




DASFAA 2024, LNCS 14850, pp. 409–424, 2024. VFDV-IM - An Efficient and Securely Vertical Federated Data Valuation._OceanBase.pdf
免费下载

VFDV-IM:AnEfficient and Securely
Vertical Federated Data Valuation
Xiaokai Zhou
1
,XiaoYan
2
,XinyanLi
1
,HaoHuang
1
,QuanqingXu
3
,
Qinbo Zhang
1
,YenJerome
4
,ZhaohuiCai
1(
B
)
, and Jiawei Jiang
1(
B
)
1
Wuhan University, Wuhan, Hubei Province, China
{xiaokaizhou,xinyan
li,haohuang,qinbo zhang,zhcai,jiawei.jiang}@whu.edu.cn
2
Centre for Perceptual and Interactive Intelligence (CPII), Hong Kong SAR, China
3
OceanBase, Ant Group, China
xuquanqing.xqq@oceanbase.com
4
The University of Macau, Macau, China
jeromeyen@um.edu.mo
Abstract. Vertical federated learning enables multiple participants to
build a joint machine learning model upon distributed features of over-
lapping samples. The performance of VFL models heavily depends on the
quality of participants’ local data. It’s essential to measure the contribu-
tions of the participants for various purposes, e.g., participant selection
and reward allocation. The Shapley value is widely adopted by previ-
ous works for contribution assessment. However, computing the Shapley
value in VFL requires repetitive model training from scratch, incurring
exp ensive computation and communication overheads. Inspired by this
challenge, in this paper, we ask: can we efficiently and securely perform
data valuation for participants via the Shapley value in VFL?
We call this problem Vertical Federated Data Valuation, and intro-
duce VFDV-IM, a method utilizing an Inheritance Mechanism to expe-
dite Shapley value calculations by leveraging historical training records.
We first propose a simple, yet effective, strategy that directly inher-
its the model trained over the entire consortium. To further optimize
VFDV-IM, we propose a model ensemble approach that measures the
similarity of evaluated consortiums, based on which we reweight the his-
torical models. We conduct extensive experiments on various datasets
and show that our VFDV-IM can efficiently calculate the Shapley value
while maintaining accuracy.
Keywords: Vertical federated learning
· Data valuation
1Introduction
Building high-quality machine learning (ML) models usually requires collecting
and merging data from various organizations. However, due to data protection
X. Zhou and X. Yan—Equal contribution.
c
! The Author(s), under exclusive license to Springer Nature Singapore Pte Ltd. 2024
M. Onizuka et al. (Eds.): DASFAA 2024, LNCS 14850, pp. 409–424, 2024.
https://doi.org/10.1007/978-981-97-5552-3
_28
BBAAD9C20180234D78A0072836F0B3B092B9B20912680BA0A4D98434B15B2B741B4BB438915BAB0F22C920089846A2EBF2E9218AC1D05B311BBFC26F7C7E3FD3241123ADB72279F764FF283767F74BC05967EB8175F7041048FA519C2ADBBCC8D9E620954E3
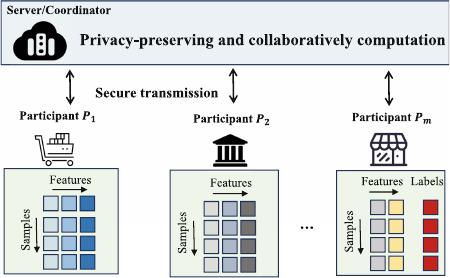
410 X. Zhou et al.
Fig. 1. Illustration of VFL tasks setting. In VFL, each participant possesses a distinct
set of features on the same set of samples, and only one participant holds the labels.
Through secure transmission and collaboratively computation, these participants can
train a global ML model over the joint feature space.
laws and increased privacy concerns, participants frequently limit data shar-
ing beyond their organization’s boundaries. As a distributed machine learning
scheme, federated learning (FL) can enable collaborative ML model training in
afederated“data consortium” in a secure and privacy-preserving way without
the need for centralized data aggregation. Based on data distribution, FL can be
categorized into horizontal federated learning (HFL) and vertical federated learn-
ing (VFL). In HFL, multiple participants contribute data samples that share the
same feature space. In contrast, VFL focuses on situations where different par-
ticipants hold different features of the same set of data samples.
Ver tical Fed erate d Learni ng . In this paper, we focus on VFL tasks. As
shown in Fig. 1, we consider a federated data consortium
P comprising m par-
ticipants, denoted by
P = {P
1
,P
2
,...,P
m
}.Intheconsortium,participantsshare
identical data samples but possess unique feature spaces. For example, for the
same users within a city, an e-commerce platform collects shopping information
from customers and a bank that has personal finance data.
Data Valuation in FL. Due to different data volumes and data qualities,
the contribution of each participant to the performance of the global model
varies in FL. Some participants who provide large-scale and high-quality data
may introduce significant contributions to the trained model, while others with
redundant data or erroneous data may impede the global model from achiev-
ing satisfactory performance or even deteriorate the model. Thus, it’s critical
to evaluate the data quality of each participant, without sacrificing the privacy
of participants’ local data. Many efforts have been devoted to data valuation
for HFL [12,29]. For example, Fed-influence [24]quantifiestheinfluenceofeach
client in terms of model parameters and Zhang et al. [27] measure the contribu-
tion of participants’ data by computing the cosine similarity between local and
BBAAD9C20180234D78A0072836F0B3B092B9B20912680BA0A4D98434B15B2B741B4BB438915BAB0F22C920089846A2EBF2E9218AC1D05B311BBFC26F7C7E3FD3241123ADB72279F764FF283767F74BC05967EB8175F7041048FA519C2ADBBCC8D9E620954E3
of 16
免费下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

评论