




VLDB2024_Galaxybase:A High Performance Native Distributed Graph Database for HTAP_创邻科技.pdf
免费下载

Galaxybase: A High Performance Native Distributed Graph
Database for HTAP
Bing Tong
CreateLink & HKUST(GZ)
tongbing@createlink.com
btong799@connect.hkust-gz.edu.cn
Yan Zhou
∗
CreateLink
zhouyan@createlink.com
Chen Zhang
CreateLink
zhangchen@createlink.com
Jianheng Tang
HKUST(GZ)
jtangbf@connect.ust.hk
Jing Tang
HKUST(GZ)
jingtang@ust.hk
Leihong Yang
CreateLink
yangleihong@createlink.com
Qiye Li
CreateLink
liqiye@createlink.com
Manwu Lin
CreateLink
linmanwu@createlink.com
Zhongxin Bao
CreateLink
baozhongxin@createlink.com
Jia Li
∗
HKUST(GZ)
jialee@ust.hk
Lei Chen
HKUST(GZ)
leichen@ust.hk
ABSTRACT
We introduce Galaxybase, a native distributed graph database that
addresses the increasing demands for processing large volumes of
graph data in diverse industries like nance, manufacturing, and
government. Designed to handle the requirements of both trans-
actional and analytical workloads, Galaxybase stands out with its
novel data storage and transaction mechanisms. At its core, Galaxy-
base utilizes a Log-Structured Adjacency List coupled with an Edge
Page structure, optimizing read-write operations across a spectrum
of tasks such as graph traversals and single edge queries. A no-
table aspect of Galaxybase is its execution of custom distributed
transaction modes tailored for HTAP transactions, allowing for the
facilitation of bidirectional and interactive transactions. It ensures
data integrity and minimal latency while enabling simultaneous
processing of OLTP and OLAP workloads without blocking. Ex-
perimental results show that Galaxybase achieves high throughput
and low latency in both OLTP and OLAP workloads, across var-
ious graph query scenarios and resource conditions. Galaxybase
has been deployed in leading banks, education, telecommunica-
tion and energy sectors in China, consistently maintaining robust
performance for HTAP workloads over the years.
PVLDB Reference Format:
Bing Tong, Yan Zhou, Chen Zhang, Jianheng Tang, Jing Tang, Leihong
Yang, Qiye Li, Manwu Lin, Zhongxin Bao, Jia Li, and Lei Chen. Galaxybase:
A High Performance Native Distributed Graph Database for HTAP. PVLDB,
17(12): 3893 - 3905, 2024.
doi:10.14778/3685800.3685814
* Corresponding Authors.
This work is licensed under the Creative Commons BY-NC-ND 4.0 International
License. Visit https://creativecommons.org/licenses/by-nc-nd/4.0/ to view a copy of
this license. For any use beyond those covered by this license, obtain permission by
emailing info@vldb.org. Copyright is held by the owner/author(s). Publication rights
licensed to the VLDB Endowment.
Proceedings of the VLDB Endowment, Vol. 17, No. 12 ISSN 2150-8097.
doi:10.14778/3685800.3685814
1 INTRODUCTION
A graph database [
37
] is a type of database management system
specically designed to store, manage, and query complex rela-
tionships between data entities. Unlike conventional relational
databases, graph databases employ vertices, edges, and proper-
ties to model data entities and their relationships. It allows for
enhanced exibility and performance in handling structured and
highly interconnected data, making them particularly well-suited
for applications in elds such as social networking [
8
,
10
,
17
,
32
],
energy network optimization [
24
,
42
], nancial fraud detection
[23, 34, 40], and knowledge graphs [7, 41].
Many graph databases encounter performance challenges in
processing graph queries and transactions due to their design or
functional limitations. Non-native databases often use established
non-graph backends. For example, A1 [
11
] utilizes Key-Value stores.
Titan [
1
] and its successor, JanusGraph [
3
], are based on the wide-
column store, while ArangoDB [
2
] and OrientDB [
36
] employ doc-
ument stores for graph representation. Although non-native graph
storages rely on mature non-graph backends like HBase [
19
], which
are well-understood operationally, they typically struggle with han-
dling ecient graph-specic queries, particularly in graph traversal
scenarios. Conversely, native graph databases with their index-free
adjacency, such as Neo4j [
5
] and TigerGraph [
16
], signicantly
enhance traversal performance. However, Neo4j exhibits poor scal-
ability and struggles to meet high throughput and low latency
requirements on trillion-scale graphs. TigerGraph, focusing on in-
memory architectures, encounters diculties with large graphs in
low-memory environments. Additionally, native graph databases
also fall short of single edge queries, as they rely on traversal to
locate a specic edge.
Beyond handling graph-specic queries, another vital feature of
graph databases is their ability to preserve integrity and correctness
during concurrent operations in various scenarios. A key capability
3893
is the dual support for Online Transaction Processing (OLTP) and
Online Analytical Processing (OLAP). Our usage statistics show
that 70% of tasks involve Hybrid Transaction/Analytical Processing
(HTAP) [
33
], 20% are dedicated to OLTP, and the remaining 10%
to OLAP. Among existing systems, G-Tran [
14
] is notably adept at
OLTP tasks and prioritizes transactional integrity, while Grasper
[
13
] excels in managing OLAP transactions. However, using sepa-
rate systems for distinct OLTP and OLAP tasks can double costs in
terms of development, deployment, and maintenance.
Faced with the unique challenges of processing graph queries
and transactions, we developed Galaxybase
1
, a new native dis-
tributed graph database. Galaxybase features two distinct storage
structures, optimized for read and write performance. The rst is a
Log-Structured Adjacency List, which employs adjacency lists for
sequential data scanning and batch writing to reduce read/write
amplications. The second structure, Edge Page, co-locates edges
for the same vertex and maintains local order within each page
by type and direction while ensuring global order across all edges.
This design supports ecient graph traversal in various directions
and types, as well as quick and accurate single edge queries.
As a distributed graph database deployed in production-grade
environments, Galaxybase is designed to handle a variety of sce-
narios and data scales eectively. It supports transactions using
Two-Phase Commit (2PC) [
26
,
38
] and Raft [
30
] protocols to en-
sure atomicity and durability. The system maintains isolation levels
from read-committed to serializable for OLTP workloads using
Two-Phase Locking (2PL) [
22
]. Galaxybase integrates bidirectional
and interactive transactions, aligning with the unique storage struc-
tures and user demands of graph databases. For OLAP workloads, it
employs Multi-Version Concurrency Control (MVCC) [
35
] visibility
checks with lock-free mechanisms to maintain serializable snapshot
isolation.
Our experiments with OLTP and OLAP workloads demonstrate
that Galaxybase delivers strong performance in both single-machine
and distributed setups. It achieves throughput of up to 50,000
queries per second (q/s) in single-machine mode and 85,000 q/s in
distributed mode, signicantly surpassing baseline graph databases.
In terms of scalability, Galaxybase achieves throughput that is
up to an order of magnitude higher than that of baseline graph
databases. It also shows eciency in edge queries, operating three
times faster than its closest competitor. Furthermore, Galaxybase
handles queries eectively in low-memory environments, enabling
large graph loading and complex query execution without out-of-
memory issues. Additionally, we processed a trillion-scale dataset
that includes 5 billion account vertices and 5 trillion transaction
edges using only 50 machines, each equipped with 12 CPUs and
128GB of memory, achieving multi-hop query results in seconds.
In tracing these endeavors, our paper consolidates the following
contributions:
•
We introduce Galaxybase, a high-performance, native distributed
graph database designed specically for HTAP scenarios. It pro-
vides an ecient, robust, and scalable solution for managing
complex graph data.
1
https://www.createlink.com
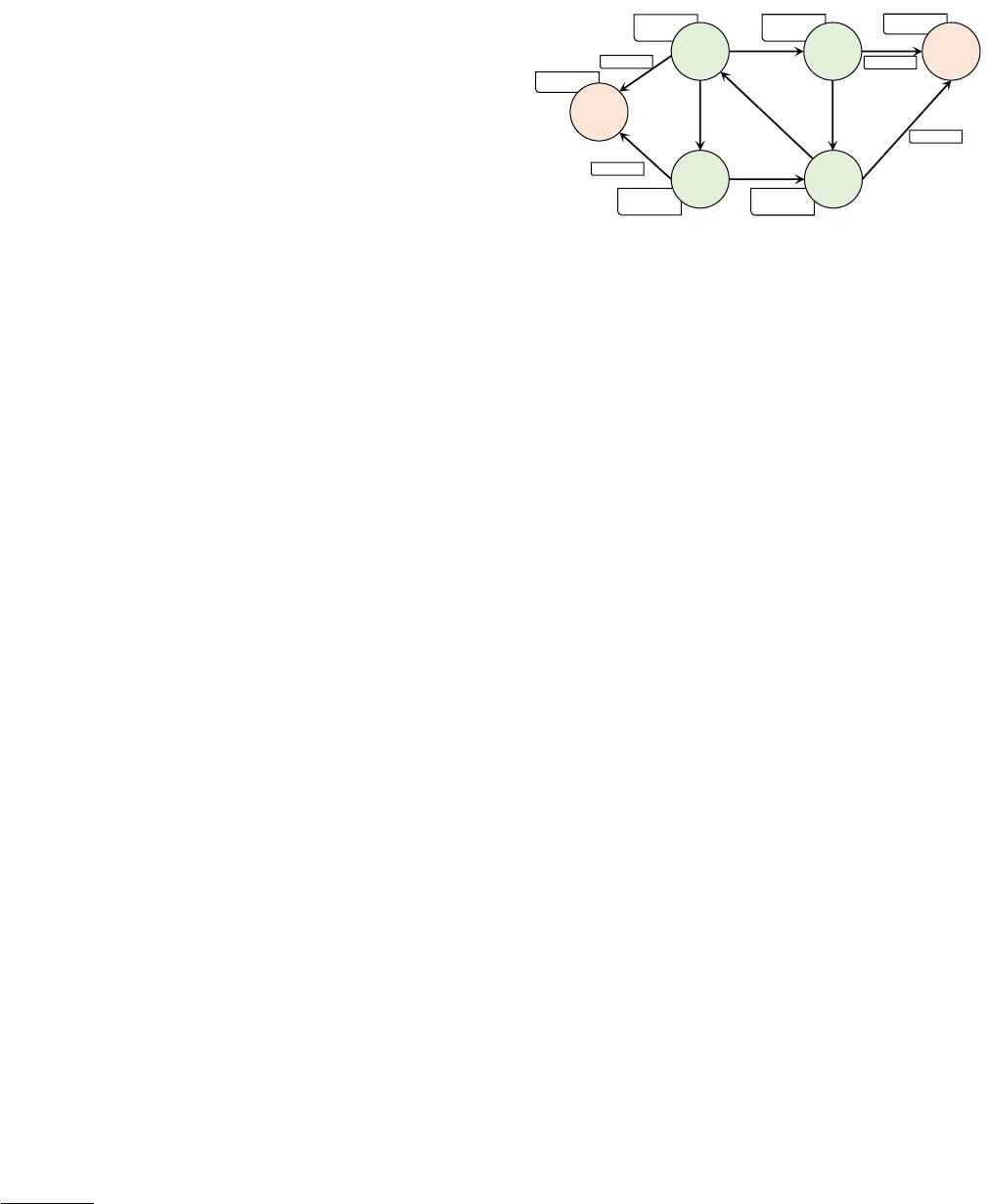
locatedIn
follows locatedIn
TIME: 20200315
NAME: UK
NAME: Cindy
AGE: 7
NAME: Alice
AGE: 18
NAME: Bob
AGE: 25
NAME: David
AGE: 20
NAME: China
follows follows
follows
follows
TIME: 20160820
locatedIn
TIME: 20190728
locatedIn
TIME: 20201102
person_1 person_2
person_3 person_4
country_1
country_2
Figure 1: An example of property graph
•
On the storage front, we propose the Log-Structured Adjacency
List, an approach for sequential disk reads and writes that dra-
matically reduces read/write amplications. Complementing this,
our Edge Page design enhances graph traversal eciency, allow-
ing for the eective handling of edges in various directions and
types, while also enabling quick and accurate single edge queries.
•
On the transaction front, we implement distributed transactions
for OLTP workloads using bidirectional and interactive methods.
Additionally, we manage OLAP workloads with lock-free meth-
ods, allowing OLTP and OLAP workloads to run concurrently
without causing blocks.
•
In the distributed mode, Galaxybase achieves a throughput of
up to 85,000 queries per second in OLTP workloads, and its
performance in OLAP workloads exceeds competitors by an
order of magnitude. This high eciency is sustained even under
restricted memory resources, enabling the execution of complex
queries in environments with limited capacity.
2 BACKGROUND AND DESIGN PRINCIPLE
Reecting on the challenges and limitations of current graph databases
outlined in Section 1, this section delves into the motivation and
key factors in crafting Galaxybase. Our primary objective is to
build a unied system that demonstrates exceptional performance,
availability, scalability, and robust transaction capabilities.
Galaxybase utilizes the property graph model [
6
], where vertices
and edges can possess a variety of properties. Based on this model,
we develop a Ming Dynasty literature knowledge graph for univer-
sities to enhance literary research and teaching, build a power grid
knowledge graph for the State Grid to ensure accurate and stable
power dispatch strategies, and implement a nancial fraud detection
graph for banks to enhance security and more eectively identify
fraudulent activities. As illustrated in Figure 1, in a social network
using the property graph model, each vertex/edge is assigned a
type (e.g.,
person
,
country
,
follows
,
locatedIn
), alongside a set
of properties (e.g., NAME:Alice and TIME:20201102).
Graph databases organize data through edges, oering the signif-
icant advantage of native and ecient support for graph traversal
queries. These queries navigate the graph from a specied vertex
to a predetermined depth or target vertex. For example, as depicted
in Figure 1, a graph traversal query starting from vertex
person_1
with a depth of 1 and a relational constraint of
follows
would
identify all followers of
person_1
. Relational databases depend
3894
of 13
免费下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

文档被以下合辑收录
评论