




Video Probabilistic Diffusion Models in Projected Latent Space.pdf
50墨值下载

Video Probabilistic Diffusion Models in Projected Latent Space
Sihyun Yu
1
Kihyuk Sohn
2
Subin Kim
1
Jinwoo Shin
1
1
KAIST
2
Google Research
{sihyun.yu, subin-kim, jinwoos}@kaist.ac.kr, kihyuks@google.com
Abstract
Despite the remarkable progress in deep generative
models, synthesizing high-resolution and temporally co-
herent videos still remains a challenge due to their high-
dimensionality and complex temporal dynamics along with
large spatial variations. Recent works on diffusion models
have shown their potential to solve this challenge, yet they
suffer from severe computation- and memory-inefficiency
that limit the scalability. To handle this issue, we propose
a novel generative model for videos, coined projected la-
tent video diffusion model (PVDM), a probabilistic dif-
fusion model which learns a video distribution in a low-
dimensional latent space and thus can be efficiently trained
with high-resolution videos under limited resources. Specifi-
cally, PVDM is composed of two components: (a) an autoen-
coder that projects a given video as 2D-shaped latent vectors
that factorize the complex cubic structure of video pixels and
(b) a diffusion model architecture specialized for our new fac-
torized latent space and the training/sampling procedure to
synthesize videos of arbitrary length with a single model. Ex-
periments on popular video generation datasets demonstrate
the superiority of PVDM compared with previous video syn-
thesis methods; e.g., PVDM obtains the FVD score of 639.7
on the UCF-101 long video (128 frames) generation bench-
mark, which improves 1773.4 of the prior state-of-the-art.
1. Introduction
Recent progresses of deep generative models have shown
their promise to synthesize high-quality, realistic samples in
various domains, such as images [9, 27, 41], audio [8, 31, 32],
3D scenes [6, 38, 48], natural languages [2, 5], etc. As
a next step forward, several works have been actively
focusing on the more challenging task of video synthe-
sis [12, 18, 21, 47, 55, 67]. In contrast to the success in other
domains, the generation quality is yet far from real-world
videos, due to the high-dimensionality and complexity of
videos that contain complicated spatiotemporal dynamics in
high-resolution frames.
Inspired by the success of diffusion models in handling
complex and large-scale image datasets [9, 40], recent ap-
proaches have attempted to design diffusion models for
videos [16, 18, 21, 22, 35, 66]. Similar to image domains,
these methods have shown great potential to model video
distribution much better with scalability (both in terms of
spatial resolution and temporal durations), even achieving
photorealistic generation results [18]. However, they suffer
from severe computation and memory inefficiency, as diffu-
sion models require lots of iterative processes in input space
to synthesize samples [51]. Such bottlenecks are much more
amplified in video due to a cubic RGB array structure.
Contribution.
We present a novel latent diffusion model
for videos, coined projected latent video diffusion model
(PVDM). Specifically, it is a two-stage framework (see Fig-
ure 1
Meanwhile, recent works in image generation have pro-
posed latent diffusion models to circumvent the computation
and memory inefficiency of diffusion models [15, 41, 59].
Instead of training the model in raw pixels, latent diffusion
models first train an autoencoder to learn a low-dimensional
latent space succinctly parameterizing images [10, 41, 60]
and then models this latent distribution. Intriguingly, the ap-
proach has shown a dramatic improvement in efficiency for
synthesizing samples while even achieving state-of-the-art
generation results [41]. Despite their appealing potential,
however, developing a form of latent diffusion model for
videos is yet overlooked.
for the overall illustration):
•
Autoencoder: We introduce an autoencoder that repre-
sents a video with three 2D image-like latent vectors by
factorizing the complex cubic array structure of videos.
Specifically, we propose 3D
→
2D projections of videos
at each spatiotemporal direction to encode 3D video pix-
els as three succinct 2D latent vectors. At a high level,
we design one latent vector across the temporal direction
to parameterize the common contents of the video (e.g.,
background), and the latter two vectors to encode the mo-
tion of a video. These 2D latent vectors are beneficial for
achieving high-quality and succinct encoding of videos,
as well as enabling compute-efficient diffusion model
architecture design due to their image-like structure.
1
arXiv:2302.07685v2 [cs.CV] 30 Mar 2023
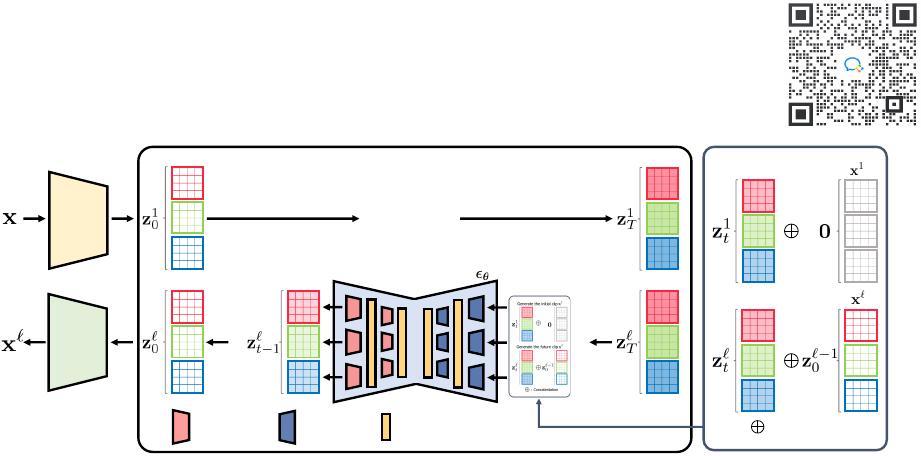
Figure 1. Overall illustration of our projected latent video diffusion model (PVDM) framework. PVDM is composed of two components: (a)
(left) an autoencoder that maps a video into 2D image-like latent space (b) (right) a diffusion model operates in this latent space.
•
Diffusion model: Based on the 2D image-like latent
space built from our video autoencoder, we design a
new diffusion model architecture to model the video
distribution. Since we parameterize videos as image-
like latent representations, we avoid computation-heavy
3D convolutional neural network architectures that are
conventionally used for handling videos. Instead, our
architecture is based on 2D convolution network diffu-
sion model architecture that has shown its strength in
handling images. Moreover, we present a joint training
of unconditional and frame conditional generative mod-
eling to generate a long video of arbitrary lengths.
We verify the effectiveness of our method on two popu-
lar datasets for evaluating video generation methods: UCF-
101 [54] and SkyTimelapse [64]. Measured with Inception
score (IS; higher is better [44]) on UCF-101, a represen-
tative metric of evaluating unconditional video generation,
PVDM achieves the state-of-the-art result of 74.40 on UCF-
101 in generating 16 frames, 256
×
256 resolution videos. In
terms of Fréchet video distance (FVD; lower is better [58])
on UCF-101 in synthesizing long videos (128 frames) of
256
×
256 resolution, it significantly improves the score from
1773.4 of the prior state-of-the-art to 639.7. Moreover, com-
pared with recent video diffusion models, our model shows
a strong memory and computation efficiency. For instance,
on a single NVIDIA 3090Ti 24GB GPU, a video diffusion
model [21] requires almost full memory (
≈
24GB) to train
at 128
×
128 resolution with a batch size of 1. On the other
hand, PVDM can be trained with a batch size of 7 at most
per this GPU with 16 frames videos at 256×256 resolution.
To our knowledge, the proposed PVDM is the first latent
diffusion model designed for video synthesis. We believe
our work would facilitate video generation research towards
efficient real-time, high-resolution, and long video synthesis
under the limited computational resource constraints.
2. Related work
Video generation.
Video generation is one of the long-
standing goals in deep generative models. Many prior works
have attempted to solve the problem and they mostly fall into
three categories. First, there exists numerous attempts to ex-
tend image generative adversarial networks (GANs) [13] to
generate videos [1,7,11,14,23,36,42,43,46,47,55,57,62,67,
68]; however, GANs often suffer from mode collapse prob-
lem and these methods are difficult to be scaled to complex,
large-scale video datasets. Other approaches have proposed
learning the distribution via training autoregressive mod-
els [12, 24, 39, 63, 65] using Transformers [61]. They have
shown better mode coverage and video quality than GAN-
based approaches, but they require expensive computation
and memory costs to generate longer videos [47]. Finally,
recent works have attempted to build diffusion models [19]
for videos [16, 21, 22, 46, 66], achieving state-of-the-art re-
sults, yet they also suffer from significant computation and
memory inefficiency. Our method also takes an approach to
diffusion models for videos; however, we consider the gener-
ative modeling in low-dimensional latent space to alleviate
these bottlenecks of diffusion models.
Diffusion models.
Diffusion models [19, 49], which are cat-
egorized as score-based generative models [52, 53], model
the data distribution by learning a gradual iterative denoising
process from the Gaussian distribution to the data distribu-
tion. Intriguingly, they show a strong promise in generating
high-quality samples with wide mode coverage, even outper-
forming GANs in image synthesis [9] and enabling zero-shot
text-to-image synthesis [40]. Not limited to images, diffu-
sion models have shown their promise in other data domains,
including point clouds [34], audio [31], etc. However, dif-
fusion models suffer from severe computation inefficiency
for data sampling due to the iterative denoising process in
high-dimensional data space. To alleviate this problem, sev-
2
Denoising autoencoder
Video
encoder
Video
decoder
Latent space
Diffusion process
⋯
⋯
Upsample
residual block
(shared)
Attention
layer
Downsample
residual block
(shared)
: Concatenation
Generate the future clip
Generate the initial clip
of 15
50墨值下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

评论