

1



Halo DB 14 小白零基础系列7.docx
免费下载

Halo DB 14 小白零基础系列(7)--HaloDB 中的体系结构
前言:
在任何数据库的学习中,如果想深入的理解一种数据库系统,对于体系结构的理解和掌握都是重中之重,
本篇开始为大家正式开始 的体系结构介绍。
上一期留给大家的小问题的答案在这里公布下。上一期的问题给大家回忆下:
要求查询出每门课都大于 分的学生姓名
create table s1(name char(6),subject char(8),score int);
insert into s1 values('张三','语文',79);
insert into s1 values('张三','数学',75);
insert into s1 values('李四','语文',76);
insert into s1 values('李四','数学',90);
insert into s1 values('王五','语文',90);
insert into s1 values('王五','数学',100);
insert into s1 values('王五','英语',81);
在上一篇我们介绍了 子句以及分组函数的使用方法,如题所示,要求查询出 表每门课都大于 的学
生的姓名
答案如下:
select name from s1 group by name having min(score)>80;
开始今天的正式内容。
一、HaloDB 的体系结构:
如下图 所示, 数据库的体系结构。数据库实例主要包含共享内存区域、本地内
存区域和一系列后台进程。其中共享内存区域主要由共享缓存、事务日志缓存构成。后
台进 程 主 要 由 ( 数 据 写进 程 ) 、 ( 事 务日 志 写 进
程)、(检查点进程)、 (统计信息收集进程)、
(自动清理进程)等构成。数据库群集主要由数据文件、事务日志文件
及其它一些辅助文件组成。
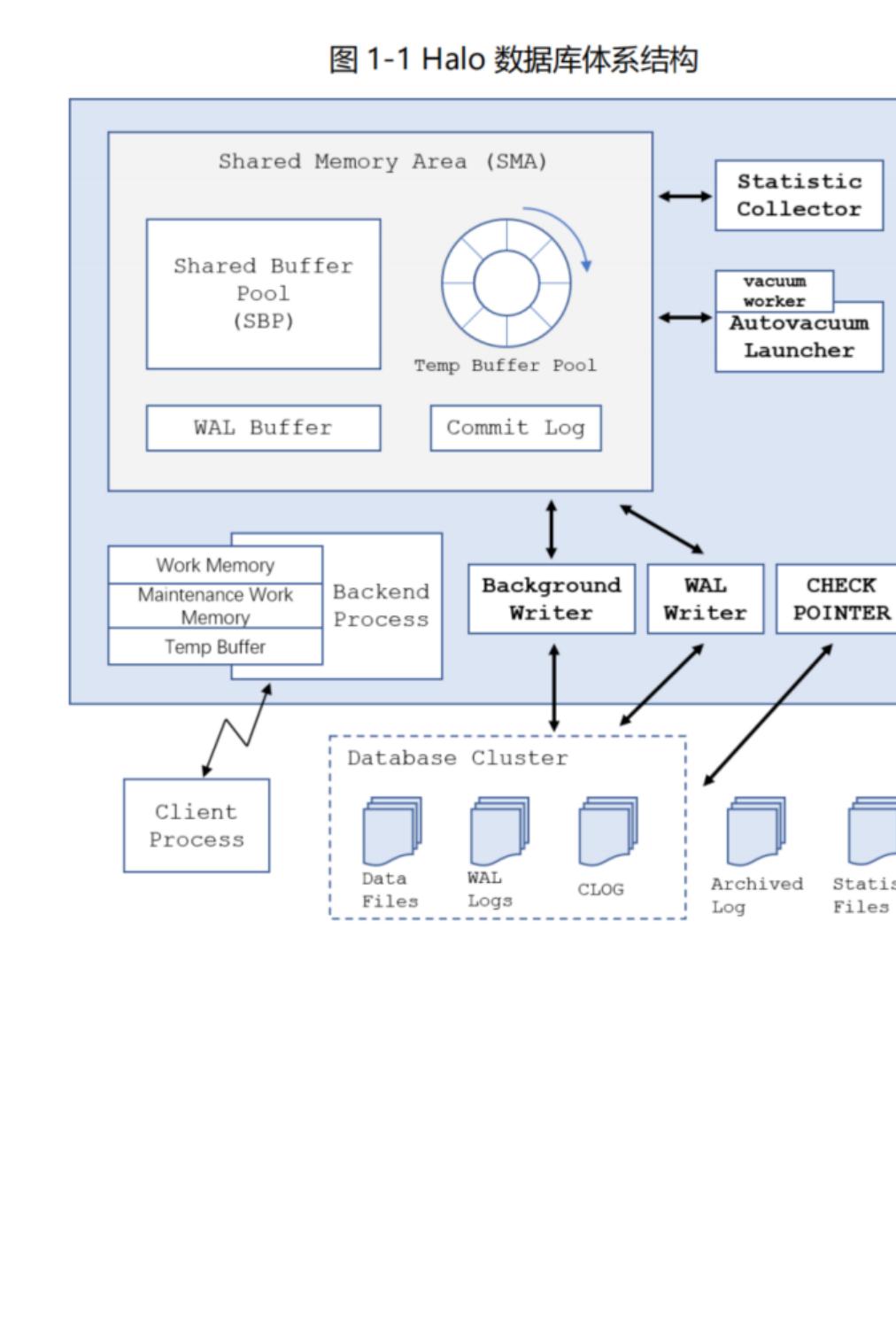
1、HaloDB 中的共享内存区域和本地内存区域:
在我们的 中,内存架构部分主要分为,本地内存区域( !)和共享内存区域
( !)两个部分,下面针对每个部分做详细的说明;
a. 本地内存区域(Local Memory Area): 本地内存区域是每个后台进程(")独立使
用的内存空间。每个后台进程都有自己的本地内存区域,用于存储会话相关的数据和临时数据。本地内存区域包
括以下几个重要的组件:
栈():用于存储函数调用和局部变量等信息。
上下文(#):用于管理内存分配和释放,每个上下文都有一个父上下文,形成一个层次结构。
缓冲区($ ):用于存储查询结果集的数据,以及排序和哈希操作的中间结果。
连接 信 息( %& ): 用于存储 与 客 户端 连 接 相关 的 信 息,如会 话 状 态、 权 限
等。
b. 共享内存区域(Shared Memory Area): 共享内存区域是多个后台进程共享的内存空间,用于存储
全局数据和缓存数据,以提高性能和效率。共享内存区域包括以下几个重要的组件:
of 13
免费下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

评论