




Eigen:End-to-end Resource Optimization for Large-Scale Databases on the Cloud_阿里云.pdf
免费下载

Eigen: End-to-end Resource Optimization for Large-Scale
Databases on the Cloud
Ji You Li
∗
Alibaba Group
jiyou.ljy@alibaba-
inc.com
Jiachi Zhang
∗
Alibaba Group
zhangjiachi.zjc@
alibaba-inc.com
Wenchao Zhou
Alibaba Group
zwc231487@alibaba-
inc.com
Yuhang Liu
Alibaba Group
johan.lyh@alibaba-
inc.com
Shuai Zhang
Alibaba Group
xuanluo.zs@alibaba-
inc.com
Zhuoming Xue
Alibaba Group
xuezhuoming.xzm@
alibaba-inc.com
Ding Xu
Alibaba Group
xuding.xu@alibaba-
inc.com
Hua Fan
Alibaba Group
guanming.fh@alibaba-
inc.com
Fangyuan Zhou
Alibaba Group
fory@alibaba-
inc.com
Feifei Li
Alibaba Group
lifeifei@alibaba-
inc.com
ABSTRACT
Increasingly, cloud database vendors host large-scale geographi-
cally distributed clusters to provide cloud database services. When
managing the clusters, we observe that it is challenging to simul-
taneously maximizing the resource allocation ratio and resource
availability. This problem becomes more severe in modern cloud
database clusters, where resource allocations occur more frequently
and on a greater scale. To improve the resource allocation ratio with-
out hurting resource availability, we introduce Eigen, a large-scale
cloud-native cluster management system for large-scale databases
on the cloud. Based on a resource ow model, we propose a hierar-
chical resource management system and three resource optimiza-
tion algorithms that enable end-to-end resource optimization. Fur-
thermore, we demonstrate the system optimization that promotes
user experience by reducing scheduling latencies and improving
scheduling throughput. Eigen has been launched in a large-scale
public-cloud production environment for 30+ months and served
more than 30+ regions (100+ available zones) globally. Based on
the evaluation of real-world clusters and simulated experiments,
Eigen can improve the allocation ratio by over 27% (from 60% to
87.0%) on average, while the ratio of delayed resource provisions is
under 0.1%.
PVLDB Reference Format:
Ji You Li, Jiachi Zhang, Wenchao Zhou, Yuhang Liu, Shuai Zhang,
Zhuoming Xue, Ding Xu, Hua Fan, Fangyuan Zhou, and Feifei Li. Eigen:
End-to-end Resource Optimization for Large-Scale Databases on the Cloud.
PVLDB, 16(12): 3795 - 3807, 2023.
doi:10.14778/3611540.3611565
1 INTRODUCTION
In the past decade, we have witnessed the rapid emergence of cloud-
native databases, where users can purchase computing and storage
resources, as well as data management services on demand, without
having to manage the infrastructures themselves. To host these
∗
Both authors contributed equally to this research.
This work is licensed under the Creative Commons BY-NC-ND 4.0 International
License. Visit https://creativecommons.org/licenses/by-nc-nd/4.0/ to view a copy of
this license. For any use beyond those covered by this license, obtain permission by
emailing info@vldb.org. Copyright is held by the owner/author(s). Publication rights
licensed to the VLDB Endowment.
Proceedings of the VLDB Endowment, Vol. 16, No. 12 ISSN 2150-8097.
doi:10.14778/3611540.3611565
cloud-native databases, cloud vendors deploy cluster management
systems (e.g., Mesos [
11
], YARN [
29
], Kubernetes [
13
], Fuxi [
32
],
Borg [
30
], Twine [
28
]) on clusters of machines (nodes) to run jobs
or tasks (e.g., database instances). At the center of a cluster manage-
ment system is a resource scheduler which decides when and how
cloud resources are allocated to dierent jobs. Typically, cloud ven-
dors use two critical metrics to assess whether a resource scheduler
is running “well”: 1) resource allocation ratio refers to the proportion
of allocated resources (out of the total cluster resources) that has
been allocated by the scheduler to a job; 2) resource availability
refers to the proportion of resource requests (from a job) that can
be fullled within a given period of time. Naturally, cloud vendors
aim for a high resource allocation ratio (directly leading to lower
operation costs) and high resource availability (directly leading to
better customer experience).
However, it is intuitively dicult to simultaneously maximize
these two metrics. For example, a classic cluster of algorithms (e.g.,
best-t, rst-t and their variants) aims to ll each machine in
the cluster as tightly as possible, to maximize resource allocation
ratio. However, a high resource allocation ratio indicates limited
idle resources that are readily available for allocation; therefore,
incoming resource requests, especially requests with large resource
needs (e.g., 256GB memory), inevitably have an increased probabil-
ity of failing. Furthermore, heterogeneous resource requirements
observed in practical scenarios can cause resource stranding
1
along
dierent resource dimensions (e.g., CPU, memory, disk), and further
exacerbate the problem. Another cluster of algorithms chooses to
spread tasks across all machines (e.g., worst-t, E-PVM [
1
]). Its
eectiveness, in terms of resource allocation ratio and resource
availability relies on whether the cluster size is set correctly. In
fact, there does not exist a “best" resource scheduling algorithm,
rather, it depends on the application scenario and requires balanc-
ing the optimization of the resource allocation ratio and resource
availability.
Resource schedulers face more challenging scenarios in modern
database clusters, especially with recent advances in serverless
databases [
3
,
4
,
8
] which supports auto-scaling based on the real-
time workloads. More specically, resource schedulers face the
following two challenges:
1
Stranded resources refer to the idle resources (e.g., memory) that cannot be eectively
utilized due to the exhaustion of other types of resources (e.g., disks).
3795
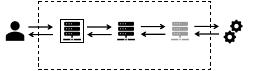
Users
Non-empty
Machines
Empty
Machines
Offline
Machines
Suppliers
Cluster
Figure 1: Three-stage resource ow.
1. Frequent and variant resource requests. The database work-
load varies in response to changes in the user’s data size, data
distribution, query types, or more generally, application-layer char-
acteristics. Unlike traditional database services, where the users
choose the conguration of their database instances, and revisit it
on a weekly or even monthly basis, decisions on scaling up/down
are made every several seconds or minutes.
2. Low tolerance for delayed resource allocation. Resource
requests often reect the necessary resources to retain SLAs (e.g.,
query throughput and latency), and therefore, are highly time-
sensitive. Resource allocation decisions and the actual allocation
need to be made within strong latency (e.g., sub-second) guarantees.
The rst challenge means that the problem of resource stranding (in
the best-t scheduling algorithm) becomes more prominent, which
further triggers a decrease in the allocation availability. On the
other hand, an even resource distribution (in the worst-t schedul-
ing algorithm) will have a penalty on large resource requests: their
accommodation requires a large portion of resources in a single ma-
chine, which is not readily available and requires time-consuming
migration or adding new machines to the cluster. Meanwhile, al-
location availability also depends on the cluster size (i.e., the total
amount of resources we can provide), and it is impractical to add
new machines from the supply chain instantaneously. This drives
service providers to deliberately overestimate cluster size, resulting
in wasted power consumption of underutilized machines, and an
increased carbon emission footprint.
Addressing these challenges, we adopt a cascading resource ow
model that divides nodes into three types (shown in Figure 1): non-
empty nodes, empty nodes, and oine nodes. To simultaneously
maximize the resource allocation ratio and resource availability,
we believe resources in the resource ow should be simultaneously
optimized (i.e., end-to-end resource optimization):
•
Resource optimization of non-empty machines. We discover
two major challenges when adopting classic heuristic bin packing
algorithms for resource scheduling of non-empty machines. First,
cloud database instances require multi-dimensional and hetero-
geneous resources, which makes resource scheduling complex.
Suboptimal allocations can cause skewness of resource dimen-
sions and consequential stranded resources. Second, migration
cost is not negligible when clusters are consolidated. We discuss
optimal consolidation solutions under migration cost constraints.
•
Resource optimization of empty machines. To guarantee
high resource availability, especially with the strict latency con-
straint (see Challenge 2), it is reasonable to maintain a pool of
empty machines as a safety net to handle requests that cannot
be accommodated in the non-empty machines. However, it is
a waste, in terms of power consumption, to maintain a large
pool of online machines while a signicant portion of it is empty
machines. We, therefore, want to maintain just enough empty
machines online to avoid degradation in resource availability.
•
Resource optimization of oline machines. Oine machines
are a shared resource pool for all database products. From a cloud
vendor’s perspective, the maintenance and optimization of oine
machines are also important (from the perspective of operational
cost), but rarely discussed. In practice, cloud vendors purchase
machines from suppliers, and the whole process, from placing
an order to having the machines delivered, typically takes weeks
to months. It is challenging to evaluate the optimal size of oine
machines over a long-term period.
Based on our experiences in resource management for Alibaba’s
database services, we build Eigen, a large-scale, cloud-native cluster
management a system that features end-to-end resource optimiza-
tion. We summarize the contributions of this paper are as follows:
•
Based on the resource ow model, we propose a hierarchical
resource management system which enables three novel resource
optimization algorithms: 1. Vectorized Resource Optimization,
a heuristic bin packing algorithm that consolidates non-empty
machines in the course of resources allocation; 2. Exponential
Smoothing with Smoothed Adaptive Margins which proactively
scales up/down empty machines in a short-term period; 3. Tem-
poral CNN (TCN) with Minimum-stock Policy which optimizes
the number of oine machines in the long-term period.
•
We introduce optimizations for fast scheduling, which include
master-agent collaborative scheduling and cold instance eviction.
•
We evaluate the proposed algorithms, and the overall perfor-
mance of Eigen on large-scale production clusters with real-
world workloads. The evaluation results show that the proposed
algorithms signicantly increase resource allocation ratios of
cloud databases with a negligible rise in the fail/delayed ratio of
allocation requests.
2 BACKGROUND AND MOTIVATION
2.1 Resource Scheduling and Optimization
Resource scheduler is a fundamental component in cluster manage-
ment systems, responsible for allocating resources (such as CPUs,
Memory, Disks) to jobs. Notable examples include Kubernetes’
Kube-scheduler [14], Twine [28]’s allocator, Borg [30]’s scheduler.
Take the Kube-scheduler for instance, it is responsible for assigning
a newly created pod to a machine according to some predetermined
scheduling policy. Kube-scheduler consists of two steps: ltering
and scoring. The ltering step searches all feasible machines to
schedule a pod, and the scoring step chooses the machine deemed
most suitable for the pod (based on the scores calculated using a
scoring strategy). It allows users to customize scoring strategies for
dierent resource scheduling algorithms.
Resource optimization usually aims to maximize resource alloca-
tion ratios (or utilization ratios). Among the previous works, there
are roughly two types of resource optimization approaches. The
rst reduces the resource optimization to the classic bin packing
problem. For example, the Kube-scheduler provides two scoring
strategies (both are variants of best-t) to support bin packing
of resources [
15
]. Another approach utilizes statistical and ma-
chine learning techniques, notably time series forecasting, to im-
prove utilization ratios by predicting future workloads and reclaim-
ing underutilized resources. For example, Autopilot [
24
] uses an
3796
of 13
免费下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

文档被以下合辑收录
评论