




7.HASH索引详解-01.docx
免费下载
HASH 索引介绍
HASH 索引是使用 hash 函数对索引的关键字进行 hash 运算后,将 hashcode 作为键存放,它
只能处理简单的等值查询。其主要目的就是对于某些数据类型(索引键),快速找到匹配的行
的 ctid。
hash 索引特别适用于字段值非常长(不适合 b-tree 索引,因为 b-tree 一个 PAGE 至少要存储
3 个 ENTRY,所以不支持特别长的 VALUE)的场景,例如很长的字符串,并且用户只需要
等值搜索,建议使用 hash index。
在 pg10 之前是不提倡使用 hash 索引的,因为 hash 索引不会写 wal 日志,无法保证持久性,
在高可用场景下可能给出错误的查询结果。不过从 pg10 开始解决了这一问题,并且对 hash
索引进行了一些加强。
通常,数据类型的允许值范围非常大:在 text 类型的列中我们可以任意多个字符,在 varchar
类型中最大可以存放 1GB。但通常情况下,不会存放那么多。
哈希的思想是将少量的数字(从 0 到 N -1,总共 N 个值)与任何数据类型的值相关联。通过
哈希函数所获得的数字可用作常规数组的索引,其中将存储对表行(TID)的引用。该数组的
元素称为哈希表存储桶(bucket),如果相同的索引值出现在不同的行中,则一个存储桶可以
存储多个 TID。
索引结构
当插入索引时,先计算键的哈希值。PostgreSQL 中的哈希函数总是返回 integer 类型,其范
围为 2 的 32 次方≈40 亿个值。哈希桶的数量最初等于 2,然后根据数据大小动态增加。哈希
桶编号可以使用位算法从哈希码中计算出来。为了节省空间,哈希桶不是存储键,而是存储了
键的哈希码和 TID。
当搜索索引时,我们用哈希函数计算键的哈希码并获取哈希桶编号。然后需要遍历存储桶的内
容,并仅返回具有适当哈希码的匹配 TID。由于存储的 hashcode - TID 对是有序的,因此可
以高效地完成此操作。
但是,两个不同的键可能会进入一个哈希桶,而且可能会具有相同的哈希码,而且无法消除这
种冲突。因此,访问方法要求通用索引引擎通过重新检查表行中的条件来验证每个 TID(引擎
可以在进行可见性检查的同时执行此操作)。
哈希索引包含 4 种页:meta page, primary bucket page,overflow page, bitmap page。
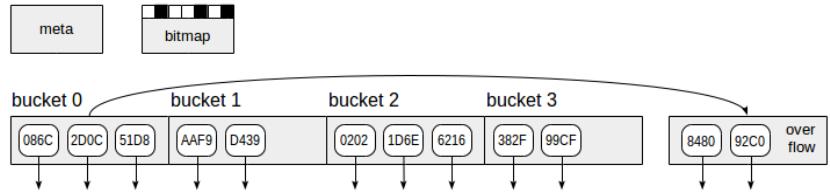
• 元页面(meta page 第 0 页):包含有关索引的控制信息,指导如何找到其他页面(每个
bucket 的 primary page)。
hash index 将存储划分为多个 bucket(逻辑概念),每个 bucket 中包含若干 page(每个
bucket 的 page 数量不需要一致),当插入数据时,根据计算得到的哈希码,通过映射算法,
映射到某个 bucket,也就是说数据首先知道应该插入哪个 bucket 中,然后插入 bucket 中的
primary page,如果 primary page 空间不足时,会扩展 overflow page,数据写入 overflow
page。在 page 中,数据是有序存储(TREE),page 内支持二分查找(binarysearch),而
page 与 page 之间是不保证顺序的,所以 hash index 不支持 order by。
哈希桶页面• -索引的主页,将数据存储为“哈希码-TID”对。
溢出页面:是• bucket 里面的页,与哈希桶页面的结构相同,当 primary page 没有足够空间
时,扩展的块称为 overflow page。
位图页面:记录• primary page, overflow page 是否为空可以被重用。
从索引页元素开始的向下箭头表示 TID,即对表行的引用。
每次索引增加,PostgreSQL 即时创建的哈希桶(也就是页面)数量是上次创建的存储桶数量
的两倍。为了避免一次分配大量潜在的页面,版本 10 使大小增加更加平稳。对于溢出页面,
它们会根据需要进行分配,并在位图页面中进行跟踪,位图页面也会根据需要进行分配。
注意:哈希索引不能减小大小。如果删除一些索引行,则已经分配的页面不会返回给操作系统,
而只会在 VACUUM 之后重新用于新数据(通过 bitmappage 跟踪)。减小索引大小的唯一选
项是使用 REINDEX 或 VACUUM FULL 命令从头开始重建索引。
创建哈希索引:
create index on t1 using hash(name);
explain select * from t1 where name = '1f0e3dad99908345f7439f8ffabdffc4';
哈希索引的通用性远低于“ B-tree”,其效率也值得怀疑。因此,它是适用场景很小。
of 3
免费下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

评论