




统计机器学习(斯坦福大学讲义)1-12(全).pdf
50墨值下载
CS229 Lecture notes
Andrew Ng
Supervised learni ng
Let’s start by talking about a few examples of supervised learning problems.
Suppose we have a dataset giving the living areas and prices of 47 houses
from Portland, Oregon:
Living area (feet
2
)
Price (1000$s)
2104 400
1600 330
2400 369
1416
232
3000 540
.
.
.
.
.
.
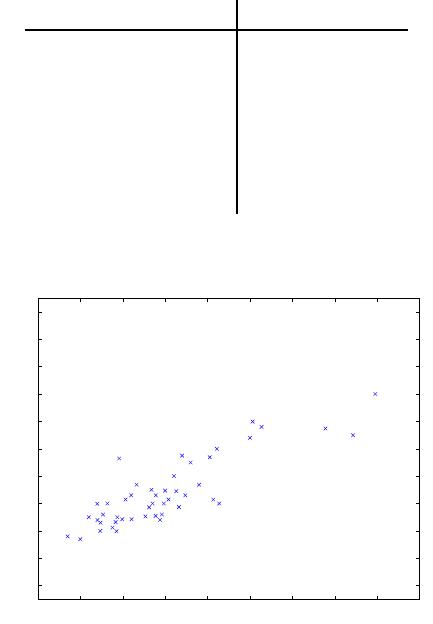
We can plot t his data:
500 1000 1500 2000 2500 3000 3500 4000 4500 5000
0
100
200
300
400
500
600
700
800
900
1000
housing prices
square feet
price (in $1000)
Given data like this, how can we learn to predict the prices of ot her houses
in Portland, as a function of the size of their living areas?
1
CS229 Fall 2012 2
To establish notation for future use, we’ll use x
(i)
to denote the “ input”
variables (living a r ea in this example), also called input features, and y
(i)
to denote the “output” o r target variable that we are trying to predict
(price). A pair (x
(i)
, y
(i)
) is called a training example, and the data set
that we’ll be using to learn—a list of m training examples {(x
(i)
, y
(i)
); i =
1, . . . , m}—is called a training set. Note that the superscript “(i)” in the
notation is simply an index int o the training set, and has nothing to do with
exp onentiation. We will also use X denote the space of input values, and Y
the space of output values. In this example, X = Y = R.
To describe the supervised learning problem slightly more formally, our
goal is, given a training set, to learn a function h : X 7→ Y so that h(x) is a
“good” predictor for the corresponding value of y. For historical reasons, this
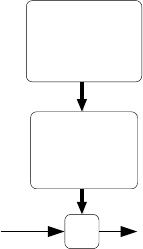
function h is called a hypothesis. Seen pictorially, the process is therefore
like this:
Training
set
house.)
(living area of
Learning
algorithm
h
predicted yx
(predicted price)
of house)
When the target variable t hat we’re trying to predict is continuous, such
as in our housing example, we call the learning problem a regression prob-
lem. When y can take on only a small number of discrete values (such as
if, given the living area, we wanted t o predict if a dwelling is a house or an
apartment, say), we call it a classification problem.
of 142
50墨值下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

评论