




VLDB2024_ResLake:Towards Minimum Job Latency and Balanced Resource Utilization in Geo-distributed Job Scheduling_字节跳动.pdf
免费下载

ResLake: Towards Minimum Job Latency and Balanced Resource
Utilization in Geo-distributed Job Scheduling
Xinchun Zhang*, Aqsa Kashaf*, Yihan Zou*, Wei Zhang*, Weibo Liao, Haoxiang Song, Jintao Ye,
Yakun Li, Rui Shi, Yong Tian, Wei Feng, Binbin Chen, Zuzhi Chen, Tieying Zhang, Yongping Tang
ByteDance
reslake-paper@bytedance.com
ABSTRACT
At internet scale companies like ByteDance, data is generated and
consumed at enormously high speed by many dierent applications.
Achieving low latency on such big data jobs is an important problem.
However, the naive approach of aggregating all the data required by
a job to a single location is not always feasible in a geo-distributed
environment. Similarly, existing approaches in ge o-distributed job
scheduling often try to minimize WAN usage, which may come at
the cost of latency. Another crucial element to ensure low latency is
resource load balancing among DCs, which enables exibility in job
scheduling and avoids resource bottlenecks. Therefore, to minimize
latency, optimizing job completion time (JCT) while maintaining
resource utilization balance is important. To this end, we propose
ResLake, a global scheduling platform for data-intensive workloads.
ResLake aims to reduce JCT of geo-distribute d applications while
balancing the compute (CP U/Memory) and storage (Disk) usages
across DCs and eciently using WAN interconnections. We have
deployed ResLake in ByteDance’s production for over 1.5 years.
ResLake has scheduled billions of jobs since its deployment. We
nd that ResLake improves JCT of jobs by at least 20%, and can
improve resource utilization balance across DCs by up to 53%.
PVLDB Reference Format:
Xinchun Zhang, Aqsa Kashaf, Yihan Zou, Wei Zhang, Weibo Liao,
Haoxiang Song, Jintao Ye, Yakun Li, Rui Shi, Yong Tian, Wei Feng,
Binbin Chen, Zuzhi Chen, Tieying Zhang, Yongping Tang. ResLake:
Towards Minimum Job Latency and Balanced Resource Utilization in
Geo-distributed Job Scheduling. PVLDB, 17(12): 3934 - 3946, 2024.
doi:10.14778/3685800.3685817
1 INTRODUCTION
Digital technological advancements have led to the rapid growth
and proliferation of data. As a result, internet-scale companies like
ByteDance are seeing an increasing growth of data-intensive appli-
cations that collect, process, and analyze enormous amounts of data
to help them gain useful insights. These internet-scale companies
deploy tens of data centers (DCs) across multiple regions in the
world to provide low-latency service to their customers. At these
geographically distributed sites, data is generated and consumed at
This work is licensed under the Creative Commons BY-NC-ND 4.0 International
License. Visit https://creativecommons.org/licenses/by-nc-nd/4.0/ to view a copy of
this license. For any use beyond those covered by this license, obtain permission by
emailing info@vldb.org. Copyright is held by the owner/author(s). Publication rights
licensed to the VLDB Endowment.
Proceedings of the VLDB Endowment, Vol. 17, No. 12 ISSN 2150-8097.
doi:10.14778/3685800.3685817
an enormously high speed by many dierent applications. Ensur-
ing low latency for these data-intensive jobs is important to meet
service level agreements (SLAs), and to enhance user experience.
Existing big data processing frameworks such as Hadoop [
3
],
Spark [
36
], Flink [
7
] and Dryad [
17
] have been designed to analyze
large datasets eciently. However, all these frameworks assume
a single-DC deployment, where network resources are typically
uniform and readily accessible, making these solutions infeasible for
geo-distributed data analysis. To extend to multiple DCs, a trivial
solution would be to aggregate all the data in a single lo cation for
processing. However, it is often impractical due to the following
reasons. First, the job may have many inputs, whose total data
size may be very challenging for storage space in any DC. Second,
these data may only be used once, resulting in a waste of resources.
Moreover, for high availability, data needs to be replicated and
stored at multiple remote DCs to prevent data loss during incidents.
Recent eorts have tried to build on these frameworks to en-
able data analytics across multiple DCs [
14
,
28
,
30
,
31
]. However,
these frameworks are not optimized for the wide-area network
(WAN) bandwidth heterogeneity and limitations [
27
]. Other works
assume that dierent DCs have uniform computational resources,
which does not conform to the reality [
16
]. Other approaches that
perform geo-distributed job scheduling for big data jobs seek to op-
timize WAN usage [15, 30] as they are designed for a public cloud
environment where WAN resources can easily become a bottle-
neck. However, in a private cloud environment such as ByteDance,
network resources are often over-provisioned. Since WAN usage
optimization can often come at the cost of latency, these approaches
do not directly account for low latency.
Hence, to optimize job completion time (JCT) for geo-distributed
big data jobs, we propose ResLake. ResLake is a global schedul-
ing platform for data-intensive workloads, which in addition to
reducing JCT, also aims to balance the compute (CPU/memory) and
storage (Disk) utilization across DCs and eciently use the WAN
interconnections. We believe that ensuring a balanced resource
utilization is crucial for optimizing JCT, as it enables more exible
scheduling and prevents resource bottlenecks that may increase la-
tency. To design ResLake, we formulate the job scheduling problem
as a joint optimization problem that minimizes JCT and maximizes
resource utilization balance. In the JCT minimization part, we divide
the entire scheduling task into meta-tasks, which can b e scheduled
individually to avoid unnecessary resource blocking. Also, ResLake
frequently updates each resource’s processing rate to ensure the
accuracy of overall approximate JCT. To formulate the resource
utilization balance as an optimization problem, we aim to ensure
that the resource utilization of each cluster is close to the average
cluster utilization. We design ResLake as a layered system. The core
3934
function of the control layer of ResLake is to perform job schedul-
ing. The compute, storage, and network layers in ResLake support
the control layer, and ensure execution of the decisions made by
the control layer. Moreover, these layers also provide necessary
information to the control layer that aids in scheduling jobs.
ResLake has been deployed in ByteDance’s infrastructure for
over 1.5 years. We evaluate the eectiveness of ResLake on our
production, with an emphasis on achieving its goals of improving
average JCT and resource utilization balance across DCs. We present
the results for 3 core DCs in ByteDance’s infrastructure. We nd that
ResLake improves the JCT by 20% on average. More than 70% of the
jobs show gains in JCT with ResLake, and more than 50% of these
jobs show JCT gains of more than 60%. ResLake improves the CPU
utilization balance by up to 53% and memory utilization balance by
up to 71%. Moreover, as a result of ResLake, the variability in cross-
DC read trac is reduced by 50%. Since its deployment, ResLake
has successfully scheduled millions of jobs and has covered almost
100% of big data processing jobs at ByteDance.
We now summarize the main contributions of this work.
•
We formulate the problem of minimizing job completion times in
a private cloud environment while maintaining resource balance
across DCs.
•
We propose an end-to-end system that implements our problem
formulation and uses workload characteristics to motivate the
design of ResLake.
• We deploy a production-ready system for geo-distributed DCs.
•
We show that ResLake improves JCT by over 20% and resource
utilization imbalance by over 53%.
Paper Outline The remainder of this paper is organized as follows:
Sec. 2 gives the basic motivation behind the design goals of ResLake.
Sec. 3 presents a high-level overview of the ResLake infrastructure,
and discusses the main design decisions motivated by our workload
analysis. Sec. 4 presents the formulation of job scheduling at the
control layer of ResLake. Sec. 5 discusses the design of ResLake
in detail followed by its implementation in Sec. 6. In Sec. 7, we
evaluate ResLake and in Sec. 8 we discuss our related work.
2 MOTIVATION
At ByteDance, majority of submitted jobs are big data jobs, which
typically require accessing huge amounts of data of dierent types.
To ensure a good user experience and service level agreement (SLA),
it is important to achieve low latency (or completion time) for jobs.
In this case, a highly performant scheduling system is needed to
manage the scales of jobs and data. For single-DC, in-cluster job
scheduling and data placement are well-studied, and there exists
known solutions, e.g., YARN [
29
] or similar technology. However,
the problem for geo-distributed setup is still somewhat open, as the
design solution is usually company-dependent. In a geo-distributed
environment, the scheduling system needs to take various resources
into consideration. Existing studies [
25
] have shown that compute,
storage, and network have almost the same probability of becoming
performance bottlenecks for data-intensive analysis jobs. As a result,
those approaches considering only one or part of the resources
are insucient due to the dependency between job latency and
resources. Therefore, in this work, we propose a solution that directly
deals with job latency and resource utilization balance.
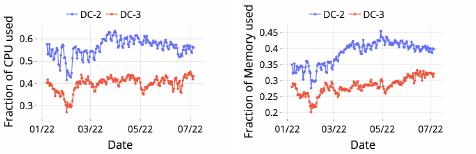
(a) CPU (b) Memory
Figure 1: Resource utilization diers by up to 25% across
dierent DCs before the deployment of ResLake.
2.1 ResLake Goals
Given the aforementioned context, we now explain the main goals
of ResLake.
Reduce Job Completion Times (JCT): JCT is dened as the
time it takes to complete a job after it was rst submitted by the
user. JCT involves the time a job waits for resources, as well as
the time spent in fetching data from a remote DC (see Sec. 4.1 for
more details). Existing works [
15
,
26
] often try to reduce WAN
usage as a proxy for latency. These works mainly consider a public
cloud environment where WAN bandwidth is limited and can easily
become a bottleneck. However, this is not always true in a private
cloud environment for the following reasons:
(1)
For self-hosted private clouds, network infrastructure requires
an extensive period of planning and construction. Oftentimes
there are some degrees of over-provisioning in bandwidth re-
sources;
(2)
Network bandwidth is shared by online services and oine jobs.
Thus, network trac exhibits tidal behavior: day-night trac
patterns of online/oine services can be very dierent. Instead
of minimizing WAN usage at all times, we can harvest the
peak/o-peak trac patterns to improve bandwidth utilization
and resource eciency.
Moreover, solely minimizing WAN usage reduces WAN usage for
all links irrespective of their available bandwidth, while minimizing
JCT may only reduce WAN usage on the bottleneck link of the
network. Therefore, ResLake particularly focuses on reducing JCT
(which considers WAN latency) instead of reducing WAN usage.
Improve Resource Utilization Balance: While minimizing JCT is
important from a user standpoint, it should not come at the cost of
skewed resource utilization among DCs/clusters in the system. Fig. 1
shows that signicant load imbalance can exist in geo-distribute d
systems. Skewed resource utilization poses challenges to placing
jobs/data at their ideal locations, causing negative impacts on JCT.
Fig. 2 illustrates that JCT and CPU/memory resource utilization are
positively correlated. There are two degrees of potential imbalance
in the system. First, utilization imbalance of the same resource
across DCs may result in hot nodes and resource waste. Second,
the imbalance across dierent resources may cause unnecessary
blocking due to the dependency among resources. For instance,
migrating data closer to a job, or a DC with abundant storage re-
sources, is possible only when there is enough network bandwidth
to transfer the data. Hence, ResLake explicitly focuses on balanc-
ing load across DCs and among dierent resources in addition to
minimizing JCTs.
3935
of 13
免费下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

文档被以下合辑收录
评论