




AI-Powered Orchestration of Multi-Model Data_Jáchym Bártík (Charles University).pdf
免费下载

AI-Powered Orchestration of Multi-Model Data
Jáchym Bártík
supervised by Irena Holubová
Faculty of Mathematics and Physics, Charles University
Prague, Czech Republic
jachym.bartik@matfyz.cuni.cz
ABSTRACT
Multi-model databases are an increasingly popular solution to to-
day’s data management challenges of Big Data. However, their
inherent complexity and lack of standardization stand in the way
of their widespread adoption. In our research, we focus on reducing
the complexity by automating the management of such databases.
The goal is to provide a robust framework capable of unied mod-
elling, transformation, querying, and evolution management of
multi-model data and to leverage AI techniques to optimize data
distribution among the database systems.
VLDB Workshop Reference Format:
Jáchym Bártík. AI-Powered Orchestration of Multi-Model Data. VLDB 2024
Workshop: VLDB Ph.D. Workshop.
1 INTRODUCTION
More than 2/3 of the 50 most widely used database management
systems (DBMSs)
1
fall under the category of multi-model
.
2
The
multi-model data is organised in various mutually interlinked for-
mats and models, often with contradictory features [
17
]. In addition,
its structure may change over time, and its size can grow to the
extremes of Big Data. These aspects create one of the most complex
challenges of eective data management.
As handling such a complex task manually is impossible, we
focus on the automatic management of dynamic multi-model Big
Data. We want to create a robust framework capable of accepting
dierent types of data, queries, changes, and propagation strategies.
Based on such rich input, the system will learn to provide self-
adapting evolution management, ensuring a complete, correct, and
ecient propagation of changes. Particularly, it will support the
following features:
•
Multi-Model Modeling: We need to model the data in one
unied and formally backed schema. The model can either
(1) be created manually or (2) automatically inferred from
sample data. We can also combine these approaches, i.e.,
infer a reasonable schema and then manually improve it.
•
Multi-Model-to-Multi-Model Transformations: Transforma-
tion from one model to another is a simple process. But, we
must be able to migrate the data between dierent combina-
tions of models represented by dierent database systems.
This work is licensed under the Creative Commons BY-NC-ND 4.0 International
License. Visit https://creativecommons.org/licenses/by-nc-nd/4.0/ to view a copy of
this license. For any use beyond those covered by this license, obtain permission by
emailing info@vldb.org. Copyright is held by the owner/author(s). Publication rights
licensed to the VLDB Endowment.
Proceedings of the VLDB Endowment. ISSN 2150-8097.
1
https://db-engines.com/en/ranking
2
I.e., consisting of multiple data models (relational, document, graph, .. . ).
•
Cross-Model Querying: We need to query over the whole
dataset, not just a single database system. Also, the queries
should be independent of the underlying data models so that
we can use the same query language for the whole system
and thus not force the user to learn dierent languages.
•
Multi-Model Evolution Management: As we have mentioned,
each system evolves over time, whereas in the case of multi-
model data, the evolution must cover all combined models.
Primarily, we want to be able to update the model, the data
itself, and the queries. And, when possible, automatically.
Several solutions have already implemented these features, many
of which are widely used. However, they all have one thing in com-
mon: they are either tightly coupled with the underlying database
systems or too limited to fully model multi-model data. For example,
the UML and ER models are industry standards. But, they cannot
generally model complex properties, maps, or graphs.
Outline. In Section 2, we discuss the current functionalities of our
framework consisting of a family of tools. In Section 3, we describe
our planned steps. In Section 4, we outline the open problems.
2 INITIAL FRAMEWORK
In our research group, we have proposed several solutions to se-
lected aspects of unied and ecient multi-model data management.
We have also implemented tools for their experimental verication.
This toolset represents the initial framework we currently intend
to enhance by exploiting AI to automate data management.
First, we needed a suciently abstract approach to handle all
the conicting requirements because we deal with varied data
models and database systems. Therefore, we proposed a system-
independent representation based on category theory [
12
]. We can
view a category as a directed multigraph for simplicity. The nodes
(called objects) represent entities, and the edges (called morphisms)
represent relationships between them. For example, object
𝐴
repre-
sents a User and object
𝐵
represents a Name. Then, we can have
a morphism
𝑓
:
𝐴 → 𝐵
, meaning that a User has a Name. We can
create structures representing arrays, sets, weak-entity types, etc.
In our framework, we call such category a schema category.
This unifying representation enables us to “grasp” any combina-
tion of models and to process it in a system-independent manner.
When a particular operation has to be done at this abstract level, it
is propagated to the underlying database system.
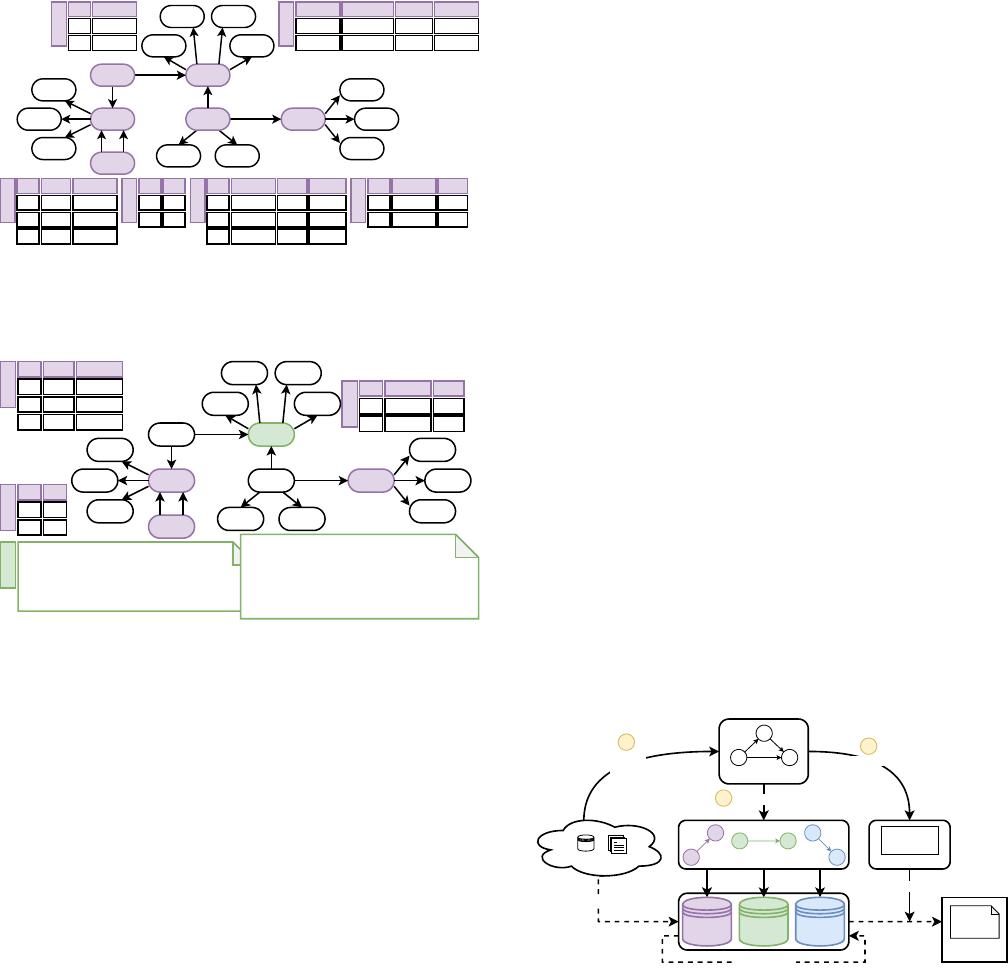
Example 2.1. An example of a schema category can be found in Fig. 1.
The schema category is mapped only to the relational database model
(denoted using the violet colour). On the other hand, in Fig. 2, we can see
the same schema category after an evolution of the mapping. It is now
mapped to relational (violet) and document (green) models. □
id name surname
1 Mary Smith
2 John Newlin
3 Anne Maxwell
Customer
id1 id2
1 2
1 3
Knows
quantity
1
1
2
priceoid
3502023001
2502023001
2023002 275
pid
P5
P7
P7
Items
pid title price
P5 Sourcery 350
P7 Pyramids 275
Product
Order
{oid}
Product
{pid}
street city
postCode
price quantity
oid
pid
title
price
Items
{oid,pid}
6
7 8
9
10 11
14
15
16
Customer
{id}
name
id
surname
Knows
{id,id}
Ordered
{id,oid}
1
2
3
4 5
13
18
12
17
Ordered
Order
oid
2023001
2023002
id
1
2
oid
2023001
2023002
street
Ke Karlovu
Technická
city postCode
Prague 110 00
Prague 162 00
Figure 1: A sample schema category. Each violet node repre-
sents a complex object. In this case, all of them are mapped
to respective tables of the relation model, e.g., PostgreSQL.
id name surname
1 Mary Smith
2 John Newlin
3 Anne Maxwell
{ _id : 2023002,
customer: { id: 2, name: John, surname: Newlin},
street: Technická, city: Prague, postCode : 162 00,
items: [
{ pid: P7, title: Pyramids, quantity: 1, price: 275 }
] }
pid title price
P5 Sourcery 350
P7 Pyramids 275
id1 id2
1 2
1 3
{ _id : 2023001,
customer: { id: 1, name: Mary, surname: Smith},
street: Ke Karlovu, city: Prague, postCode: 110 00,
items: [
{ pid: P5, title: Sourcery, quantity: 1, price: 350 },
{ pid: P7, title: Pyramids, quantity: 1, price: 250 }
] }
Customer
Knows
Product
Order
Order
{oid}
Product
{pid}
street city
postCode
price quantity
oid
pid
title
price
Items
6
7 8
9
10 11
14
15
16
Customer
{id}
name
id
surname
Knows
{id,id}
Ordered
1
2
3
4 5
13
18
12
17
Figure 2: The example schema categor y from Fig. 1 after an
evolution. The schema category did not change, but the af-
fected tables (Items and Orders) were replaced by a collection
of documents (Order), e.g., in MongoDB. The change intro-
duced redundancy to query orders more eciently.
Our toolset involves two tools that enable the creation of a
schema category: MM-cat [
14
] enables the modelling of the schema
category manually, as well as the creation of its decomposition and
mapping of the selected components to particular logical models.
MM-infer [
13
] enables one to infer a schema category from the
given sample multi-model data (semi-)automatically.
2.1 Transformations
As indicated in the introduction, not only do we need to be able
to model the multi-model data using a unied representation, but
we also need to be able to transform them. In particular, we need a
support for transforming any combination of the (sub-)models to
any other combination of (sub-)models.
For this purpose, as a part of MM-cat, we have developed algo-
rithms that leverage mapping between the schema category and the
logical models to transform data between them [
12
]. To work with
each database system in the same way, we have to create wrappers
for each of them. Then, we can use the same algorithm to transform
data between any two database systems.
This is an important distinction from other approaches. For ex-
ample, the ETL (Extract-Transform-Load) process is usually tightly
coupled with the underlying database systems. In our solution, we
can use the same algorithm to transform data between any two
database systems, even multi-model ones. Another example are
data lakehouses which can store data in multiple (single-model)
formats, but they do not provide a unied way to work with them.
2.2 Querying
Querying the data is an essential feature of any database. However,
this is a much more challenging task in multi-model databases as
each system has its own set of supported models and their com-
binations [
17
] and a specic query language [
4
]. There is no gen-
eral standard for multi-model querying except for the standards
SQL/XML [7] and SQL/JSON [8] for relational/document models.
We have proposed the Multi-Model Query Language (MMQL), a
query language based on the SPARQL syntax that enables one to
query over the schema category. Then, within a tool called MM-
quecat [
11
], we developed the query-evaluation algorithm that uses
a similar approach as the transformation algorithms: First, the query
is parsed and mapped to the schema category. Then, we use the
mappings to split it into query parts that can be executed in the
specic underlying systems. We perform the maximum amount of
work in the databases, minimising cross-database joins. Finally, we
combine the intermediate results.
The global workow with the indicated functionalities of the ini-
tial framework is depicted in Fig. 3. First, the schema category is
inferred from sample data or modelled manually. Then, it has to
be decomposed into the system-specic sub-models. Finally, the
user can specify queries over the schema category. All these actions
require user input. On the other hand, all data transformations and
query resolutions are automated.
Query translation
Querying
Modeling
Inference
Loading
Decomposition
Data sources
Schema category
Logical schema
U
U
U
Postgres Neo4jMongo
Transformations
SELECT {
?o customer ?c ;
...
}
Queries
Query results
order: {
customer: 1,
oid: 2023001,
...
}
Figure 3: Workow of the initial framework. The full arrows
represent the ow of information with the
U
symbols mark-
ing user inputs. The dashed lines represent the ow of data.
2.3 Evolution Management
On the most basic level, evolution means changing a database
schema over time. However, when the schema changes, the data
and the queries must also be updated. Thus, in the context of our
framework, we do not see evolution as just another feature but as
a fundamental quality of each part of the system.
of 4
免费下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

文档被以下合辑收录
评论