




Scrapy-Redis架构分析.pdf
免费下载
Scrapy-Redis 架构分析
.
scrapy-redis 简介
scrapy原的任务调度是基于件系统,通过JOBDIR指定任务信息存储的路径。这样只能
在单机执crawl。scrapy-redis将任务和数据信息的存取放到redis queue,使多台服务器可以同
时执crawl和tems process,提了数据爬取和处理的效率。
scrapy-redis是基于redis的scrapy 组件,主要功能如下:
•
分布式爬
多个爬实例分享个jobs redis queue队列,常适合范围多域名的爬集群
•
分布式后处理
爬抓取到的items push 到个 items redis queue,这就意味着可以开启多个items
processes来处理抓取到的数据
.
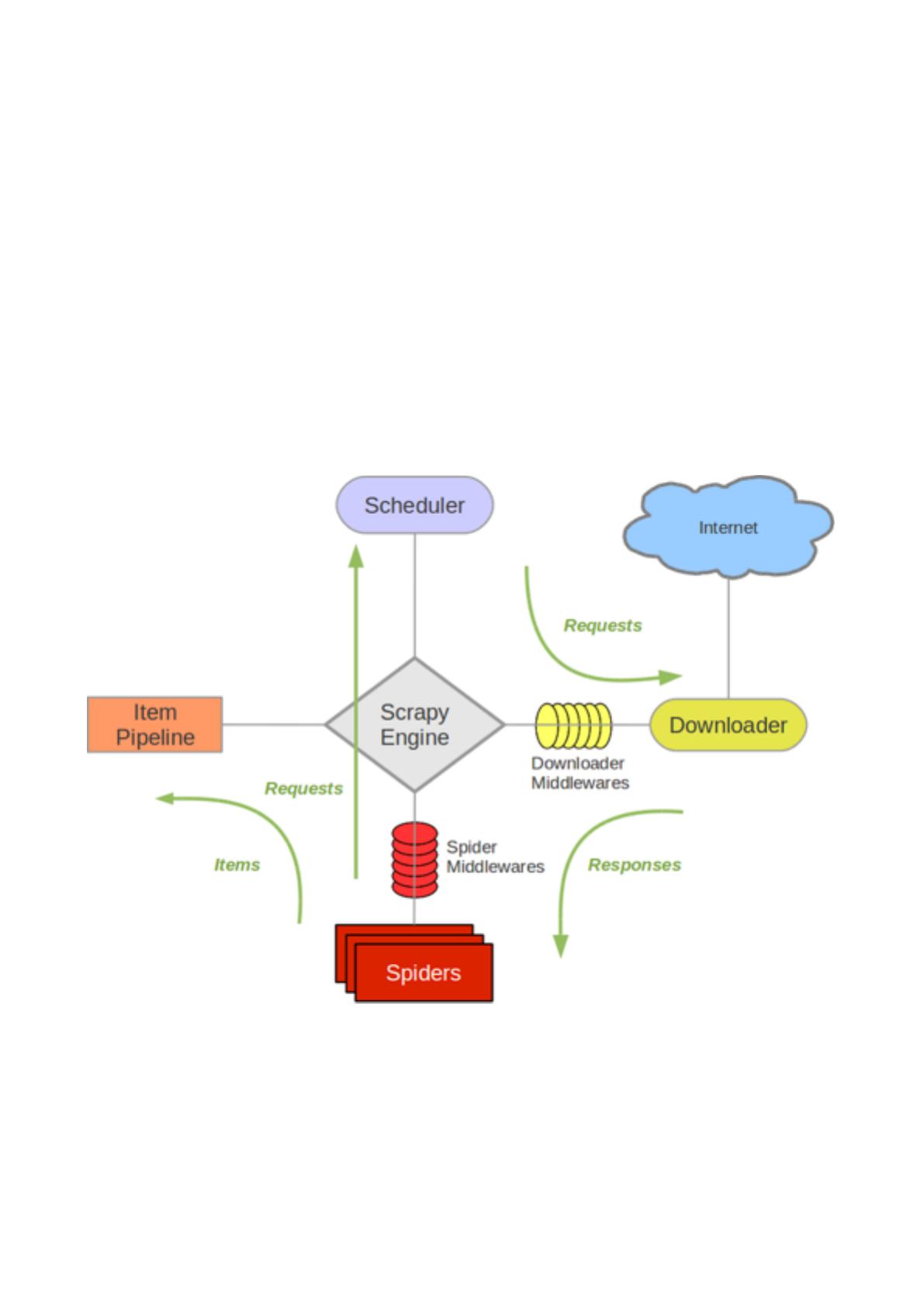
scrapy原架构
分析scrapy-redis的架构之前先回顾下scrapy的架构
组件
•
Scrapy Engine
引擎负责控制数据流在系统中所有组件中流动,并在相应动作发时触发事件。 详细内容查看下
的数据流(Data Flow)部分。
•
调度器(Scheduler)
调度器从引擎接受request并将他们队,以便之后引擎请求他们时提供给引擎。
•
Spiders
Spider是Scrapy户编写于分析response并提取item(即获取到的item)或额外跟进的URL的类。
每个spider负责处理个特定(或些)站。 更多内容请看 Spiders 。
•
Item Pipeline
Item Pipeline负责处理被spider提取出来的item。典型的处理有清理、 验证及持久化(例如存取到数
据库中)。 更多内容查看 Item Pipeline 。
•
数据流(Data flow)
Scrapy中的数据流由执引擎控制,其过程如下:
引擎打开个站(open a domain),找到处理该站的Spider并向该spider请求第个要爬取的
URL(s)。
引擎从Spider中获取到第个要爬取的URL并在调度器(Scheduler)以Request调度。
引擎向调度器请求下个要爬取的URL。
调度器返回下个要爬取的URL给引擎,引擎将URL通过下载中间件(请求(request)向)转发给下载
器(Downloader)。
旦下载完毕,下载器成个该的Response,并将其通过下载中间件(返回(response)
向)发送给引擎。
引擎从下载器中接收到Response并通过Spider中间件(输向)发送给Spider处理。
Spider处理Response并返回爬取到的Item及(跟进的)新的Request给引擎。
引擎将(Spider返回的)爬取到的Item给Item Pipeline,将(Spider返回的)Request给调度器。
(从第步)重复直到调度器中没有更多地request,引擎关闭该站。
三.
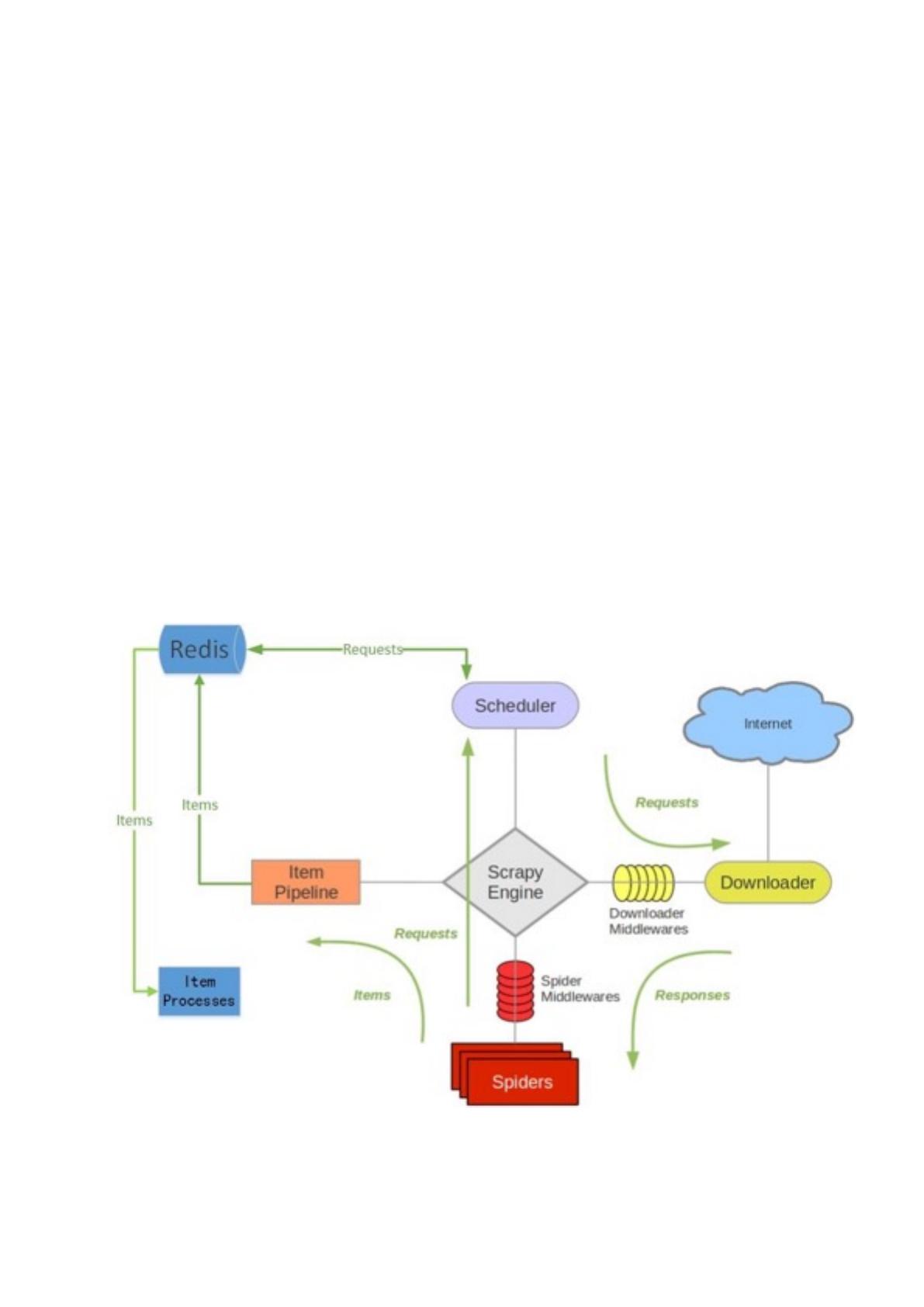
scrapy-redis 架构
如上图所,scrapy-redis在scrapy的架构上增加了redis,基于redis的特性拓展了如下组
件:
•
调度器(Scheduler):
of 3
免费下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

评论