




巨杉Tech 巨杉数据库数据高性能数据导入迁移实践.pdf
40墨值下载

巨杉 Tech | 巨杉数据库数据高性能数据导入迁移实
践
SequoiaDB 一款自研金融级分布式数据库产品,支持标准 SQL 和分布式事务功能、支持复
杂索引查询,兼容 MySQL、PGSQL、SparkSQL 等 SQL 访问方式。SequoiaDB 在分布式存
储功能上,较一般的大数据产品提供更多的数据切分规则,包括:水平切分、范围切分、主
子表切分和多维切分方式,用户可以根据不用的场景选择相应的切分方式,以提高系统的存
储能力和操作性能。
为了能够提供简单便捷的数据迁移和导入功能,同时更方便地与传统数据库在数据层进行对
接,巨杉数据库支持多种方式的数据导入,用户可以根据自身需求选择最适合的方式加载数
据。
本文主要介绍巨杉数据库集中常见的高性能数据导入方法,其中包括巨杉工具矩阵中的
Sdbimprt 导入工具,以及使用 SparkSQL, MySQL 和原生 API 接口进行数据导入,一共四种
方式。
Sdbimprt 工具导入
sdbimprt 是 SequoiaDB 的数据导入工具,是巨杉数据库工具矩阵中重要组成之一,它可以
将 JSON 格式或 CSV 格式的数据导入到 SequoiaDB 数据库中。
关于工具说明与参数介绍,请参考:http://doc.sequoiadb.com/cn/sequoiadb-cat_id-1479195620-edition_id-
0。
一、示例
下面简单介绍一下如何使用 sdbimprt 工具将 csv 文件导入到 SequoiaDB 集合空间 site
的集合 user_info 中:1. 数据文件名称为“user.csv”,内容如下:
“Jack”,18,”China”
“Mike”,20,”USA”
2.导入命令
sdbimprt --hosts=localhost:11810 --type=csv --file=user.csv -c site -l user_info --
fields='name string default "Anonymous", age int, country'
⚫ --hosts:指定主机地址(hostname:svcname)
⚫ --type:导入数据格式,可以是 csv 或 json
⚫ --file:要导入的数据文件名称
⚫ -c(--csname):集合空间的名字
⚫ -l(--clname):集合的名字
⚫ --fields:指定导入数据的字段名、类型、默认值
二、导入性能优化
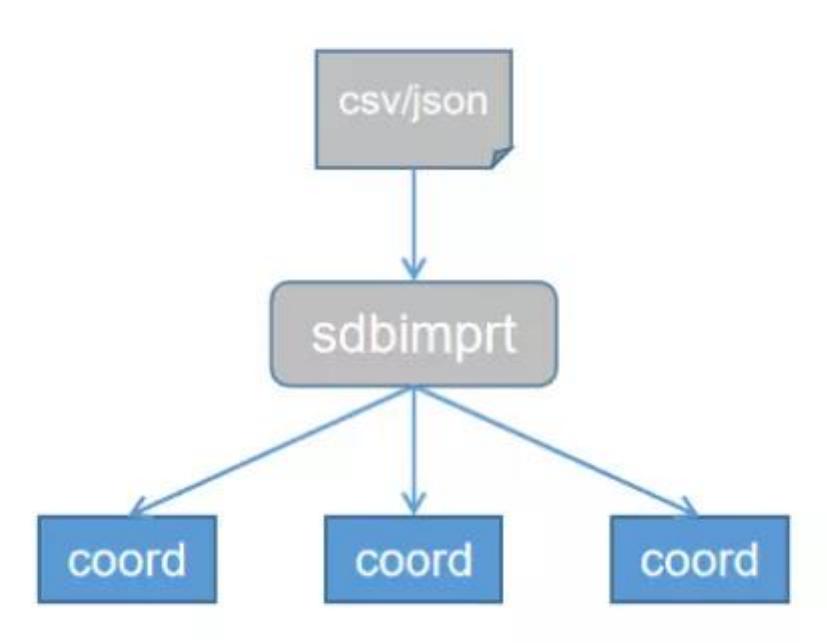
下面说明使用 sdbimprt 工具时如何提升导入性能:1. 使用 --hosts 指定多个节点导入数
据时,尽量指定多个 coord 节点的地址,用“,”分隔多个地址,sdbimprt 工具会把数据随机
发到不同机器上的 coord,起到负载均衡的作用(如图 1)。
图 1
2. 使用 --insertnum(-n) 参数在导入数据时,使用 --insertnum(-n) 参数,可以实现批量导
入,减少数据发送时的网络交互的次数,从而加快数据导入速度。取值范围为 1~100000,
默认值为 100。
3. 使用 --jobs(-j) 参数指定导入连接数(每个连接一个线程),从而实现多线程导入。
4. 切分文件 sdbimprt 在导入数据时支持多线程并发导入,但读数据时是单线程读取,随着
导入线程数的增加,数据读取就成为了性能瓶颈。这种情况下,可以将一个大的数据文件切
分成若干个小文件,然后每个小文件对应启动一个 sdbimprt 进程并发导入,从而提升导入
性能。如果集群内有多个协调节点,分布在不同的机器上,那么可以在多台机器上分别启动
sdbimprt 进程,并且每个 sdbimprt 连接机器本地的协调节点,这样数据发送给协调节点时
避免了网络传输(如图 2)。
of 6
40墨值下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

评论