




ICDE2023_DBCatcher A Cloud Database Online Anomaly Detection System based on Indicator Correlation_腾讯云.pdf
免费下载
DBCatcher: A Cloud Database Online Anomaly
Detection System based on Indicator Correlation
Guangyu Zhang
1
, Chunhua Li
1∗
, Ke Zhou
1
,LiLiu
1
, Ce Zhang
2
, Wancheng Chen
1
Haotian Fang
1
, Bin Cheng
3
, Jie Yang
3
, and Jiashu Xing
3
1
WNLO, Huazhong University of Science and Technology, China
2
ETH Zurich, Switzerland
3
Tencent Inc, China
{zhangguangyu, li.chunhua, zhke, lillian
hust, chenwc, fanght}@hust.edu.cn
{ce.zhang}@inf.ethz.ch;{bencheng, edgeyang, flacroxing}@tencent.com
Abstract—Anomaly detection system plays an important role
in maintaining the stability of cloud database. Existing studies
mainly focus on significant deviations in multivariate time series,
such as a combination of CPU utilization, transactions per
second, etc, to detect abnormal issues. Due to the complexity
of cloud database structure and functions, these approaches
are difficult to achieve a balance among detection performance,
detection efficiency and workload adaptability. In this paper, we
propose DBCatcher, a cloud database online anomaly detection
system based on indicator correlation. Through extensive analysis
of real-world cloud database time series, we find the corre-
lations among trends in the same key performance indicators
across databases within the same unit, which inspires us to
explore a time series correlation measurement method that
can efficiently detect abnormal issues. Meanwhile, we design a
flexible time window observation mechanism and an adaptive
threshold learning policy to minimize misjudgment caused by
key performance indicator fluctuations, greatly enhancing the
detection performance and workload adaptability. We conduct
extensive experiments under real-world and synthetic workloads.
Experimental results show that DBCatcher significantly improves
the detection performance and detection efficiency compared to
existing methods.
Index Terms—anomaly detection, cloud database, time series,
correlation measurement
I. INTRODUCTION
Cloud database is growing rapidly in the area of infrastruc-
ture services provided by cloud service vendors (e.g., AWS
Cloud, Microsoft Azure, and Tencent Cloud). Gartner forecasts
a 38.2% annual growth rate in the cloud database market
from 2021 to 2026 [1]. Therefore, maintaining the reliability
of cloud database becomes an increasingly critical issue [2].
Experienced Database Administrators (DBAs) have found that
when trends in the time series of Key Performance Indicators
(KPIs), such as CPU utilization, transactions per second, devi-
ate significantly from normal patterns, it commonly represents
some abnormal issues in cloud databases [3], [4]. As a result,
cloud service vendors establish monitoring systems to observe
the changes in KPIs to determine the operational state of cloud
database. The monitoring data on multiple KPIs constitutes a
multivariate time series.
Existing studies on time series anomaly detection are clas-
sified into two main categories: statistical based methods
[5]–[8] and machine-learning based methods [9]–[16]. To
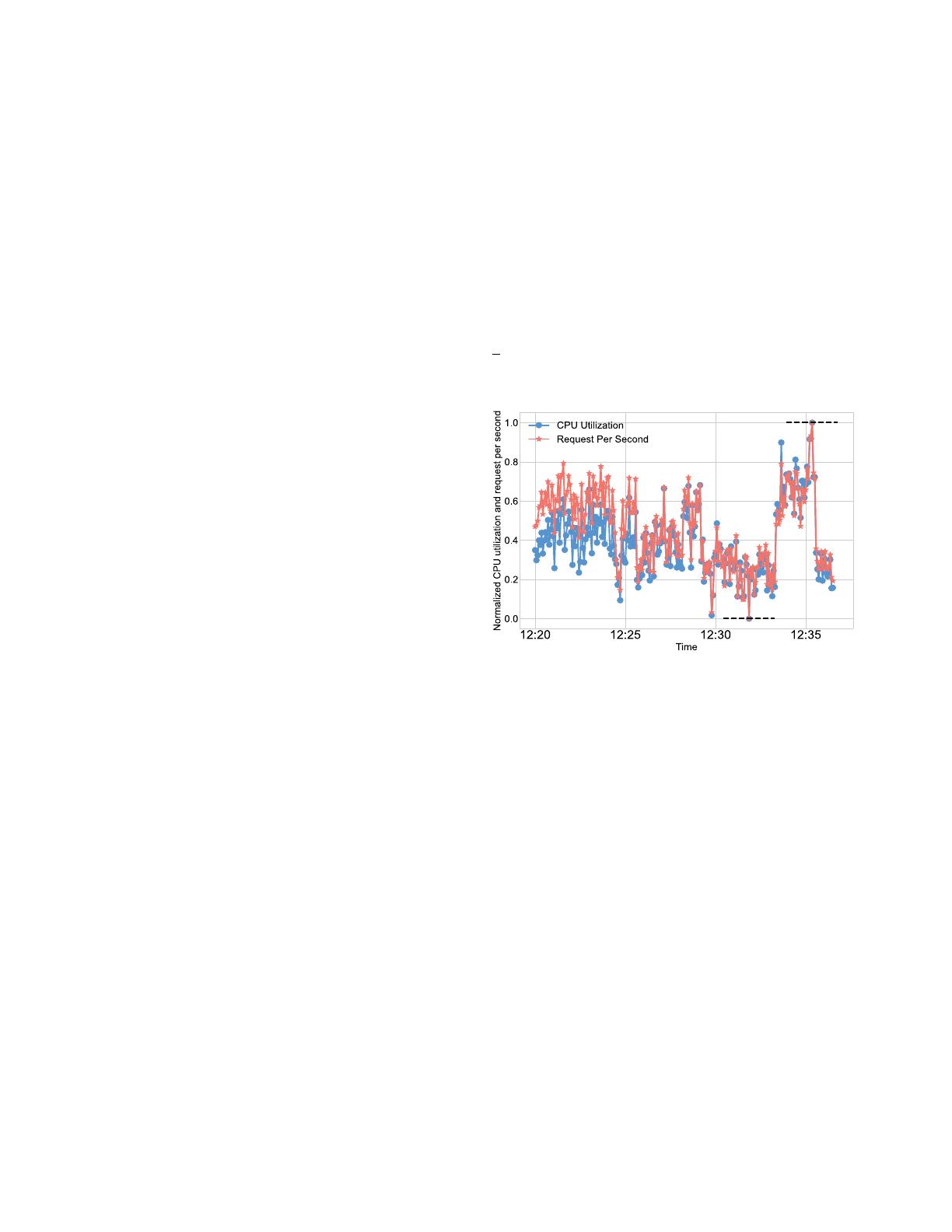
Fig. 1. An example of a burst increase in “CPU utilization” due to an increase
in “requests per second”, where “CPU utilization” and “requests per second”
are normalized to show time-series trends. Such trends are universal in Tencent
OLTP Cloud Database, for example, e-commerce users or game users will
have a burst of requests at some point in time.
observe the effectiveness of mainstream anomaly detection
methods on time series collected in practical cloud database
products, we evaluated a few representative methods, including
FFT [7], SR [8], SR-CNN [14], OmniAnomaly [15], and
JumpStarter [16], on various time series collected by Tencent
Cloud Database Monitoring System. FFT and SR are anomaly
detection methods based on statistical knowledge, while SR-
CNN, OmniAnomaly, and JumpStarter are machine-learning
based methods. Table I shows the limitations of these methods
in detection performance, detection efficiency, threshold auto-
adjustment, and workload adaptability.
(1) Detection performance. Cloud database multivariate time
series have various variation patterns. Some methods (e.g, FFT,
SR) detect the anomalies of time series by setting deviation
thresholds, while the difference in variation patterns of every
KPI makes it difficult to set appropriate deviation thresholds,
limiting their scope of applicability in practice.
(2) Detection efficiency. Detection efficiency means how long
it takes for a detection method to find anomalies. Each cloud
database processes tens of thousands of critical online trans-
1126
2023 IEEE 39th International Conference on Data Engineering (ICDE)
2375-026X/23/$31.00 ©2023 IEEE
DOI 10.1109/ICDE55515.2023.00091
2023 IEEE 39th International Conference on Data Engineering (ICDE) | 979-8-3503-2227-9/23/$31.00 ©2023 IEEE | DOI: 10.1109/ICDE55515.2023.00091
Authorized licensed use limited to: Tencent. Downloaded on April 22,2025 at 08:33:44 UTC from IEEE Xplore. Restrictions apply.

TABLE I
C
HARACTERISTICS OF DIFFERENT ANOMALY DETECTION METHODS.THE METHOD WE PROPOSE IS DBCATCHER.
FFT SR SR-CNN OmniAnomaly JumpStarter DBCatcher
Detection performance Low Low Medium High High High
Detection efficiency Low Medium High Medium Medium High
Threshold auto-adjustment Low Low Low Low Low High
Workload adaptability Low Low Medium Medium Medium High
actions per second. Therefore, detection efficiency is directly
correlated to the quantity and scope of transactions affected
by anomalies. Existing anomaly detection methods (e.g, Om-
niAnomaly, JumpStarter) require extensive data points (e.g.,
one data point per 5 seconds) to learn time series variation
features, resulting in anomaly identification too slowly.
(3) Threshold auto-adjustment. Most existing studies require
multiple thresholds for anomaly detection and these thresholds
are frequently a crucial part of the ultimate evaluation of
database state [3], [17]. Setting these thresholds under dif-
ferent workloads is non-trivial even for experienced DBAs,
as inappropriate thresholds can have side effects on detection
performance and efficiency.
(4) Workload adaptability. Existing methods are particularly
susceptible to workload variations. When workload varies, the
performance of existing machine-learning methods that have
previously been trained can plummet (e.g, SR-CNN, Omni-
Anomaly, and JumpStarter) [16]. Statistical based methods
(e.g, FFT, SR) can also be quite challenging under varied
workloads because of the difficulty of threshold adjusting.
The conclusions in Table I indicate that the mainstream
anomaly detection methods are not applicable to cloud
databases. By carefully analyzing the multivariate time series
in Tencent Cloud Database
1
, we find the following differences
between cloud database time series and the time series of
mainstream anomaly detection service objects (e.g, online
services): (1) Cloud database multivariate time series change
more frequently and with greater magnitude than other online
service time series. Figure 1 shows an example of the burst
increase in “CPU utilization” due to the increase in “Request
Per Second” increases in cloud database time series. (2)
Cloud database time series have complex variation patterns.
Other online service time series are commonly characterized
by periodic variations in time granularity by day, hour, etc.
[15], [18], [19], while cloud database time series contain
extensive irregular time series. (3) Complex functionality of
cloud databases such as data synchronization, consistency
maintenance, etc, can cause complex abnormal issues [4], [20],
[21]. These complex abnormal issues generate a wide variety
of time series trends (e.g., concept drift, spike) [4], [22].
The above analysis and findings prompted us to investigate
anomaly detection methods applicable to cloud databases.
In this paper, we find correlations among trends in the
1
Tencent Inc. is the largest social network service company in China, which
cloud databases provide data storage and management services for massive
users, supporting various applications such as social networks, games, e-
commerce, and finance.
same KPIs across databases within the same unit (see §II-B
for details). This phenomenon is called Unit Key Perfor-
mance Indicator Correlation (UKPIC). Based on the UKPIC
phenomenon, we propose an efficient cloud database online
anomaly detection system called DBCatcher.
The key contributions in this paper are as follows:
• We propose an efficient time series correlation mea-
surement method based on the UKPIC phenomenon to
calculate the correlations of time series, which can timely
identify KPIs with abnormal variation trends.
• We propose a flexible time window observation mecha-
nism that considerably enhances the performance of cloud
database anomaly detection by reducing the detrimental
impact of temporal fluctuations in KPI changes.
• We propose an adaptive threshold learning policy that ad-
dresses the challenge of auto-adjusting thresholds under
varying workloads.
• We conduct experiments under real-world and synthetic
workloads. Experimental results show that DBCatcher
improves F-Measure by 8.3%, 8.8%, and 9.2% over state-
of-the-art methods, it also accelerates detection efficiency
by 2.5× to 3×. For a 100M dataset, corresponding to
the amount of data for 120 hours of KPI data points,
DBcatcher takes only 42 seconds, which provides an
acceptable time overhead for online detection.
II. B
ACKGROUND AND PRELIMINARY STUDY
In this section, we first give the necessary background and
in-depth analysis of anomaly detection under cloud databases,
including the architecture of cloud databases, the unit key
performance indicator correlation phenomenon, and abnormal
time series trends. Then we present the challenges of anomaly
detection by applying correlation measurement methods.
A. Cloud Database Architecture
Figure 2 shows the general architecture of cloud databases.
As shown in the figure, a database cluster contains multiple
units, each unit deploys a load balance module and multiple
databases, and each database has one primary instance and
multiple replica instances. SQL requests from upper-level ap-
plications are distributed to different database units through the
global transactions manager, which are further processed by
the load balance module and forwarded to different databases
in the same unit. For read requests, they are handled equally
by different instances of each database. For write requests,
they are first processed via the primary instance and then the
data is synchronized to the remaining replica instances. When
1127
Authorized licensed use limited to: Tencent. Downloaded on April 22,2025 at 08:33:44 UTC from IEEE Xplore. Restrictions apply.
of 14
免费下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

评论