




VLDB2024_Native Distributed Databases:Problems, Challenges and Opportunities_OceanBase.pdf
免费下载

Native Distributed Databases: Problems, Challenges and
Opportunities
Quanqing Xu
OceanBase, Ant Group
xuquanqing.xqq@oceanbase.com
Chuanhui Yang
∗
OceanBase, Ant Group
rizhao.ych@oceanbase.com
Aoying Zhou
East China Normal University
ayzhou@dase.ecnu.edu.cn
ABSTRACT
Native distributed databases, crucial for scalable applications, of-
fer transactional and analytical prowess but face data intricacies
and network challenges. Under the CAP theorem’s constraints,
latency and replication issues necessitate creative approaches to
maintenance, security, and upgrades. Progress in consistency al-
gorithms, network technology, automation, and machine learning
for optimization presents signicant potential. Embracing hybrid
transactional/analytical processing (HTAP), these databases repre-
sent an evolutionary leap in data management, aiming to reconcile
performance with the complexities inherent in distributed envi-
ronments. OceanBase is introduced as a case study, and its strong
TPC-C and TPC-H benchmark performances underscore Ocean-
Base as a top-tier distributed database. We also discuss possible
opportunities for native distributed databases.
PVLDB Reference Format:
Quanqing Xu, Chuanhui Yang, and Aoying Zhou. Native Distributed
Databases: Problems, Challenges and Opportunities. PVLDB, 17(12): 4217 -
4220, 2024.
doi:10.14778/3685800.3685839
1 INTRODUCTION
Native distributed databases are built to scale across intercon-
nected nodes, ensuring high availability and resilience against fail-
ures [
16
]. They use advanced replication algorithms (e.g., Raft [
20
]
and Paxos [
13
]) for data synchronization while preserving ACID
properties, essential for eliminating single points of failure. Such
databases, e.g., Google Spanner [
1
] and OceanBase [
30
], provide
robust solutions for consistency, data partitioning, and manage-
ment. Their capability to handle heavy data demands makes them
vital for businesses operating over distributed networks, oering
scalable, fault-tolerant database systems.
They excel in distributed computing, scaling elastically and en-
suring data durability with sophisticated replication. Designed
around the CAP theorem, they balance consistency, availability, and
partition tolerance, making them ideal for extensive, reliable data
management across vast computing environments. As they evolve,
these databases are incorporating cloud technologies and machine
learning to enhance scalability and reliability, adeptly meeting both
transactional and analytical needs [
16
]. They mark a new phase in
∗
Chuanhui Yang is the corresponding author.
This work is licensed under the Creative Commons BY-NC-ND 4.0 International
License. Visit https://creativecommons.org/licenses/by-nc-nd/4.0/ to view a copy of
this license. For any use beyond those covered by this license, obtain permission by
emailing info@vldb.org. Copyright is held by the owner/author(s). Publication rights
licensed to the VLDB Endowment.
Proceedings of the VLDB Endowment, Vol. 17, No. 12 ISSN 2150-8097.
doi:10.14778/3685800.3685839
data management systems, crucial for modern, scalable infrastruc-
ture demands, embodying resilience and eciency.
The proliferation of data and an increased reliance on robust
data management systems emphasize the signicance of native
distributed databases in modern technological ecosystems. They
are instrumental in revolutionizing data management by optimiz-
ing scalability and availability, beneting from the agility of cloud
technologies and the predictive power of machine learning. By sup-
porting both transactional and analytical processes, these databases
signify a shift towards more streamlined, cost-eective, and ca-
pable data management solutions, poised to meet the escalating
requirements for scalable and fault-tolerant data infrastructures.
We present a 1.5-hour tutorial, which is divided into seven
sections as follows: 1) Overview of Native Distributed Data-
base (
∼
5min). It oers scalable, resilient, and ecient large-scale
data management. 2) Data Replication and Synchronization
(
∼
15min). Distributed databases maintain data integrity through
advanced replication despite failures. 3) Consistency Models
(
∼
15min). It describes a variety of consistency models, ranging
from strict consistency to eventual consistency. 4) Distributed
Transactions (
∼
15min). It discusses distributed transactions by
ensuring atomicity, consistency, isolation, and durability (ACID)
across multiple nodes in a distributed environment. 5) Query Pro-
cessing (
∼
15min). It focuses on query processing by distributing
and executing queries eciently across various nodes, optimiz-
ing for reduced network latency and strategic data placement. 6)
Case Study: OceanBase (
∼
10min). It describes that OceanBase
oers a high-performance, scalable, shared-nothing architecture,
excelling in OLTP/OLAP integration. 7) Opportunities (
∼
15min).
Embracing Serverless architecture [
3
], AI4DB and DB4AI [
17
,
35
],
multi-model [
16
], and vector database capabilities [
9
], it presents
opportunities for unprecedented scalability, autonomous operation,
and versatile data handling in modern computing environments.
Target Audience. The intended audience includes database re-
searchers, developers, and students who aspire to study database
kernel techniques, as well as database administrators (DBAs) who
desire to better tune their database systems. The tutorial is self-
contained and does not require any prerequisite knowledge.
2 TUTORIAL OUTLINE
2.1 Overview of Native Distributed Database
Native distributed databases oer unied systems with high avail-
ability, fault tolerance, scalability, and performance across multiple
nodes and locations. Key problems of native distributed databases in-
clude: 1) Data Replication and Synchronization: These databases
handle synchronization among nodes to keep replicas up-to-date,
which is crucial for data accuracy and disaster recovery. 2) Consis-
tency Models: They oer various consistency models ranging from
4217
strong consistency to eventual consistency, allowing the system to
balance between consistency, availability, and partition tolerance
as dictated by the CAP theorem. 3) Distributed Transactions:
Support for transactions across multiple nodes is often provided,
although it may come with trade-os in terms of performance and
scalability. 4) Query Processing: They can execute queries across
nodes eciently, often optimizing query execution plans to mini-
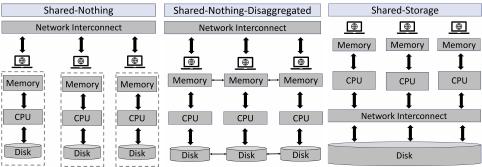
mize network trac and data movement. Table 1 outlines dierent
mechanisms of popular distributed databases, and Figure 1 illus-
trates three distinct architectures of native distributed databases.
(a) Shared-Nothing (b) Shared-Nothing Disaggr. (c) Shared-Storage
Figure 1: Architectures of Native Distributed Databases
2.2 Data Replication and Synchronization
2.2.1 Data Replication. Replication in distributed databases strikes
a balance between synchronous methods, which ensure immediate
consistency but result in slower writes, and asynchronous methods,
which allow for faster access but may introduce data discrepancies.
The level of replication—be it at the row, block, or le level—is
chosen based on specic needs. Asynchronous replication resolves
conicts using timestamps or custom logic to ensure data accu-
racy. Techniques like asymmetric-partition replication can reduce
system load [
15
], whereas solutions like BatchDB [
18
] improve
OLTP/OLAP workloads by pairing logical replication with a lazy
strategy for enhanced performance.
2.2.2 Data Synchronization. Distributed databases balance consis-
tency and performance using models like eventual consistency [
12
],
which tolerates short-term discrepancies for assured long-term ac-
curacy. Data sync frequency and network latency [
26
] are crucial
to this consistency, inuencing system design for performance op-
timization. Moreover, to handle simultaneous transactions and data
conicts, strategies such as version control and timestamp [
29
] help
maintain orderly data sync and ensure steadfast consistency.
2.2.3 Challenges. In distributed databases, especially those span-
ning wide areas, data synchronization is essential but challenged
by bandwidth limits, network latency and uctuation, aecting
eciency and performance [
24
]. Optimizing bandwidth and main-
taining swift recovery post-failure are crucial for data integrity and
loss prevention. Ensuring transactional consistency amid partitions
and securing data against unauthorized changes during replication
are key hurdles. However, as demands for performance rise, evolv-
ing technologies are progressively tackling these issues, enhancing
the robustness and reliability of distributed database systems.
2.3 Consistency Mo dels
The data consistency models in distributed databases crucially im-
pact performance, reliability, and availability, as depicted in Figure 2.
2.3.1 Strong and Eventual Consistency. Strong consistency in dis-
tributed systems ensures that operations are immediately visible
and executed in sequence, providing a seamless experience but
potentially limiting performance due to the need for node syn-
chronization. Systems such as Calvin [
26
], PolarDB [
28
], and Ge-
oGauss [
34
] have improved transactional eciency and replication
to deliver this consistent state without signicantly aecting speed
or scalability. In contrast, eventual consistency allows for short-
term data anomalies in exchange for better responsiveness, with
systems like Dynamo [
5
] managing high-performance demands
through application-level conict resolution. BlockchainDB [
8
] in-
novatively combines the exibility of databases with the strength
of blockchain technology to oer a range of consistency levels, thus
optimizing data management for a variety of operational contexts.
2.3.2 Other Consistency Models. Causal consistency improves upon
eventual consistency by ensuring causally related operations fol-
low the same order across nodes, while independent operations
are not strictly ordered. Eciency gains come from minimizing
dependency checks and dening external causal relationships [
2
].
GentleRain [
7
] increases throughput with time-based protocols and
uses physical timestamps to save on storage and communication.
Orbe [
6
] leverages dependency matrices and transitive causality
for eective causal consistency in key-value systems. Achieving
strong consistency in partitioned, replicated systems is challenging.
Google Spanner [
1
] clusters servers and uses Paxos for log repli-
cation within groups, maintaining a consistent prex order across
data replicas to uphold its consistency standard.
2.3.3 Challenges. Choosing the right consistency for distributed
databases is crucial for balancing performance, availability, and
precision. Financial systems often require strong consistency, while
CDNs may opt for eventual consistency, accepting brief data discrep-
ancies. The CAP theorem advises a trade-o between consistency,
availability, and partition tolerance, inuenced by application needs.
Databases like OceanBase [
32
] adapt consistency options for diverse
scenarios. Data replication, key for fault tolerance, faces latency
issues with synchronous methods and potential inconsistency with
asynchronous ones. Developers must navigate these complexities
to ensure optimal system performance and data reliability.
2.4 Distributed Transactions
2.4.1 Distributed Transaction Commit Protocols. Native distributed
databases employ distributed transaction commit protocols to up-
hold the ACID properties across distributed nodes, ensuring data
integrity and consistency. The 2PC protocol is a classic example, op-
erating in two distinct stages. ROCOCO [
19
] optimizes this process
by treating transactions as collections of atomic blocks, tracking
dependencies before execution to allow for serializable ordering
upon commit. Primo [
11
] avoids concurrency conicts by ensuring
transactions are conict-free after the commit phase. We proposed
OceanBase 2PC [
30
], a Paxos-enhanced 2PC protocol, to strengthen
fault tolerance and reduce transaction latency in distributed envi-
ronments, streamlining synchronizations for eciency.
2.4.2 Distributed Version Control. One of the core principles of
SAP HANA is full support for distributed query capabilities and
horizontal expansion [
14
]. It employs MVCC to provide distributed
4218
of 4
免费下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

文档被以下合辑收录
评论