




VLDB2024_NeutronStream:A Dynamic GNN Training Framework with Sliding Window for Graph Streams_华为.pdf
免费下载

NeutronStream: A Dynamic GNN Training Framework with
Sliding Window for Graph Streams
Chaoyi Chen
Northeastern
University, China
chenchaoy@
stumail.neu.edu.cn
Dechao Gao
Northeastern
University, China
gaodechao@
stumail.neu.edu.cn
Yanfeng Zhang
Northeastern
University, China
zhangyf@
mail.neu.edu.cn
Qiange Wang
Northeastern
University, China
wangqiange@
stumail.neu.edu.cn
Zhenbo Fu
Northeastern
University, China
fuzhenbo@
stumail.neu.edu.cn
Xuecang Zhang
Huawei Technologies
Co., Ltd.
zhangxuecang@
huawei.com
Junhua Zhu
Huawei Technologies
Co., Ltd.
junhua.zhu@
huawei.com
Yu Gu
Northeastern
University, China
guyu@
mail.neu.edu.cn
Ge Yu
Northeastern
University, China
yuge@
mail.neu.edu.cn
ABSTRACT
Existing Graph Neural Network (GNN) training frameworks have
been designed to help developers easily create performant GNN
implementations. However, most existing GNN frameworks assume
that the input graphs are static, but ignore that most real-world
graphs are constantly evolving. Though many dynamic GNN mod-
els have emerged to learn from evolving graphs, the training process
of these dynamic GNNs is dramatically dierent from traditional
GNNs in that it captures both the spatial and temporal dependencies
of graph updates. This poses new challenges for designing dynamic
GNN training frameworks. First, the traditional batched training
method fails to capture real-time structural evolution information.
Second, the time-dependent nature makes parallel training hard to
design. Third, it lacks system supports for users to eciently im-
plement dynamic GNNs. In this paper, we present NeutronStream,
a framework for training dynamic GNN models. NeutronStream
abstracts the input dynamic graph into a chronologically updated
stream of events and processes the stream with an optimized sliding
window to incrementally capture the spatial-temporal dependen-
cies of events. Furthermore, NeutronStream provides a parallel
execution engine to tackle the sequential event processing chal-
lenge to achieve high performance. NeutronStream also integrates
a built-in graph storage structure that supports dynamic updates
and provides a set of easy-to-use APIs that allow users to express
their dynamic GNNs. Our experimental results demonstrate that,
compared to state-of-the-art dynamic GNN implementations, Neu-
tronStream achieves speedups ranging from 1.48X to 5.87X and an
average accuracy improvement of 3.97%.
PVLDB Reference Format:
Chaoyi Chen, Dechao Gao, Yanfeng Zhang, Qiange Wang, Zhenbo Fu,
Xuecang Zhang, Junhua Zhu, Yu Gu, Ge Yu. NeutronStream: A Dynamic
GNN Training Framework with Sliding Window for Graph Streams.
PVLDB, 17(3): 455 - 468, 2023.
doi:10.14778/3632093.3632108
This work is licensed under the Creative Commons BY-NC-ND 4.0 International
License. Visit https://creativecommons.org/licenses/by-nc-nd/4.0/ to view a copy of
this license. For any use beyond those covered by this license, obtain permission by
emailing info@vldb.org. Copyright is held by the owner/author(s). Publication rights
licensed to the VLDB Endowment.
Proceedings of the VLDB Endowment, Vol. 17, No. 3 ISSN 2150-8097.
doi:10.14778/3632093.3632108
PVLDB Artifact Availability:
The source code, data, and/or other artifacts have been made available at
https://github.com/iDC-NEU/NeutronStream.
1 INTRODUCTION
Graph Neural Networks (GNNs) [
6
,
18
,
26
,
30
,
52
,
60
,
62
,
64
,
69
] are
a class of deep learning models designed to learn from graph data.
GNNs have been widely adopted in various graph applications, in-
cluding social networks analytics [
8
,
59
], recommendation systems
[
35
,
67
], and knowledge graphs [
39
,
49
]. Most of the existing GNN
models assume that the input graph is static. However, real-world
graphs are inherently dynamic and evolving over time. Recently,
many dynamic GNN models [
20
,
27
,
28
,
34
,
45
,
51
,
57
,
63
,
79
] are
emerged as a promising method for learning from dynamic graphs.
These models capture both the spatial and temporal information,
which makes them outperform traditional GNNs in real-time ap-
plications, such as real-time fraud detection [
57
], real-time recom-
mendation [20], and many other tasks.
In dynamic GNNs, the dynamic graph is modeled as a sequence
of time-stamped events, each event representing a graph update
operation. Each event is associated with a timestamp indicating
when it occurs and an update type, e.g., an addition/deletion of a
node/edge or an update of a node/edge’s feature. Dynamic GNNs
encode the information of each event into dynamic node embed-
dings chronologically. The training process of dynamic GNNs is
dramatically dierent from traditional GNNs in that it has to con-
sider the temporal dependency of events. Existing dynamic GNNs
[
19
,
28
,
51
] are implemented on top of general DNN training frame-
works, e.g., Tensorow [
5
] and PyTorch [
41
]. However, the complex
spatial-temporal dependencies among events pose new challenges
for designing dynamic GNN frameworks.
First, the traditional batched training mode adopted by exist-
ing DNN frameworks may fail to capture the real-time structural
evolution information. Batched training mode periodically packs
new arrival events into a training batch and trains the model using
these batches incrementally. However, this method forcibly cuts
o the stream and ignores the spatial locality between events in
two consecutive batches, which may lead to a decrease in model
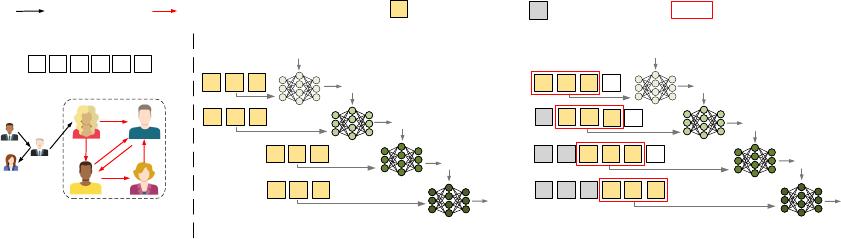
accuracy. Figure 1(a) illustrates a motivating example on a dynamic
social network graph, which contains six consecutive interaction
455
. . .
(b) Batched training
(c) Sliding-window based training
1
e
2
e
3
e
4
e
5
e
6
e
1
e
2
e
3
e
1
e
2
e
3
e
4
e
1
e
2
e
3
e
4
e
5
e
1
e
2
e
3
e
4
e
5
e
6
e
1
e
2
e
3
e
4
e
5
e
6
e
(0)
W
Update event stream
1
e
2
e
3
e
4
e
5
e
6
e
Training event Dropped event
Sliding window
An event with edge updateInitial edge
1
e
2
e
3
e
4
e
5
e
6
e
4
e
5
e
6
e
(a) Dynamic graph
(0)
W
(1)
W
(3)
W
(4)
W
(2)
W
(1)
W
(2)
W
(3)
W
(4)
W
Figure 1: Traditional batched training vs. sliding-window based training for graph streams.
events concentrated in the rectangular area. In the batched training
mode, as shown in Figure 1(b), these six events with spatial locality
are split into two independent batches. With an initial parameter
matrix
𝑊
(0)
, the rst batch with events
{𝑒
1
, 𝑒
2
, 𝑒
3
}
is trained in
two epochs, and the parameter matrix is updated twice to obtain
𝑊
(2)
. The second batch with events
{𝑒
4
, 𝑒
5
, 𝑒
6
}
is then trained in
two epochs to obtain
𝑊
(4)
. In this way, the spatial dependency
between cross-batch events (e.g.,
𝑒
3
and
𝑒
4
) cannot be captured,
thereby impacting the model accuracy.
Second, the sequential nature of time-dependent events makes
parallelism optimization hard to design. The existing open-source
dynamic GNN implementations [
19
,
28
,
51
] are based on the ma-
ture DNN or GNN frameworks (e.g., Pytorch [
41
] and DGL[
55
]).
They adopt vanilla sequential iterative processing, which suers
from sub-optimal performance and can hardly benet from modern
parallel architectures. For example, the DyRep [
51
] implementation
in PyTorch takes 60.45 seconds with a single thread for an epoch on
the GitHub dataset [
4
], but it takes 60.89 seconds with 20 threads,
which is even longer than single-thread execution, indicating the
lack of parallelization support.
Third, there lacks a user-friendly programming abstraction for
implementing dynamic GNNs. The training of dynamic GNNs
highly relies on ecient dynamic storage for maintaining dynamic
graphs, which is not a standard module in traditional GNN frame-
works. Users have to implement their own store to maintain graph
topology and multi-versioned embeddings. For example, in the
Dyrep [
51
] model, users have to implement data structures to sup-
port the storage of timestamps, the update of graph and node em-
beddings, and complex graph operations such as accessing a node’s
neighbor nodes and their embeddings. This requires much redun-
dant coding work and is error-prone. Therefore, it is desirable to
have a set of specic APIs for implementing dynamic GNNs and
an ecient framework that supports common modules used in
dynamic GNN training.
To address the above problems for dynamic GNN training, we
make the following contributions.
Contribution 1. We propose a new incremental learning mode
with a sliding window for training on graph streams. We rely on a
sliding window to select consecutive events from the graph stream
feeding to the model training. The window is sliding as new update
events arrive and the processed stale events outside of the window
can be dropped, so that the freshness of the model can be guaranteed
and the evolving information and temporal dependencies can be
well captured. For example, in Figure 1(c), a window of 3 events as
training samples are trained for one epoch, and then the window
slides with a sliding stride of 1. The window size can be adaptively
adjusted for capturing the complete spatial dependencies.
Contribution 2. We propose a ne-grained event parallel exe-
cution scheme. We leverage the observation that each event only
aects a small subgraph, and there is no read-write conict between
multiple events if their aected subgraphs do not intersect. Based
on this observation, we build a dependency graph analysis method
that identies the events having no node-updating conicts and
processes them in parallel. In this way, training performance can
be enhanced through ne-grained event parallelism.
Contribution 3. We deliver a dynamic GNN training framework
NeutronStream. NeutronStream integrates sliding-window training
method and dependency-graph-driven event parallelizing method.
Moreover, NeutronStream integrates a built-in graph storage struc-
ture that supports dynamic updates and provides a set of easy-to-
use APIs that allow users to express their dynamic GNNs with
lightweight engineering work.
We evaluate NeutronStream on three popular dynamic GNN
models, DyRep, LDG, and DGNN. The experimental results demon-
strate that our optimized sliding-window-based training brings
0.46% to 6.31% accuracy improvements. Compared with their open-
sourced implementations on PyTorch, NeutronStream achieves
speedup ranging from 1.48X to 5.87X.
2 PRELIMINARIES
2.1 Graph Neural Networks
GNNs operating on graph-structured data aim to capture the topol-
ogy and feature information simultaneously. Given the input graph
𝐺 = (𝑉 , 𝐸)
along with the features of all nodes
𝑧
(0)
, GNNs stack
multiple graph propagation layers to learn a representation for
each node. In each layer, GNNs aggregate the neighbor informa-
tion from the previous layer, following an AGGREGATE-UPDATE
computation pattern:
ℎ
(𝑙 )
𝑣
= AGGREGATE
{𝑧
(𝑙 −1)
𝑢
| (𝑢, 𝑣) ∈ 𝐸},𝑊
(𝑙 )
𝑎
, (1)
𝑧
(𝑙 )
𝑣
= UPDATE
𝑧
(𝑙 −1)
𝑣
, ℎ
(𝑙 )
𝑣
,𝑊
(𝑙 )
𝑢
, (2)
where
𝑧
(𝑙 )
𝑣
represents the embedding of node
𝑣
in the
𝑙
-th layer.
The
AGGREGATE
operation collects and aggregates the embedding
of
𝑣
’s incoming neighbors to generate the intermediate aggregation
result
ℎ
(𝑙 )
𝑣
. The
UPDATE
operation uses
ℎ
(𝑙 )
𝑣
and the
(𝑙 −
1
)
-th layer
456
of 14
免费下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

文档被以下合辑收录
评论