




VLDB2024_UniView:A Unified Autonomous Materialized View Management System for Various Databases_华为.pdf
免费下载

UniView: A Unified Autonomous Materialized View Management
System for Various Databases
Zhenrong Xu, Pengfei Wang
Zhejiang University
Hangzhou, China
{xuzhenrong,wangpf}@zju.edu.cn
Guoze Xue, Qitong Yan
Zhejiang University
Hangzhou, China
{xuegz,qitong.yan}@zju.edu.cn
Shenghao Gong, Yelan Jiang
Zhejiang University
Hangzhou, China
{gongshenghao,jiangyelan}@zju.edu.cn
Yuren Mao, Yunjun Gao
Zhejiang University
Hangzhou, China
{yuren.mao,gaoyj}@zju.edu.cn
Shu Shen, Wei Zhang, Dan Luo
Huawei
Hangzhou, China
{shenshu,zhangwei09,luodan2}@huawei.com
Lu Chen
Zhejiang University
Hangzhou, China
luchen@zju.edu.cn
ABSTRACT
Materialized views (MVs) are critical for improving query perfor-
mance of database systems, especially in online analytical process-
ing (OLAP) databases. Typically, MVs are maintained by DBAs,
which relies on prior knowledge and manual operations. Recently,
autonomous solutions are designed for specic databases. How-
ever, a data warehouse for OLAP is typically hierarchical, which
uses dierent database engines at dierent stages. Hence, existing
methods have limitations in terms of autonomy and unication to
support practical applications.
Motivated by these, we develop UniView, a unied autonomous
materialized view management system that supports various popu-
lar databases, including Spark SQL, PostgreSQL, and ClickHouse.
Moreover, we provide a cross-platform web user interface, where
users can carry out the process of materialized views and evaluate
the optimization performance. In the demonstration, we show that
UniView is user-friendly and can achieve superior performance in
the practical industry scenarios.
PVLDB Reference Format:
Zhenrong Xu, Pengfei Wang, Guoze Xue, Qitong Yan, Shenghao Gong,
Yelan Jiang, Yuren Mao, Yunjun Gao, Shu Shen, Wei Zhang, Dan Luo,
and Lu Chen. UniView: A Unied Autonomous Materialized View
Management System for Various Databases. PVLDB, 17(12): 4353 - 4356,
2024.
doi:10.14778/3685800.3685873
PVLDB Artifact Availability:
The source code, data, and/or other artifacts have been made available at
https://github.com/ZJU-DAILY/UniView.
1 INTRODUCTION
Materialized views (MVs) are of critical importance to the query
performance of database systems. As shown in Figure 1, we can
materialize a view to speed up the query process. In online analyti-
cal processing (OLAP) databases, many SQL queries share common
This work is licensed under the Creative Commons BY-NC-ND 4.0 International
License. Visit https://creativecommons.org/licenses/by-nc-nd/4.0/ to view a copy of
this license. For any use beyond those covered by this license, obtain permission by
emailing info@vldb.org. Copyright is held by the owner/author(s). Publication rights
licensed to the VLDB Endowment.
Proceedings of the VLDB Endowment, Vol. 17, No. 12 ISSN 2150-8097.
doi:10.14778/3685800.3685873
OrderKey CustKey TotalPrice OrderDate Name Address Zipcode
0001 0001 10.0 09152022 A E 310024
0002 0002 100.0 09152022 B F 310023
0003 0004 50.0 09152022 C G 310024
0004 0003 2000.0 09152022 D H 310020
Select Order.TotalPrice
From View
Where Zipcode=310024
Select Order.TotalPrice
From Orders, Custormers
Where Oders.CustKey = Custormers.CustKey
AND Zipcode=310024
View
Figure 1: An example of materialized views.
subqueries and there are lots of redundant computations among
these queries. Materializing views on these subqueries can avoid
redundant computation and improve query performance, which is
a space-for-time trade-o principle. Therefore, it is vital to select
the optimal MVs that can bring the most query performance im-
provement within a space budget. For example, in Amazon Redshift,
automated materialized views are a powerful tool for improving
query performance.
Most existing methods rely on DBAs to generate and maintain
MVs [
3
]. Nevertheless, these methods require prior knowledge and
manual operations, which are costly, and thus, cannot eciently
and eectively support large-scale databases. Motivated by this,
autonomous MV selection methods are proposed recently. The MV
selection process within a space budget can be regarded as a 0-
1 integer linear programming (0-1 ILP) problem. Solving 0-1 ILP
is too expensive for large workloads since the complexity of the
0-1 ILP approach is
𝑂 (
2
𝑛
)
. To eciently solve the MV selection,
two lines of methods exist. One line of MV selection methods is
heuristics, such as the greedy strategy [
1
,
2
]. Another line of studies
uses reinforcement learning (RL) [
3
,
4
,
7
,
10
] or graph algorithm [
5
]
to solve the 0-1 ILP problem faster.
There exist many works[
3
,
4
,
6
,
7
,
9
–
11
] that leverage ML meth-
ods to solve database problems, indicating a growing trend.
However, existing automatic MV selection methods are designed
for specic database systems, e.g., DQM [
6
] designed for Spark
SQL, AutoView [
3
] designed for PostgreSQL, DBMind [
11
] designed
for OpenGauss, and SOFOS [
8
] designed for knowledge graphs.
4353
Cost
Workload
I.MV Generation
Database Engine
II.Cost Estimation
III.MV Recommend
IV.MV Rewriting
DNN
Training
DNN
Testing
Materialize Rewriting
RL
Greedy
Strategy
AST
Figure 2: UniView system architecture.
Figure 3: MV generation algorithm.
Their customized design makes them highly coupled and hard to
migrate to other databases. In real life applications, dierent types of
database systems are typically used at dierent stages. For example,
a data warehouse hierarchical uses dierent database engines (e.g.,
Spark SQL and Clickhouse) at dierent stages for decision-making.
Hence, a unied management system is preferred to support various
popular databases while materializing views autonomously.
In this demonstration, we develop UniView, a unied autonomous
materialized view management system for various databases. Specif-
ically, UniView consists of four phases: (i) MV Generation aims to
parse the queries and generate candidate views; (ii) Cost Estimation
utilizes the deep network to estimate the cost of queries and MVs;
(iii) MV Recommend aims to recommend the optimal MVs within
a space budget based on the cost; and (iv) MV Rewriting aims at
rewriting the query using the most appropriate views. UniView
supports three dierent types of database systems, i.e., Spark SQL,
PostgreSQL and ClickHouse. We also provide a cross-platform web
UI, where users can submit queries and get recommended views
to materialize. The web UI can demonstrate the dierence in ex-
ecution performance of queries with/without materialized views
so that users are able to understand better how UniView improves
the query performance. Moreover, UniView has been deployed in
the Huawei Consumer Business Group (CBG) to manage materi-
alized views for query performance improvement. We summarize
the contributions as follows:
•
We demonstrate UniView, a unied autonomous materi-
alized view management. To the best of our knowledge,
UniView is the rst autonomous materialized view manage-
ment supporting various popular databases simultaneously.
•
We implement a cross-platform web UI to interact with
users and demonstrate the improvements brought by Uni-
View. We have open-sourced UniView, and it is available
at GitHub https://github.com/ZJU-DAILY/UniView.
•
UniView has been deployed in Huawei CBG to improve
query eciency. Our preliminary results show that Uni-
View is able to reduce query execution time using recom-
mended materialized views, which veries the eectiveness
of UniView in the real-world industry scenario.
The rest of the paper is organized as below. Section 2 presents
system overview. Section 3 provides demonstration overview. Sec-
tion 4 makes conclusions with promising future directions.
2 SYSTEM OVERVIEW
We rst oer some preliminaries of UniView, and then, we present
the system architecture and a detailed workow of UniView.
2.1 Preliminaries
We rst introduce the query tree to represent a SQL query, based
on which, materialized view management is present.
Query Tree. Given a SQL query
𝑞
, we parse it as a query tree (ab-
stract syntax tree, AST). Each subtree rooted at a node corresponds
to a subquery, and each node indicates an operator. All subqueries
except the leaves in the query tree can be materialized as views.
Materialized View Management. Given a query workload
𝑄
,
there exists a set
V
of candidate MVs. It is vital to select a subset
𝑉
∗
⊆ V
to materialize within a given space budget
𝜏
, which can
minimize the total execution time of the query workload.
2.2 Workow
Figure 2 illustrates the overall system architecture of UniView. It
is composed of four phases, namely, (i) MV generation, (ii) cost
estimation, (iii) MV recommend, and (iv) MV rewriting.
MV Generation aims to nd common subqueries for generating
candidate MVs
V
. First of all, we parse all SQL queries in the query
workload
𝑄
as query trees. Common subqueries are the equivalent
subtrees among dierent query trees of queries. After nding all
common subqueries, we are able to generate
V
. Specically, we
compute the qualities of all common subqueries. The qualities are
formulated as the weighted sum of some important factors, e.g., the
number of MV that matched the original queries, the size of the table
that the MV contains, and the number of predicates. After that, the
common subqueries with high qualities will be selected as candidate
MVs
V
. Our UniView supports three popular databases, including
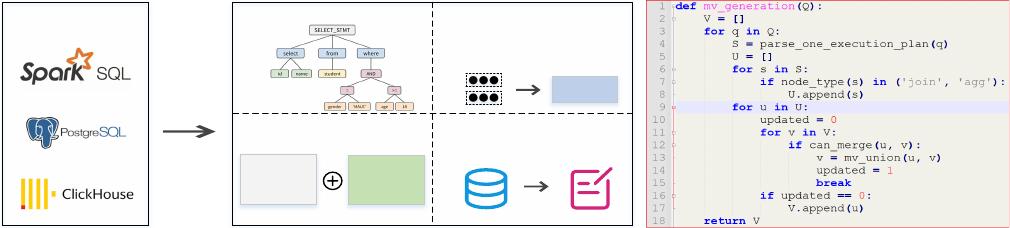
Spark SQL, PostgreSQL, and ClickHouse. Figure 3 illustrates the
abstract code of MV generation for Spark SQL, PostgreSQL, and
ClickHouse. Note that, since execution plan structures and operator
types generated by dierent database engines are dierent, it is
required to customize the analysis of the execution plans for the
three databases.
Cost Estimation aims at conducting cost estimation to estimate
the benet, including the execution time and the space cost. The
benet estimation is the dierence between the cost of a query
and the corresponding rewritten query. We also estimate the space
cost (i.e., storage cost) of each MV candidate. We adopt a deep
4354
of 4
免费下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

文档被以下合辑收录
评论