




VLDB2024_Towards Resource Efficiency:Practical Insights into Large-Scale Spark Workloads at ByteDance_字节跳动.pdf
免费下载
Towards Resource E�iciency: Practical Insights into
Large-Scale Spark Workloads at ByteDance
Yixin Wu
∗
ByteDance Inc.
Xiuqi Huang
∗
Shanghai Jiao Tong
University
Zhongjia Wei
ByteDance Inc.
Hang Cheng
ByteDance Inc.
Chaohui Xin
ByteDance Inc.
Zuzhi Chen
ByteDance Inc.
Binbin Chen
ByteDance Inc.
Yufei Wu
ByteDance Inc.
Hao Wang
ByteDance Inc.
Tieying Zhang
ByteDance Inc.
Rui Shi
†
ByteDance Inc.
Xiaofeng Gao
Shanghai Jiao Tong
University
Yuming Liang
ByteDance Inc.
Pengwei Zhao
ByteDance Inc.
Guihai Chen
Shanghai Jiao Tong
University
ABSTRACT
At ByteDance, where we execute over a million Spark jobs and
handle 500PB of shued data daily, ensuring resource eciency
is paramount for cost savings. However, achieving optimization of
resource eciency in large-scale production environments poses
signicant challenges. Drawing from our practical experiences, we
have identied three key issues critical to addressing resource ef-
ciency in real-world production settings:
¨
slow I/Os leading to
excessive CPU and memory idleness,
≠
coarse-grained resource
control causing wastage, and
Æ
sub-optimal job congurations
resulting in low utilization. To tackle these issues, we propose a
resource eciency governance framework for Spark workloads.
Specically,
¨
we devise the multi-mechanism shue services, in-
cluding Enhanced External Shue Service (ESS) and Cloud Shue
Service (CSS), where CSS employs a push-based approach to en-
hance I/O eciency through sequential reading.
≠
We modify the
Spark conguration parameter protocol, allowing for ne-grained
resource control by introducing several new parameters such as
milliCores and memor yBurst, as well as supporting operators with
additional spill modes.
Æ
We design a two-stage conguration auto-
tuning method, comprising rule-based and algorithm-based tuning,
providing more reliable Spark conguration optimizations. By de-
ploying these techniques on millions of Spark jobs in production
over the last two years, we have achieved over 22% CPU utilization
increase, 5% memory utilization increase, and 10% shue block
time ratio decrease, eectively saving millions of CPU cores and
petabytes of memory daily.
PVLDB Reference Format:
Yixin Wu, Xiuqi Huang, Zhongjia Wei, Hang Cheng, Chaohui Xin, Zuzhi
Chen, Binbin Chen, Yufei Wu, Hao Wang, Tieying Zhang, Rui Shi,
Xiaofeng Gao, Yuming Liang, Pengwei Zhao, and Guihai Chen. Towards
Resource Eciency: Practical Insights into Large-Scale Spark Workloads at
ByteDance. PVLDB, 17(12): 3759 - 3771, 2024.
doi:10.14778/3685800.3685804
∗
Yixin Wu and Xiuqi Huang contributed equally to this work.
†
Dr. Rui Shi is the corresponding author, shirui@bytedance.com.
This work is licensed under the Creative Commons BY-NC-ND 4.0 International
License. Visit https://creativecommons.org/licenses/by-nc-nd/4.0/ to view a copy of
this license. For any use beyond those covered by this license, obtain permission by
emailing info@vldb.org. Copyright is held by the owner/author(s). Publication rights
licensed to the VLDB Endowment.
Proceedings of the VLDB Endowment, Vol. 17, No. 12 ISSN 2150-8097.
1 INTRODUCTION
At ByteDance, Apache Spark [
10
] is the most widely used compute
engine for large-scale data processing, with more than 1.7 million
Spark jobs executed daily by various teams across the company.
Despite several prior attempts [
21
,
35
,
37
,
41
] to optimize Spark
workloads, such large-scale and diverse applications at ByteDance
bring unique and complex challenges to resource eciency.
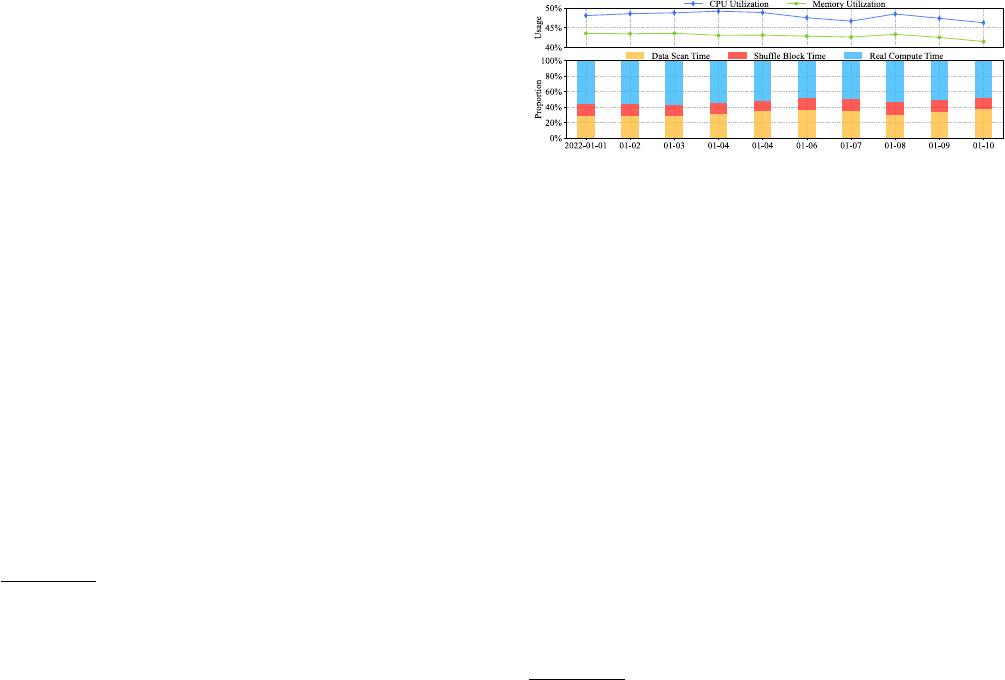
Figure 1: An Example of Production Resource Eciency- It
shows ByteDance’s resource utilization for millions of Spark jobs in
the rst 10 days of 2022. Data scan and shule block time consume
more than 45% of the total compute time. The average CPU utiliza-
tion is 47.98% and the memory utilization is 42.95%.
In Figure 1, we show the resource utilization and time proportion
of ByteDance production workloads before implementing resource
eciency enhancements, where CPU and memory utilization re-
mains in a low range. Primary factors that impact resource e-
ciency include Hadoop Distribute File System (HDFS) slowness,
shue fetch failures [
34
], coarse-grained resource control [
38
] and
sub-optimal job congurations [
24
]. This highlights the primary
directions for our work towards resource eciency, including reduc-
ing slow I/Os, rening resource control, and tuning conguration
parameters. However, previous methods [
7
,
15
,
21
,
24
] are not su-
cient to handle the large-scale Spark workloads at ByteDance, as
the following special challenges need to be addressed.
¨
Expensive I/O costs. Spark’s data scan and shue oper-
ations are both resource-intensive and time-consuming. On the
one hand, when reading remote data from HDFS, waiting for I/O
operations causes certain periods of CPU and memory idleness.
On the other hand, Spark’s External Shue Service (ESS) shares
doi:10.14778/3685800.3685804
3759
the disk resources with other computing processes on the same
node, which may result in fetch failures due to high disk pressure.
Moreover, as a single ESS process serves all of the intermediate
shue data on a compute node, the abnormality of a single job can
potentially exacerbate faults and impact other shue tasks on the
same node. Although some approaches [
15
,
32
,
34
,
42
] have been
proposed to improve shue eciency, they cannot meet stability
and performance needs at our scale.
≠
Coarse-grained resource control. With the explosive growth
in Spark workloads, there is an urgent need to further enhance the
resource eciency of production clusters by reducing both resource
allocation and actual usage. Previous methods are mostly focused
on choosing server specications to match jobs’ demands [
7
,
37
] or
combining resource utilization and cost as the optimization goal [
5
],
which is hard to handle resource requirements variation of dierent
stages. Although Spark provides stage-level resource settings using
ResourceProle [
8
], adoption is hindered by the required changes
to user code and the lack of support for SQL. Besides, Spark’s min-
imum granularity of resource allocation is one CPU core, that a
task is allocated at least one core, p otentially resulting in inecient
CPU and memory utilization.
Æ
Sub-optimal Spark conguration. Confronted with diverse
business needs, manually setting the appropriate parameters for
Spark jobs is extremely time-consuming, given the varying charac-
teristics and resource demands of Spark applications. In large-scale
production clusters, job interference, bandwidth uctuations, and
workload changes further increase the diculty for automatic con-
guration tuning methods to adapt to various applications and a
dynamic production environment. However, the majority of con-
guration tuning methods focus on performance optimizations
[
4
,
22
,
24
,
41
,
44
], with relatively fewer approaches considering
resource eciency [
5
,
21
], particularly rare [
35
] enabling Spark’s
dynamic allocation feature [11].
Our Methodologies. We design a resource eciency gover-
nance framework for Spark workloads. This framework is designed
to enhance the stability, performance, and resource utilization of
Spark jobs through a series of techniques implemented from the
bottom up. Among them, there are three main techniques to solve
the above challenges.
¨
We provide multi-mechanism shue ser-
vices to improve the stability of shue and reduce I/O delay.
≠
We design a ne-grained resource control mechanism to accurately
adjust job resource allocations according to their actual usage.
Æ
We devise a two-stage conguration auto-tuning method to provide
appropriate parameters for various jobs. These three techniques
work in tandem to improve the overall resource eciency of Spark
workloads. In particular, the multi-mechanism shue ser vices free
up idle CPU and wasted memory caused by slow shues, which
are then leveraged by ne-grained resource control and two-stage
conguration tuning.
Contribution. For large-scale Spark workload, we summarize
four key contributions are as follows:
•
Based on the characteristics of ByteDance production clusters,
we design the multi-mechanism shue services which include
Enhanced ESS with request throttling and executor rolling, as
well as a push-based Cloud Shue Service (CSS). This design
improves shue stability and eciency, signicantly reducing
shue fetch failures and shue block time. (Sec. 3)
•
We enable ne-grained resource control by modifying underly-
ing Spark core modules by introducing new CPU and memory
allocation parameters. Also, we support additional spill modes for
Spark operators to reduce memory footprint and out-of-memory
(OOM) failures. (Sec. 4)
•
We establish an end-to-end online tuning pipeline, which em-
ploys a two-stage conguration auto-tuning method combining
both rule-based and algorithm-based tuning. This method is
most eective for enhancing CPU and memor y utilization in
production environments while prioritizing stability. (Sec. 5)
•
These techniques have been widely applied across ByteDance
production clusters, yielding a signicant improvement in re-
source eciency. Over 1.7 million Spark jobs, we have improved
CPU utilization from 48% to over 70% and memory utilization
from 43% to 50%. During the month of March 2024, we have
optimized more than 530,000 jobs, reducing the average job exe-
cution time by 11.1 minutes, with over 1 million CPU cores and
4.6 PB memory saved daily. (Sec. 6)
2 OVERVIEW AND SYSTEM DESIGN
In this se ction, we provide an overview of Spark at ByteDance and
our proposed resource eciency governance framework.
2.1 Overview of Spark at ByteDance
Figure 2 illustrates the lifecycle of a Spark application. Upon a user’s
submission, a driver initializes and interprets the submitted appli-
cation into multiple jobs, and generates a Directed Acyclic Graph
(DAG) for each job. Each DAG, consisting of various stages requir-
ing data shuing in between, is scheduled by the DAGScheduler.
Each stage consists of parallel tasks performing identical functions,
all of which are scheduled to execute on executors. Both executors
and ESS run on containers allocated in the clusters managed by
Yodel (YARN on Gödel [
40
]). Typically, the active tasks interact with
the HDFS for data scanning. Below, we provide detailed background
information pertinent to the Spark jobs at ByteDance.
At ByteDance, clusters are categorized into two types: dedicated
and mixed. Dedicated clusters, equipped with solid-state disks (SSD),
oer stable resources for high-priority jobs. Despite SSDs oering
improved I/O performance, maintaining shue stability in large-
scale workloads still remains challenging. Mixed clusters, on the
other hand, share disk resources with various services, such as on-
line services and HDFS. The sharing leads to increased competition
for disk I/Os and capacity, which exacerbates shue stability issues.
Gödel, a resource management and scheduling system based
on Kubernetes [
3
], is deployed across the aforementioned clusters,
oering a unied computing infrastructure and resource pool. Prior
to Gödel’s deployment, cluster resources were managed by YARN.
To facilitate the smo oth transition of Spark from YARN to Kuber-
netes, Yodel was developed, providing a YARN-compatible interface
atop Gödel. These Yodel clusters, with tens of millions of CPU cores,
are responsible for processing large-scale Spark workloads.
With over 1.7 million daily Spark applications, of which 75%
are periodic jobs, optimizing Spark congurations to improve uti-
lization and performance is crucial for our company. However,
3760
of 13
免费下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

文档被以下合辑收录
评论