




巨杉Tech 读写分离机制与实践.pdf
40墨值下载
巨杉 Tech | 读写分离机制与实践
1.
背景
SequoiaDB
巨杉数据库是一款开源的金融级分布式关系型数据库,主要面对高并发联机交易
型场景提供高性能、可靠稳定以及无限水平扩展的数据库服务。用户可以在
SequoiaDB
巨杉
数据库中创建多种类型的数据库实例,如
MySQL, PostgreSQL
与
SparkSQL
,以满足上层不同
应用程序各自的需求。
在许多业务下,应用对数据库的请求往往读多写少,这时对数据库的读操作首先成为性能瓶 颈。
同时,由于读写同一库会有锁冲突,导致写的性能也会降低。为了解决以上问题,可以 使用读写
分离架构,即将库分为主库和从库,主库用于写数据,而多个从库用于读数据。这 样不仅减少了单
一节点的负载压力,而且会避免锁等待,可以解决数据库很大一部分的读性
能瓶颈。
读写分离典型的使用场景为
HTAP
混合负载场景。
HTAP
混合负载意味着数据库既可以运行
OLTP (Online Transactional Processing) 联 机交易,也 可 以 同 时 运 行 OLAP (Online Analytical
Processing)
统计分析业务。但是,用户想要在同一个数据库中针对同样的数据在同一时刻
运行两种不同类型的业务,往往数据库服务器中的 CPU、内存、I/O 和网络等硬件资源会形
成较多的资源争用,导致对外的联机交易服务性能与稳定性受到影响。在
SequoiaDB
巨杉数据
库中,为了解决资源争用,可以给 OLTP 和 OLAP 业务配置不同的读写分离策略,同时可以
通过创建数据共享但不同类型的数据库实例(例如
MySQL
实例与
SparkSQL
实例),分别服
务于联机交易业务与统计分析业务,做到针对同样数据的联机交易与统计分析业务同时运行且
互不干扰。
2.
读写分离机制
2.1
复制组
在
SequoiaDB
巨杉数据库中,复制组是指一份数据的多个拷贝,其中每一份数据拷贝被称
为副本,也称为节点或实例。
节点有三种类型:
编目节点:保存数据库的元数据信息。
协调节点:接受请求,将请求分发到所需要处理的数据节点。
数据节点:保存用户数据信息。
一个复制组内的节点有两种不同的角色:主节点和备节点,每个节点在复制组内都有一个唯
一
id
,名称为
instanceid
,取值范围为
1-255
。正常情况下,一个复制组内有且只有一个主节
点,其余为备节点。
通常情况下,一个复制组的多个节点放在不同的服务器上,这样可以满足数据库的高可用与 灾备
需求。同时,因为多个节点存放在不同的服务器上,因此可以通过配置策略让读写会话
访问不同
的节点,从而实现读写分离。
SequoiaDB 巨杉数据库的读写分离机制如下图所示:
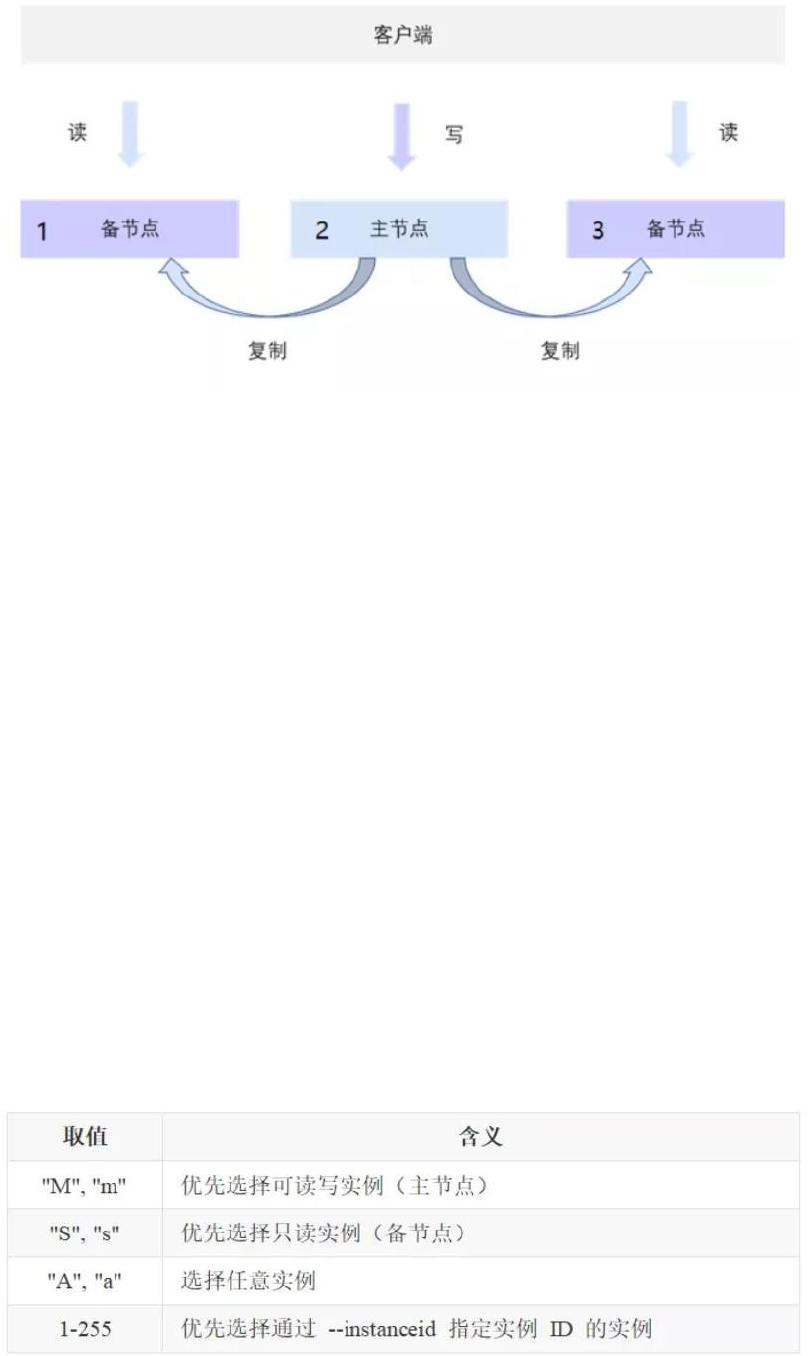
当发生写操作时,主节点写入数据并复制数据到备节点。
当发生读操作时,
SequoiaDB
可以将读请求发送至读写分离策略指定的节点,以降低读写
I/O
冲
突和锁冲突,提升集群整体的吞吐量。读写分离策略可以设置为从主节点读,从备节点读,
以及指定
id
从具体节点读。如上图,三个节点的
id
分别是
1
,
2
,
3
,可以指定只在
3
节点上读数据。
2.2
会话
当数据库客户端建立一个与服务端的连接,并发送一个操作请求后,服务端通常需要保存这 个
操作的上下文信息,如客户端的地址信息、请求的操作类型和操作执行的进度信息等,这
个上下
文就是会话。
在 SequoiaDB 巨杉数据库中,不仅可以给协调节点配置默认的读写分离策略,还可以在会
话级别指定读操作选择的节点,从而使读写分离更加灵活。
2.3
写请求处理
所有的写请求都只会发往主节点。数据写入主节点后记录在事务日志 replicalog。备节点从
主节点异步复制
replicalog
,并通过重放
replicalog
来复制数据。
2.4
读请求处理
读请求可以通过设置会话或协调节点的
PreferedInstance
参数,来控制会话读操作优先选择
的实例。
PreferedInstance 的取值列表为:"M", "m", "S", "s", "A", "a", 1-255。用户可以使用数组指定多
个取值,取值具体含义如下表
:
of 6
40墨值下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

评论