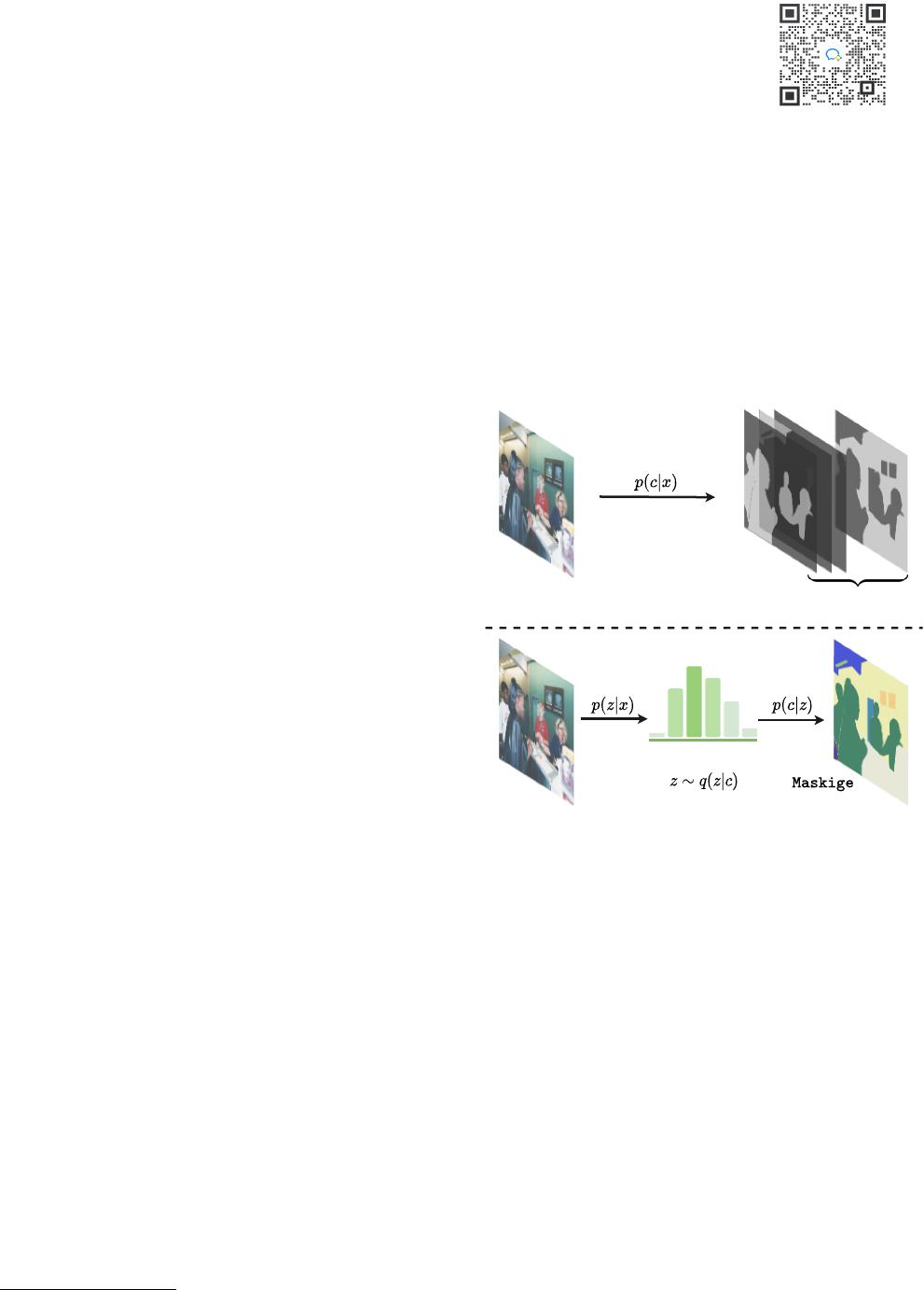
Posterior
learning
Discriminative
(b) Generative semantic segmentation
(a) Discriminative semantic segmentation
Prior learning
classesN
Mask
Latent distribution
Figure 1. Schematic comparison between (
a
) conventional discrim-
inative learning and (
b
) our generative learning based model for
semantic segmentation. Our GSS introduces a latent variable
z
and, given the segmentation mask
c
, it learns the posterior distri-
bution of
z
subject to the reconstruction constraint. Then, we train
a conditioning network to model the prior of
z
by aligning with
the corresponding posterior distribution. This formulation can thus
generate the segmentation mask for an input image.
segmentation as an image-conditioned mask generation prob-
lem. This conceptually differs from the conventional for-
mulation of discriminative per-pixel classification learning,
based on the log-likelihood of a conditional probability (i.e.
the classification probability of image pixels). Taking the
manner of image generation instead [24,45], we generate the
whole segmentation masks with an auxiliary latent variable
distribution introduced. This formulation is not only simple
and more task-agnostic, but also facilitates the exploitation
of off-the-shelf big generative models (e.g. DALL
·
E [40]
trained by 3 billion iterations on a 300 million open-image
dataset, far beyond both the data scale and training cost of
semantic segmentation).
1
arXiv:2303.11316v1 [cs.CV] 20 Mar 2023

However, achieving segmentation segmentation in a
generic generation framework (e.g. the Transformer archi-
tecture [15]) is non-trivial due to drastically different data
format. To address this obstacle, we propose a notion of
maskige
that expresses the segmentation mask in the RGB
image form. This enables the use of a pretrained latent
posterior distribution (e.g. VQVAE [40]) of existing gener-
ative models. Our model takes a two-stage optimization:
(i)
Learning the posterior distribution of the latent variables
conditioned on the semantic segmentation masks so that
the latent variables can simulate the target segmentation
masks; To achieve this, we introduce an fixed pre-trained
VQVAE [40] and a couple of lightweight transformation
modules, which can be trained with minimal cost, or they
can be manually set up without requiring any additional
training. In either case, the process is efficient and does
not add significant overhead to the overall optimization.
(ii)
Minimizing the distance between the posterior distribution
and the prior distribution of the latent variables given input
training images and their masks, enabling to condition the
generation of semantic masks on the input images. This can
be realized by a generic encoder-decoder style architecture
(e.g. a Transformer).
We summarize the contributions as follows.
(i)
We pro-
pose a
Generative Semantic Segmentation
approach that re-
formulates semantic segmentation as an image-conditioned
mask generation problem. This represents a conceptual shift
from conventional discriminative learning based paradigm.
(ii)
We realize a GSS model in an established conditional
image generation framework, with minimal need for task-
specific architecture and loss function modifications while
fully leveraging the knowledge of off-the-shelf generative
models.
(iii)
Extensive experiments on several semantic
segmentation benchmarks show that our GSS is competitive
with prior art models in the standard setting, whilst achieving
a new state of the art in the more challenging and practical
cross-domain setting (e.g. MSeg [26]).
2. Related work
Semantic segmentation
Since the inception of FCN [32],
semantic segmentation have flourished by various deep neu-
ral networks with ability to classify each pixel. The follow-
up efforts then shift to improve the limited receptive field of
these models. For example, PSPNet [57] and DeepLabV2 [3]
aggregate multi-scale context between convolution layers.
Sequentially, Nonlocal [49], CCNet [21], and DGMN [56]
integrate the attention mechanism in the convolution struc-
ture. Later on, Transformer-based methods (e.g. SETR [58]
and Segformer [52]) are proposed following the introduction
of Vision Transformers. More recently, MaskFormer [9]
and Mask2Former [8] realize semantic segmentation with
bipartite matching. Commonly, all the methods adopt the
discriminative pixel-wise classification learning paradigm.
This is in contrast to our generative semantic segmentation.
Image generation
In parallel, generative models [15, 40]
also excel. They are often optimized in a two-stage train-
ing process: (1) Learning data representation in the first
stage and (2) building a probabilistic model of the encod-
ing in the second stage. For learning data representation,
VAE [24] reformulates the autoencoder by variational in-
ference. GAN [19] plays a zero-sum game. VQVAE [45]
extends the image representation learning to discrete spaces,
making it possible for language-image cross-model genera-
tion. [27] replaces element-wise errors of VAE with feature-
wise errors to capture data distribution. For probabilistic
model learning, some works [14, 41, 51] use flow for joint
probability learning. Leveraging the Transformers to model
the composition between condition and images, Esser et
al. [15] demonstrate the significance of data representation
(i.e. the first stage result) for the challenging high-resolution
image synthesis, obtained at high computational cost. This
result is inspiring to this work in the sense that the diverse
and rich knowledge about data representation achieved in
the first stage could be transferable across more tasks such
as semantic segmentation.
Generative models for visual perception
Image-to-image
translation made one of the earliest attempts in generative
segmentation, with far less success in performance [22].
Some good results were achieved in limited scenarios such as
face parts segmentation and Chest X-ray segmentation [28].
Replacing the discriminative classifier with a generative
Gaussian Mixture model, GMMSeg [29] is claimed as gen-
erative segmentation, but the most is still of discriminative
modeling. The promising performance of Pix2Seq [7] on
several vision tasks leads to the prevalence of sequence-to-
sequence task-agnostic vision frameworks. For example,
Unified-I/O [33] supports a variety of vision tasks within
a single model by seqentializing each task to sentences.
Pix2Seq-D [6] deploys a hierarchical VAE (i.e. diffusion
model) to generate panoptic segmentation masks. This
method is inefficient due to the need for iterative denoising.
UViM [25] realizes its generative panoptic segmentation by
introducing latent variable conditioned on input images. It
is also computationally heavy due to the need for model
training from scratch. To address these issues, we introduce
a notion of
maskige
for expressing segmentation masks in
the form of RGB images, enabling the adopt of off-the-shelf
data representation models (e.g. VGVAE) already pretrained
on vast diverse imagery. This finally allows for generative
segmentation model training as efficiently as conventional
discriminative counterparts.
2
of 21
50墨值下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

评论