




换种思路写分页查询.pdf
免费下载

更新时间:2019-08-08 09:52:34
07 换种思路写分页查询换种思路写分页查询
很多时候,业务上会有分页操作的需求,对应的 SQL 类似下面这条:
表示从表 t1 中取出从 10001 行开始的 10 行记录。看似只查询了 10 条记录,实际这条 SQL 是先读取 10010 条记
录,然后抛弃前 10000 条记录,然后读到后面 10 条想要的数据。因此要查询一张大表比较靠后的数据,执行效率
是非常低的。本节内容就一起研究下,是否有办法去优化分页查询。
为了方便验证,首先创建测试表并写入数据:
你若要喜爱你自己的价值,你就得给世界创造价值。
——歌德
select a,b,c from t1 limit 10000,10;
本节会分享两种分页场景的优化技巧:
根据自增且连续主键排序的分页查询
查询根据非主键字段排序的分页查询
1 根据自增且连续主键排序的分页查询根据自增且连续主键排序的分页查询
首先来看一个根据自增且连续主键排序的分页查询的例子:
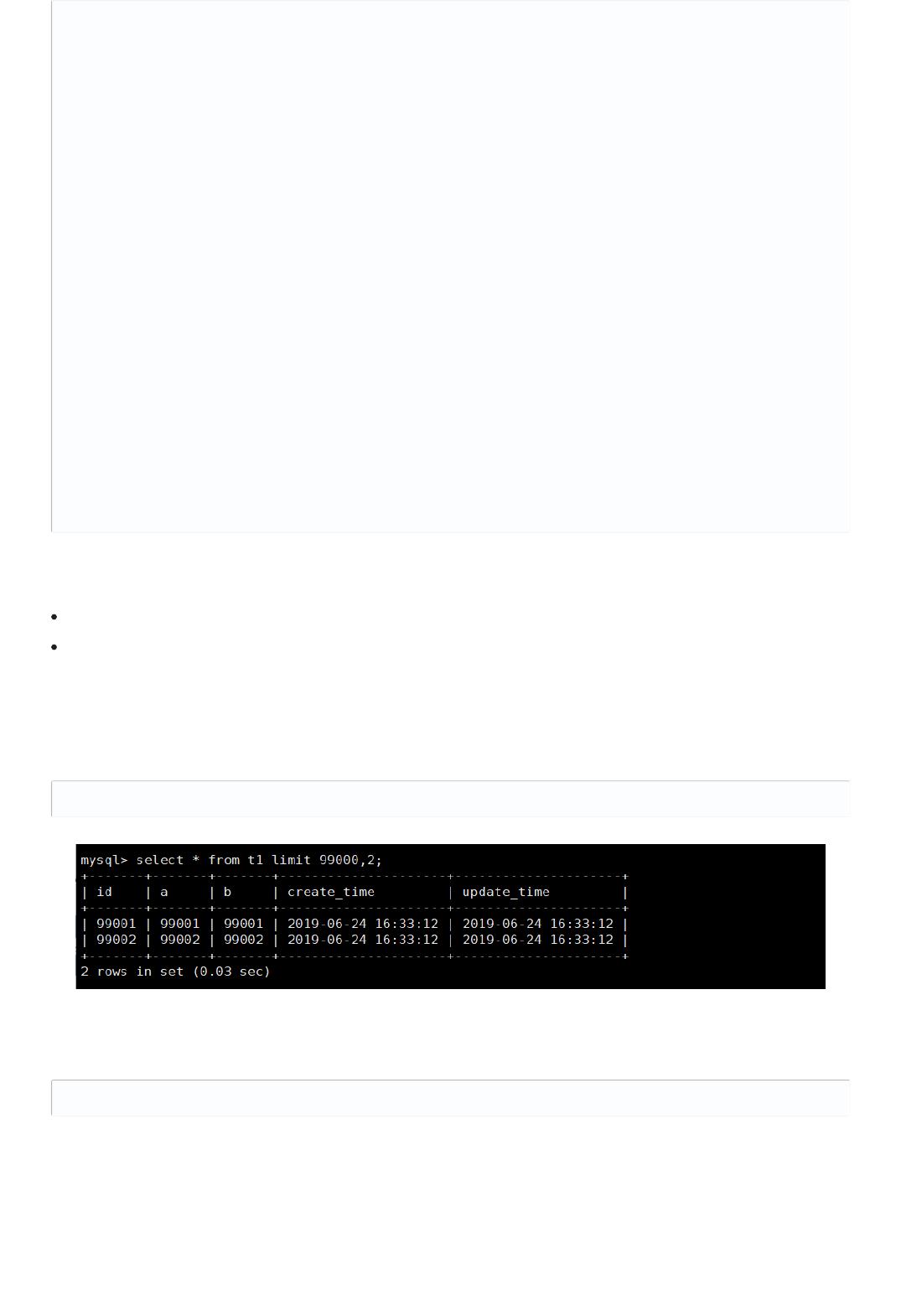
该 SQL 表示查询从第 99001开始的两行数据,没添加单独 order by,表示通过主键排序。我们再看表 t1,因为主
键是自增并且连续的,所以可以改写成按照主键去查询从第 99001开始的两行数据,如下:
use muke; /* 使用muke这个database */
drop table if exists t1; /* 如果表t1存在则删除表t1 */
CREATE TABLE `t1` ( /* 创建表t1 */
`id` int(11) NOT NULL auto_increment,
`a` int(11) DEFAULT NULL,
`b` int(11) DEFAULT NULL,
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '记录创建时间',
`update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '记录更新时间',
PRIMARY KEY (`id`),
KEY `idx_a` (`a`),
KEY `idx_b` (`b`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
drop procedure if exists insert_t1; /* 如果存在存储过程insert_t1,则删除 */
delimiter ;;
create procedure insert_t1() /* 创建存储过程insert_t1 */
begin
declare i int; /* 声明变量i */
set i=1; /* 设置i的初始值为1 */
while(i<=100000)do /* 对满足i<=100000的值进行while循环 */
insert into t1(a,b) values(i, i); /* 写入表t1中a、b两个字段,值都为i当前的值 */
set i=i+1; /* 将i加1 */
end while;
end;;
delimiter ; /* 创建批量写入100000条数据到表t1的存储过程insert_t1 */
call insert_t1(); /* 运行存储过程insert_t1 */
select * from t1 limit 99000,2;
select * from t1 where id >99000 limit 2;
of 5
免费下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

文档被以下合辑收录
评论