

1



技术分享 _ EXPLAIN 执行计划详解(2)--Extra.pdf
免费下载
技术分享 | EXPLAIN 执行计划详解(2)--Extra
作者:胡呈清
爱可生 DBA 团队成员,擅长故障分析、性能优化,个人博客:https://www.jianshu.com/u/a95ec11f67a8,
欢迎讨论。
本文来源:原创投稿
*爱可生开源社区出品,原创内容未经授权不得随意使用,转载请联系小编并注明来源。
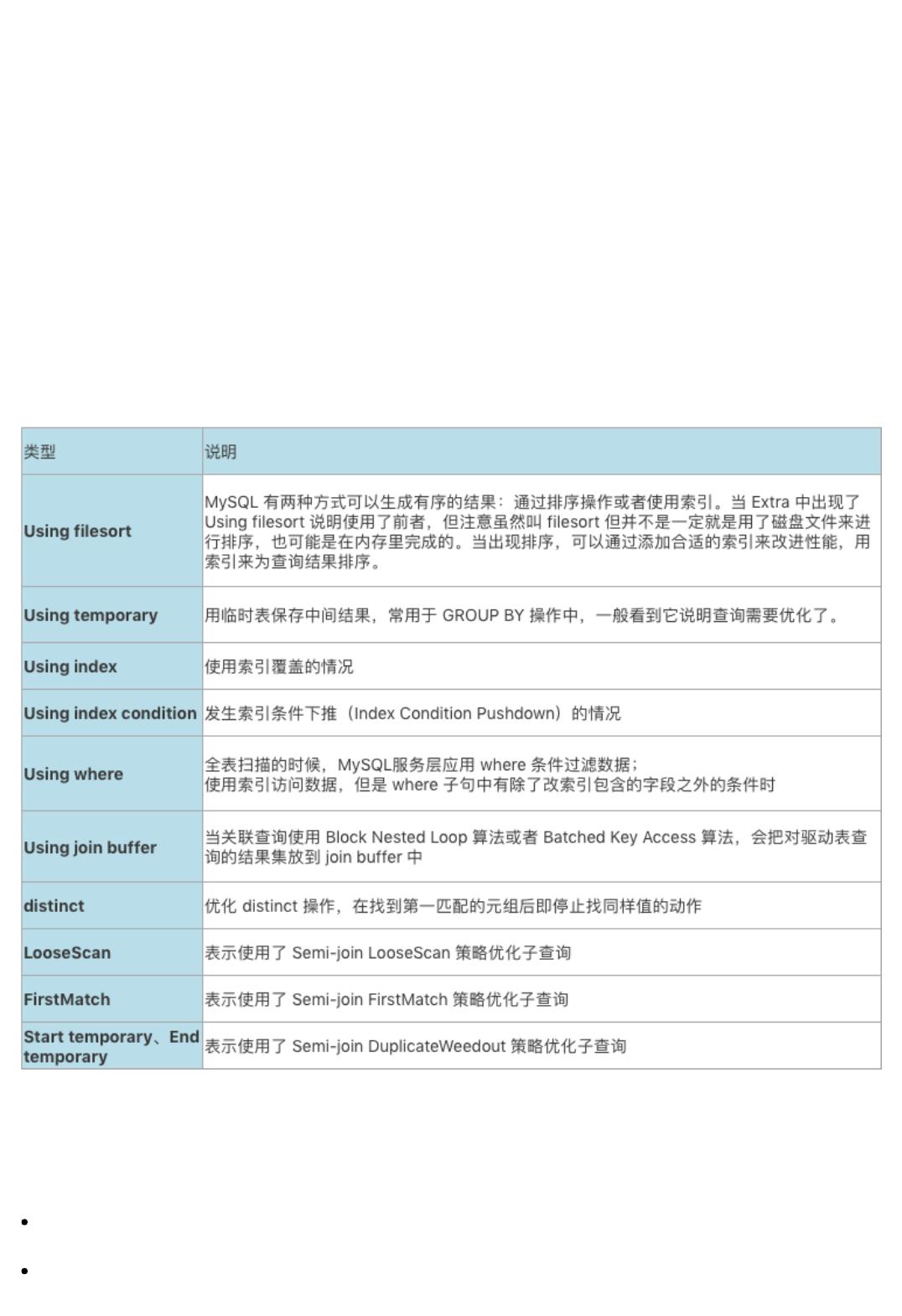
Extra
Extra 是 EXPLAIN 输出中另外一个很重要的列,该列显示 MySQL 在查询过程中的一些详细信息。
Using index
使用索引覆盖的情况下,执行计划的 extra 会显示为 "Using index":
查询的字段都包含在使用的索引中;
where 子句使用的字段也都包含在使用的索引中。

比如:
有组合索引:idx_a (first_name,last_name,birth_date)
mysql> explain select first_name,last_name,birth_date from employees where \
first_name='Mayuri' and last_name like 'Alpay' and birth_date > '1968-01-01'\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: employees
partitions: NULL
type: range
possible_keys: idx_a
key: idx_a
key_len: 127
ref: NULL
rows: 1
filtered: 100.00
Extra: Using where; Using index
Using index condition
查询数据时如果使用 index condition down 索引条件下推就会在执行计划的 extra 字段中出现 "Using index
condition"。
使用二级索引查找数据时,where 条件中属于索引一部分但无法使用索引的条件(比如 like '%abc' 左侧字符不
确定),MySQL 也会把这部分判断条件下推到存储引擎层,筛选之后再进行回表,这样回表时需要查找的数据
就更少。
索引条件下推的特点:
下推的条件涉及的字段一定要是使用到的二级索引的一部分,因为二级索引索引存储了这些字段的值,才能
进行筛选,所以叫做“索引条件下推”;
大幅减小回表时的随机 I/O 开销。因为索引条件下推可以在查找完二级索引后利用条件筛选,减小结果集,
减小接下来回表的次数,而回表做的是随机 I/O(开销大),所以能够节省大量的 I/O 开销;
大幅减小了存储引擎层到 MySQL 服务层的传输开销。条件下推给了存储引擎层,提前进行筛选,这样返回
给 MySQL 服务层的数据就变少了;
剩下的不能用到索引的 where 条件还是在 MySQL 服务层生效。
示例 1
有一个组合索引:idx_a (first_name,last_name,birth_date)
SQL:
of 8
免费下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

评论