




Implicit Diffusion Models for Continuous Super-Resolution.pdf
50墨值下载
Implicit Diffusion Models for Continuous Super-Resolution
Sicheng Gao
1
*
, Xuhui Liu
1
*
, Bohan Zeng
1
*
, Sheng Xu
1
, Yanjing Li
1
, Xiaoyan Luo
1
Jianzhuang Liu
2
, Xiantong Zhen
3
, Baochang Zhang
1,4†
1
Beihang University
2
Shenzhen Institute of Advanced Technology, Shenzhen, China
3
United Imaging
4
Zhongguancun Laboratory, Beijing, China
Abstract
modulates the proportion of the LR information and generated
features in the final output, which enables the model to accom-
modate the continuous-resolution requirement. Extensive ex-
periments validate the effectiveness of our IDM and demon-
strate its superior performance over prior arts. The source
code will be available at https://github.com/Ree1s/
IDM
Image super-resolution (SR) has attracted increasing atten-
tion due to its widespread applications. However, current SR
methods generally suffer from over-smoothing and artifacts,
and most work only with fixed magnifications. This paper in-
troduces an Implicit Diffusion Model (IDM) for high-fidelity
continuous image super-resolution. IDM integrates an im-
plicit neural representation and a denoising diffusion model
in a unified end-to-end framework, where the implicit neu-
ral representation is adopted in the decoding process to learn
continuous-resolution representation. Furthermore, we design
a scale-adaptive conditioning mechanism that consists of a
low-resolution (LR) conditioning network and a scaling fac-
tor. The scaling factor regulates the resolution and accordingly
.
1. Introduction
Image super-resolution (SR) refers to the task of generating
high-resolution (HR) images from given low-resolution (LR)
images. It has attracted increasing attention due to its far-
reaching applications, such as video restoration, photography,
and accelerating data transmission. While significant progress
has been achieved recently, existing SR models predominantly
suffer from suboptimal quality and the requirement for fixed-
resolution outputs, leading to undesirable restrictions in prac-
tice.
Regression-based methods [21, 23] offer an intuitive way to
establish a mapping from LR to HR images. LIIF [6] specifi-
cally achieves resolution-continuous outputs through implicit
neural representation. However, these methods often fail to
generate high-fidelity details needed for high magnifications
*
These authors contributed equally.
†
Corresponding Author: bczhang@buaa.edu.cn.
(d)
(c)
(b)
(a)
×10
×8×2
Figure 1. Visual comparison, where training is on 8× SR and testing
on 2×, 8×, and 10×. (a) EDSR [23] and (b) LIIF [6] are regression-
based models; (c) SR3 [35] and (d) IDM (ours) are generative models.
Among them, LIIF and IDM employ the implicit neural representa-
tion.
(see Fig. 1(a) and (b)) since their regression losses tend to cal-
culate the averaged results of possible SR predictions. Deep
generative models, including autoregressive [30, 43], GAN-
based [15,16,18,26], flow-based [8,24] and variational autoen-
coders (VAEs) [17, 42], have emerged as solutions that enrich
detailed textures. Still, they often exhibit artifacts and only ap-
ply to pre-defined fixed magnifications. Despite the ability to
generate realistic images with high perceptual quality with the
help of extra priors, GAN-based models are subject to mode
collapse and struggle to capture complex data distributions,
yielding unnatural textures. Recently, Diffusion Probabilistic
Models (DMs) [12, 39] have been used in image synthesis to
improve the fidelity of SR images and have shown impressive
performance. Nonetheless, DM-based methods are still lim-
ited to fixed magnifications, which would result in corrupted
output once the magnification changes (see Fig. 1(c)). There-
arXiv:2303.16491v1 [cs.CV] 29 Mar 2023

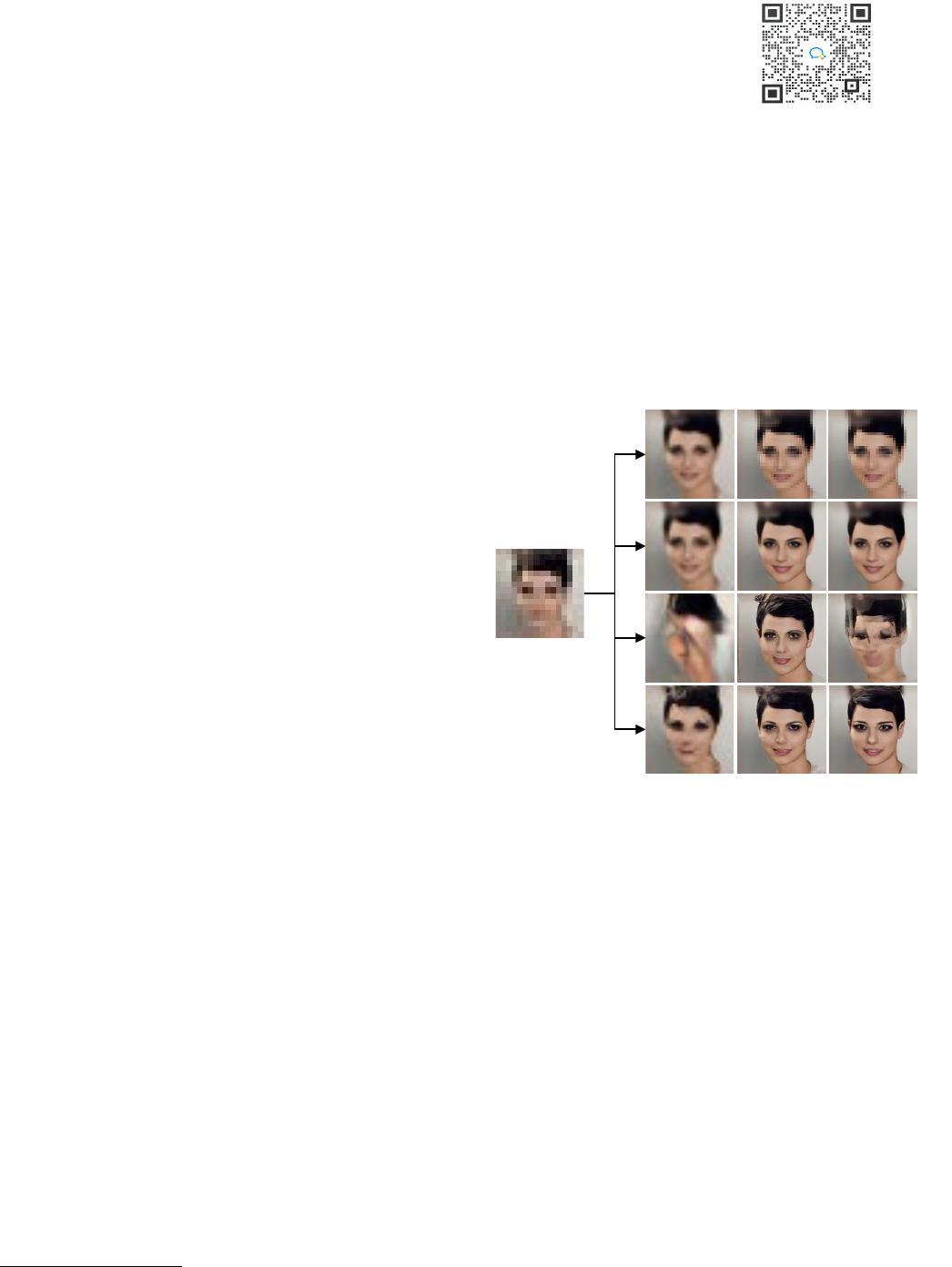
Figure 2. Examples of 16 × super-resolution. (a) LR input. (b) ESRGAN [45] which trains a simple end-to-end structure GAN, and loses the
inherent information. (c) GLEAN [4] which achieves more realistic details through additional StyleGAN [16] priors, but still generates unnatural
textures and GAN-specific artifacts. (d) With implicit continuous representation based on a scale-adaptive conditioning mechanism, IDM generates
the output with high-fidelity details and retains the identity of the ground-truth. (e) The ground-truth.
fore, they turn to a complicated cascaded structure [13] or two-
stage training strategies [10, 33, 34] to achieve multiple com-
bined magnifications, or retrain the model for a specific resolu-
tion [35], which brings extra training cost.
To address these issues, this paper presents a novel Implicit
Diffusion Model (IDM) for high-fidelity image SR across a
continuous range of resolutions. We take the merit of diffu-
sion models in synthesizing fine image details to improve the fi-
delity of SR results and introduce the implicit image function to
handle the fixed-resolution limitation. In particular, we formu-
late continuous image super-resolution as a denoising diffusion
process. We leverage the appealing property of implicit neural
representations by encoding an image as a function into a con-
tinuous space. When incorporated into the diffusion model, it
is parameterized by a coordinate-based Multi-Layer Perceptron
(MLP) to capture the resolution-continuous representations of
images better.
At a high level, IDM iteratively leverages the denoising dif-
fusion model and the implicit image function, which is im-
plemented in the upsampling layers of the U-Net architecture.
Fig. 1(d) illustrates that IDM achieves continuously modu-
lated results within a wide range of resolutions. Accordingly,
we develop a scale-adaptive conditioning mechanism consist-
ing of an LR conditioning network and a scaling factor. The
LR conditioning network can encode LR images without pri-
ors and provide multi-resolution features for the iterative de-
noising steps. The scaling factor is introduced for controlling
the output resolution continuously and works through the adap-
tive MLP to adjust how much the encoded LR and generated
features are expressed. It is worth noting that, unlike previ-
ous methods with two-stage synthesis pipelines [9, 13, 33] or
additional priors [4, 26, 44], IDM enjoys an elegant end-to-end
training framework without extra priors. As shown in Fig. 2,
we can observe that IDM outperforms other previous works in
synthesizing photographic image details.
The main contributions of this paper are summarized as fol-
lows:
• We develop an Implicit Diffusion Model (IDM) for
continuous image super-resolution to reconstruct photo-
realistic images in an end-to-end manner. Iterative im-
plicit denoising diffusion is performed to learn resolution-
continuous representations that enhance the high-fidelity
details of SR images.
• We design a scale-adaptive conditioning mechanism to
dynamically adjust the ratio of the realistic information
from LR features and the generated fine details in the dif-
fusion process. This is achieved through an adaptive MLP
when size-varied SR outputs are needed.
• We conduct extensive experiments on key benchmarks for
natural and facial image SR tasks. IDM exhibits state-
of-the-art qualitative and quantitative results compared to
the previous works and yields high-fidelity resolution-
continuous outputs.
2. Related Work
Implicit Neural Representation. In recent years, implicit
neural representations have shown extraordinary capability in
modeling 3D object shapes, synthesizing 3D surfaces of the
scene, and capturing complicated 3D structures [3, 27–29, 36–
38]. Particularly, methods based on Neural Radiance Fields
(NeRF) [2, 28] utilize Multi-Layer Perceptrons (MLPs) to ren-
der 3D-consistent images with refined texture details. Because
of its outstanding performance in 3D tasks, implicit neural rep-
resentations have been extended to 2D images. Instead of pa-
rameterizing 2D shapes with an MLP with ReLU as in early
works [31, 40], SIREN [37] employs periodic activation func-
tions to model high-quality image representations with fast
convergence. LIIF [6] significantly improves the performance
of representing natural and complex images with local latent
code, which can restore images in an arbitrary resolution. How-
ever, the high-resolution results generated by LIIF are con-
strained by prior LR information, resulting in over-smoothing
with high-frequency information lost.
(a) Low-Resolution (b) ESRGAN (c) GLEAN (d) IDM (ours) (e) Ground-Truth
of 10
50墨值下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

评论