




搜索引擎的查找算法实现.pdf
免费下载

搜索引擎的查找算法实现
前言
我们每天都在用 Google, 百度这些搜索引擎,那大家有没想过搜索引擎是如何实现的呢,看似简单的搜索其实技术细
节非常复杂,说搜索引擎是 IT 皇冠上的明珠也不为过,今天我们来就来简单过一下搜索引擎的原理,看看它是如何工
作的,当然搜索引擎博大精深,一篇文章不可能完全介绍完,我们只会介绍它最重要的几个步骤,不过万变不离其宗,
搜索引擎都离不开这些重要步骤,剩下的无非是在其上添砖加瓦,所以掌握这些「关键路径」,能很好地达到观一斑而
窥全貎的目的。
本文将会从以下几个部分来介绍搜索引擎,会深度剖析搜索引擎的工作原理及其中用到的一些经典数据结构和算法,相
信大家看了肯定有收获。
1、搜索引擎系统架构图
2、搜索引擎工作原理详细剖析
搜索引擎系统架构图
搜索引擎整体架构图如下图所示,大致可以分为搜集,预处理,索引,查询这四步,每一步的技术细节都很多,我们将
在下文中详细分析每一步的工作原理。
搜索引擎工作原理详细剖析
一、搜集
爬虫一开始是不知道该从哪里开始爬起的,所以我们可以给它一组优质种子网页的链接,比如新浪主页,腾讯主页等,
这些主页比较知名,在 Alexa 排名上也非常靠前,拿到这些优质种子网页后,就对这些网页通过广度优先遍历不断遍
历这些网页,爬取网页内容,提取出其中的链接,不断将其将入到待爬取队列,然后爬虫不断地从 url 的待爬取队列里
提取出 url 进行爬取,重复以上过程...
当然了,只用一个爬虫是不够的,可以启动多个爬虫并行爬取,这样速度会快很多。
1、待爬取的 url 实现
待爬取 url 我们可以把它放到 Redis 里,保证了高性能,需要注意的是,Redis 要开启持久化功能,这样支持断点续
爬,如果 Redis 挂掉了,重启之后由于有持续久功能,可以从上一个待爬的 url 开始重新爬。
2、如何判重
如何避免网页的重复爬取呢,我们需要对 url 进行去重操作,去重怎么实现?可能有人说用散列表,将每个待抓取 url 存
在散列表里,每次要加入待爬取 url 时都通过这个散列表来判断一下是否爬取过了,这样做确实没有问题,但我们需要
注意到的是这样需要会出巨大的空间代价,有多大,我们简单算一下,假设有 10 亿 url (不要觉得 10 亿很大,像
Google, 百度这样的搜索引擎,它们要爬取的网页量级比 10 亿大得多),放在散列表里,需要多大存储空间呢?
我们假设每个网页 url 平均长度 64 字节,则 10 亿个 url 大约需要 60 G 内存,如果用散列表实现的话,由于散列
表为了避免过多的冲突,需要较小的装载因子(假设哈希表要装载 10 个元素,实际可能要分配 20 个元素的空间,以
避免哈希冲突),同时不管是用链式存储还是用红黑树来处理冲突,都要存储指针,各种这些加起来所需内存可能会超
过 100 G,再加上冲突时需要在链表中比较字符串,性能上也是一个损耗,当然 100 G 对大型搜索引擎来说不是什么
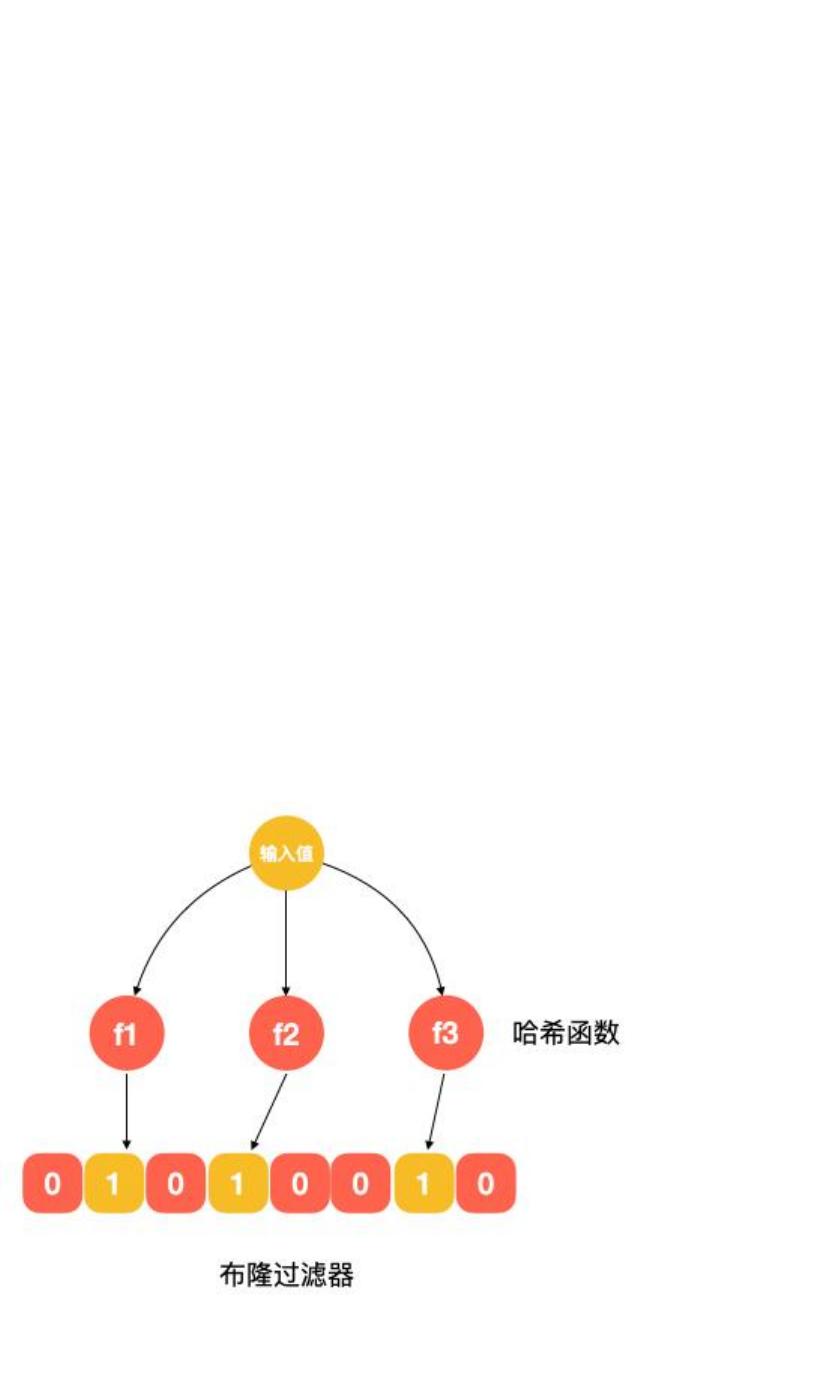
大问题,但其实还有一种方案可以实现远小于 100 G 的内存:布隆过滤器。
针对 10 亿个 url,我们分配 100 亿个 bit,大约 1.2 G, 相比 100 G 内存,提升了近百倍!可见技术方案的合理选择
能很好地达到降本增效的效果。
of 7
免费下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

评论