




A Dynamic Multi-Scale Voxel Flow Network for Video Prediction.pdf
50墨值下载
A Dynamic Multi-Scale Voxel Flow Network for Video Prediction
Xiaotao Hu
1,2
Zhewei Huang
2
Ailin Huang
2,3
Jun Xu
4,
*
Shuchang Zhou
2,
*
1
College of Computer Science, Nankai University
2
Megvii Technology
3
Wuhan University
4
School of Statistics and Data Science, Nankai University
{huxiaotao, huangzhewei, huangailin, zhoushuchang}@megvii.com, nankaimathxujun@gmail.com
https://huxiaotaostasy.github.io/DMVFN/
Abstract
The performance of video prediction has been greatly
boosted by advanced deep neural networks. However, most
of the current methods suffer from large model sizes and
require extra inputs, e.g., semantic/depth maps, for promis-
ing performance. For efficiency consideration, in this pa-
per, we propose a Dynamic Multi-scale Voxel Flow Net-
work (DMVFN) to achieve better video prediction perfor-
mance at lower computational costs with only RGB images,
than previous methods. The core of our DMVFN is a dif-
ferentiable routing module that can effectively perceive the
motion scales of video frames. Once trained, our DMVFN
selects adaptive sub-networks for different inputs at the in-
ference stage. Experiments on several benchmarks demon-
strate that our DMVFN is an order of magnitude faster than
Deep Voxel Flow [35] and surpasses the state-of-the-art
iterative-based OPT [63] on generated image quality.
1. Introduction
Video prediction aims to predict future video frames
from the current ones. The task potentially benefits the
study on representation learning [40] and downstream fore-
casting tasks such as human motion prediction [39], au-
tonomous driving [6], and climate change [48], etc. Dur-
ing the last decade, video prediction has been increasingly
studied in both academia and industry community [5, 7].
Video prediction is challenging because of the diverse
and complex motion patterns in the wild, in which accurate
motion estimation plays a crucial role [35, 37, 58]. Early
methods [37, 58] along this direction mainly utilize recur-
rent neural networks [19] to capture temporal motion infor-
mation for video prediction. To achieve robust long-term
prediction, the works of [41,59,62] additionally exploit the
semantic or instance segmentation maps of video frames for
semantically coherent motion estimation in complex scenes.
*
Corresponding authors.
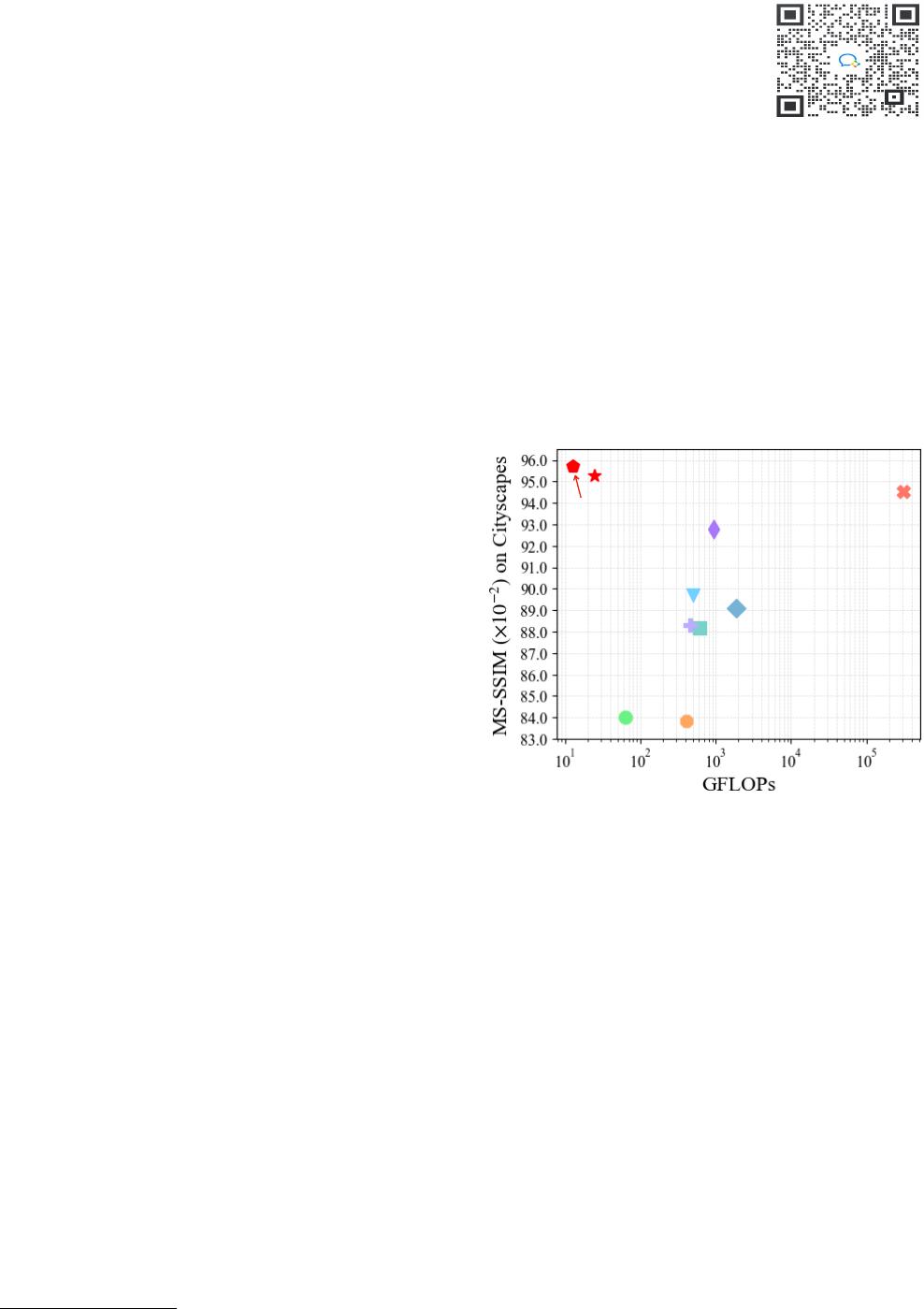
CorrWise (53.4M)
OPT (16.0M)
FVS (82.3M)
Vid2vid (182.5M)
MCNET (14.1M)
Seg2vid (202.1M)
DVF (PyTorch, 3.8M)
PredNet (8.2M)
DMVFN w/o routing (3.5M)
DMVFN (3.5M)
Figure 1. Average MS-SSIM and GFLOPs of different video
prediction methods on Cityscapes [9]. The parameter amounts
are provided in brackets. DMVFN outperforms previous methods
in terms of image quality, parameter amount, and GFLOPs.
However, the semantic or instance maps may not always be
available in practical scenarios, which limits the application
scope of these video prediction methods [41,59,62]. To im-
prove the prediction capability while avoiding extra inputs,
the method of OPT [63] utilizes only RGB images to esti-
mate the optical flow of video motions in an optimization
manner with impressive performance. However, its infer-
ence speed is largely bogged down mainly by the computa-
tional costs of pre-trained optical flow model [54] and frame
interpolation model [22] used in the iterative generation.
The motions of different objects between two adjacent
frames are usually of different scales. This is especially ev-
ident in high-resolution videos with meticulous details [49].
The spatial resolution is also of huge differences in real-
world video prediction applications. To this end, it is es-
sential yet challenging to develop a single model for multi-
scale motion estimation. An early attempt is to extract
arXiv:2303.09875v2 [cs.CV] 24 Mar 2023

multi-scale motion cues in different receptive fields by em-
ploying the encoder-decoder architecture [35], but in prac-
tice it is not flexible enough to deal with complex motions.
In this paper, we propose a Dynamic Multi-scale Voxel
Flow Network (DMVFN) to explicitly model the com-
plex motion cues of diverse scales between adjacent video
frames by dynamic optical flow estimation. Our DMVFN
is consisted of several Multi-scale Voxel Flow Blocks
(MVFBs), which are stacked in a sequential manner. On
top of MVFBs, a light-weight Routing Module is pro-
posed to adaptively generate a routing vector according
to the input frames, and to dynamically select a sub-
network for efficient future frame prediction. We con-
duct experiments on four benchmark datasets, including
Cityscapes [9], KITTI [12], DAVIS17 [43], and Vimeo-
Test [69], to demonstrate the comprehensive advantages
of our DMVFN over representative video prediction meth-
ods in terms of visual quality, parameter amount, and
computational efficiency measured by floating point oper-
ations (FLOPs). A glimpse of comparison results by differ-
ent methods is provided in Figure 1. One can see that our
DMVFN achieves much better performance in terms of ac-
curacy and efficiency on the Cityscapes [9] dataset. Exten-
sive ablation studies validate the effectiveness of the com-
ponents in our DMVFN for video prediction.
In summary, our contributions are mainly three-fold:
• We design a light-weight DMVFN to accurately pre-
dict future frames with only RGB frames as inputs.
Our DMVFN is consisted of new MVFB blocks that
can model different motion scales in real-world videos.
• We propose an effective Routing Module to dynam-
ically select a suitable sub-network according to the
input frames. The proposed Routing Module is end-
to-end trained along with our main network DMVFN.
• Experiments on four benchmarks show that our
DMVFN achieves state-of-the-art results while being
an order of magnitude faster than previous methods.
2. Related Work
2.1. Video Prediction
Early video prediction methods [35, 37, 58] only utilize
RGB frames as inputs. For example, PredNet [37] learns an
unsupervised neural network, with each layer making lo-
cal predictions and forwarding deviations from those pre-
dictions to subsequent network layers. MCNet [58] decom-
poses the input frames into motion and content components,
which are processed by two separate encoders. DVF [35]
is a fully-convolutional encoder-decoder network synthesiz-
ing intermediate and future frames by approximating voxel
flow for motion estimation. Later, extra information is ex-
ploited by video prediction methods in pursuit of better
performance. For example, the methods of Vid2vid [59],
Seg2vid [41], HVP [32], and SADM [2] require additional
semantic maps or human pose information for better video
prediction results. Additionally, Qi et al. [44] used extra
depth maps and semantic maps to explicitly inference scene
dynamics in 3D space. FVS [62] separates the inputs into
foreground objects and background areas by semantic and
instance maps, and uses a spatial transformer to predict the
motion of foreground objects. In this paper, we develop a
light-weight and efficient video prediction network that re-
quires only sRGB images as the inputs.
2.2. Optical Flow
Optical flow estimation aims to predict the per-pixel mo-
tion between adjacent frames. Deep learning-based optical
flow methods [17,29,38,53, 54] have been considerably ad-
vanced ever since Flownet [11], a pioneering work to learn
optical flow network from synthetic data. Flownet2.0 [25]
improves the accuracy of optical flow estimation by stack-
ing sub-networks for iterative refinement. A coarse-to-fine
spatial pyramid network is employed in SPynet [46] to es-
timate optical flow at multiple scales. PWC-Net [53] em-
ploys feature warping operation at different resolutions and
uses a cost volume layer to refine the estimated flow at each
resolution. RAFT [54] is a lightweight recurrent network
sharing weights during the iterative learning process. Flow-
Former [21] utilizes an encoder to output latent tokens and
a recurrent decoder to decode features, while refining the
estimated flow iteratively. In video synthesis, optical flow
for downstream tasks [22, 35, 68, 69, 72] is also a hot re-
search topic. Based on these approaches, we aim to design
a flow estimation network that can adaptively operate based
on each sample for the video prediction task.
2.3. Dynamic Network
The design of dynamic networks is mainly divided into
three categories: spatial-wise, temporal-wise, and sample-
wise [16]. Spatial-wise dynamic networks perform adap-
tive operations in different spatial regions to reduce com-
putational redundancy with comparable performance [20,
47, 57]. In addition to the spatial dimension, dynamic
processing can also be applied in the temporal dimension.
Temporal-wise dynamic networks [52, 64, 70] improve the
inference efficiency by performing less or no computation
on unimportant sequence frames. To handle the input in a
data-driven manner, sample-wise dynamic networks adap-
tively adjust network structures to side-off the extra compu-
tation [56,60], or adaptively change the network parameters
to improve the performance [10, 18, 51, 76]. Designing and
training a dynamic network is not trivial since it is difficult
to directly enable a model with complex topology connec-
tions. We need to design a well-structured and robust model
before considering its dynamic mechanism. In this paper,
of 14
50墨值下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

评论