




尚硅谷大数据之impala.pdf
10墨值下载

尚硅谷大数据技术之 CM 安装
更多 Java –大数据 –前端 –python 人工智能资料下载,可百度访问:尚硅谷官网
尚硅谷大数据技术之 Impala
(作者:尚硅谷大数据研发部)
版本:V1.0
第1章 Impala 的基本概念
1.1 什么是 Impala
Cloudera 公司推出,提供对 HDFS、Hbase 数据的高性能、低延迟的交互式 SQL 查询功
能。
基于 Hive,使用内存计算,兼顾数据仓库、具有实时、批处理、多并发等优点。
是 CDH 平台首选的 PB 级大数据实时查询分析引擎。
1.2 Impala 的优缺点
1.2.1 优点
1) 基于内存运算,不需要把中间结果写入磁盘,省掉了大量的 I/O 开销。
2) 无需转换为 Mapreduce,直接访问存储在 HDFS,HBase 中的数据进行作业调度,
速度快。
3) 使用了支持 Data locality 的 I/O 调度机制,尽可能地将数据和计算分配在同一台机
器上进行,减少了网络开销。
4) 支持各种文件格式,如 TEXTFILE 、SEQUENCEFILE 、RCFile、Parquet。
5) 可以访问 hive 的 metastore,对 hive 数据直接做数据分析。
尚硅谷大数据技术之 CM 安装
更多 Java –大数据 –前端 –python 人工智能资料下载,可百度访问:尚硅谷官网
1.2.2 缺点
1) 对内存的依赖大,且完全依赖于 hive。
2) 实践中,分区超过 1 万,性能严重下降。
3) 只能读取文本文件,而不能直接读取自定义二进制文件。
4) 每当新的记录/文件被添加到 HDFS 中的数据目录时,该表需要被刷新。
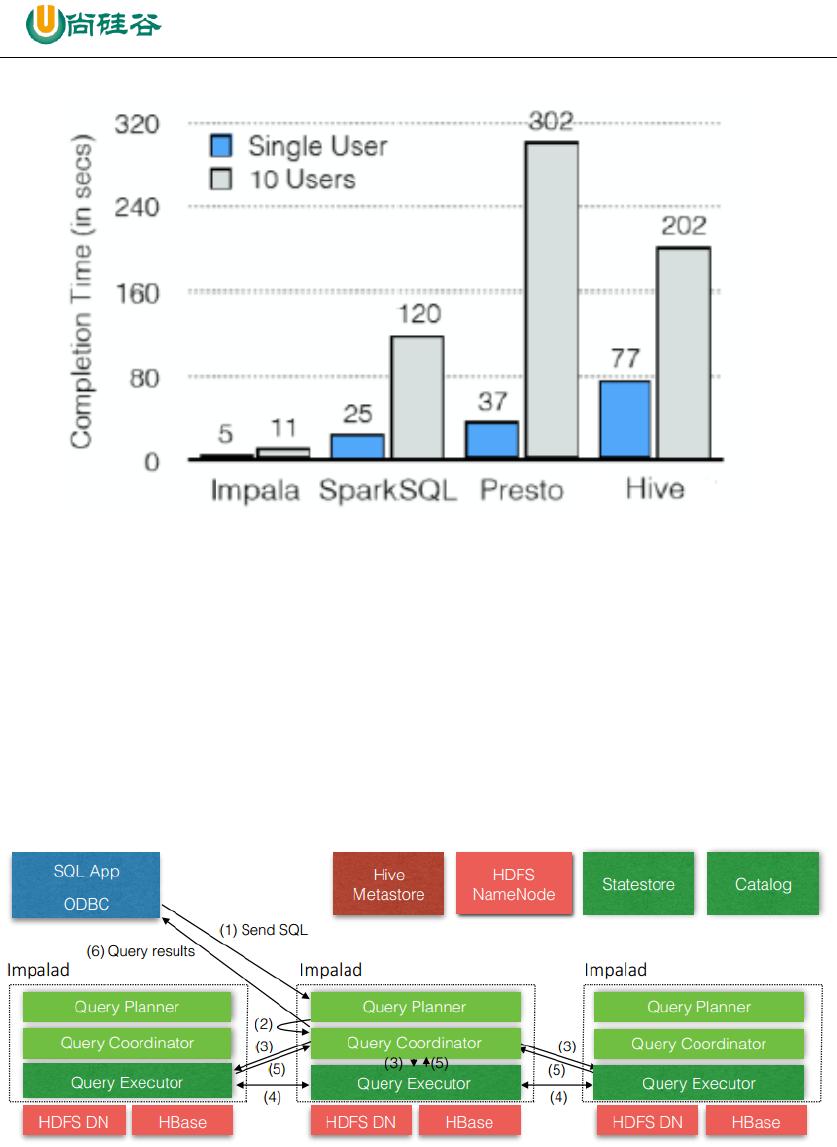
1.3 Impala 的架构
从上图可以看出,Impala 自身包含三个模块:Impalad、Statestore 和 Catalog,除此之外
它还依赖 Hive Metastore 和 HDFS。
1) Impalad:
接收 client 的请求、Query 执行并返回给中心协调节点;
子节点上的守护进程,负责向 statestore 保持通信,汇报工作。
2) Catalog:
of 14
10墨值下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

评论