




SIGMOD 2025_Including Bloom Filters in Bottom-up Optimization_华为.pdf
免费下载

Including Bloom Filters in Boom-up Optimization
Tim Zeyl
Huawei, Cloud BU
Markham, Canada
timothy.zeyl@huawei.com
Qi Cheng
Huawei, Cloud BU
Markham, Canada
qi.cheng1@h-partners.com
Reza Pournaghi
Huawei, Cloud BU
Markham, Canada
reza.pournaghi1@huawei.com
Jason Lam
Huawei, Cloud BU
Markham, Canada
jason.lam@huawei.com
Weicheng Wang
Huawei, Cloud BU
Markham, Canada
ben.wang@huawei.com
Calvin Wong
Huawei, Cloud BU
Markham, Canada
calvin.wong1@huawei.com
Chong Chen
Huawei, Cloud BU
Markham, Canada
chongchen@huawei.com
Per-Ake Larson
Huawei, Cloud BU
Markham, Canada
paul.larson@h-partners.com
Abstract
Bloom lters are used in query processing to perform early data
reduction and improve query performance. The optimal query plan
may be dierent when Bloom lters are used, indicating the need for
Bloom lter-aware query optimization. To date, Bloom lter-aware
query optimization has only been incorporated in a top-down query
optimizer and limited to snowake queries. In this paper, we show
how Bloom lters can be incorporated in a bottom-up cost-based
query optimizer. We highlight the challenges in limiting optimizer
search space expansion, and oer an ecient solution. We show that
including Bloom lters in cost-based optimization can lead to better
join orders with eective predicate transfer between operators. On
a 100 GB instance of the TPC-H database, our approach achieved
a 32.8% further reduction in latency for queries involving Bloom
lters, compared to the traditional approach of adding Bloom lters
in a separate post-optimization step. Our method applies to all
query types, and we provide several heuristics to balance limited
increases in optimization time against improved query latency.
CCS Concepts
• Information systems
→
Query optimization; Query plan-
ning.
Keywords
database, query optimization, Bloom lter
ACM Reference Format:
Tim Zeyl, Qi Cheng, Reza Pournaghi, Jason Lam, Weicheng Wang, Calvin
Wong, Chong Chen, and Per-Ake Larson. 2025. Including Bloom Filters in
Bottom-up Optimization. In Companion of the 2025 International Conference
on Management of Data (SIGMOD-Companion ’25), June 22–27, 2025, Berlin,
Germany. ACM, New York, NY, USA, 13 pages. https://doi.org/10.1145/
3722212.3724440
This work is licensed under a Creative Commons Attribution 4.0 International License.
SIGMOD-Companion ’25, Berlin, Germany
© 2025 Copyright held by the owner/author(s).
ACM ISBN 979-8-4007-1564-8/2025/06
https://doi.org/10.1145/3722212.3724440
1 Introduction
Bloom lters and other bit vector lters are used widely in database
management systems to perform early data reduction [
4
–
7
,
16
].
Bloom lters provide an ecient way to probabilistically remove
rows early, reducing the number of rows participating in further
processing and improving query performance. Typically, bit vector
lters, such as Bloom lters, are built in hash joins when building
the hash join table, and applied to table scans on the probe side of
that hash join [
8
,
11
,
19
]. If the probe side consists of a subtree of
operator nodes, a Bloom lter can often be pushed down through
those operators to the table scans. When pushed through an in-
termediate operator, a Bloom lter can also reduce the number of
rows participating in that intermediate operator, magnifying the
improvements observed by using Bloom lters [5, 6].
Given that Bloom lters applied to table scans reduce the number
of rows produced by a table scan, intentional consideration of this
revised row estimate during optimization should lead to potentially
better query plans. It was illustrated in [
8
] that when Bloom lters
are included in a plan, the lowest cost join order can be dierent
from the lowest cost join order when Bloom lters are absent. Since
Bloom lters are typically added during post-processing (e.g., [
5
,
6
]),
after the optimal query plan structure has already been determined,
the optimal plan that includes Bloom lters may not necessarily be
found.
While [
8
] described how to include Bloom lters as a transforma-
tion rule in a top-down query optimizer [
9
,
10
], we do not know of
any work that describes how to include Bloom lters in a bottom-up
optimizer [
21
,
23
]. We argue that by revising the cardinality esti-
mate for scan plans that include Bloom lters, and incorporating
a cost model for building and applying Bloom lters, a bottom-up
optimizer can also produce query plans with better join ordering,
better join methods, and better re-partitioning strategies than sim-
ply adding Bloom lters in a post process.
An example is shown in Figure 1, illustrating the join produced
by our system for TPC-H [
24
] query 12 with and without including
Bloom lters in bottom-up cost-based optimization (CBO). When
Bloom lters are included in costing (BF-CBO), the planner explores
a plan that applies a Bloom lter to the table orders, which has a
703
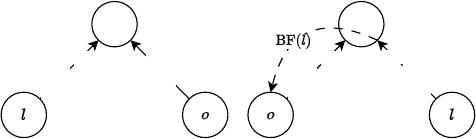
SIGMOD-Companion ’25, June 22–27, 2025, Berlin, Germany Tim Zeyl et al.
HJ
BC
2.8M
3.8M
150M
150M
inner/buildouter/probe
(a) Without BF-CBO
HJ
RD
6.4M
9.1M
RD
2.8M
3.1M
(b) With BF-CBO
Figure 1: The join order for TPC-H query 12 without includ-
ing Bloom lters during bottom-up CBO (panel a) uses the
table o:orders with 150M rows as the build side of a hash join
(HJ). The l:lineitem table with an estimated 2.8M rows and
actual 3.1M rows after local predicate ltering is broadcast
(BC) to each of the 48 computing threads used in this ex-
ample. A Bloom lter is not applied during post-processing
in this case because the probe side is a foreign key column
referencing an unltered primary key column on the build
side; a Bloom lter cannot lter any probe side rows in this
case. When including Bloom lters in CBO (panel b), the join-
input ordering is reversed so a Bloom lter can be built on
l:lineitem and applied to o:orders, signicantly reducing its
estimated row count to 6.4M rows. The reduced row estimate
for o:orders lowers the cost of this join-input ordering. The
planner then selects the lowest cost plan as depicted, which
maintains the new join-input ordering and redistributes (RD)
both sides. The query runs with 49.2% lower latency when
including Bloom lters in costing.
considerably lower estimated row count than without the Bloom
lter. A better join-input ordering is then selected, resulting in far
fewer rows needing to participate in the query’s join and reducing
the overall runtime.
At a high level, our method adds additional sub-plans to scan
nodes where single-column Bloom lters can be applied. These
Bloom lter scan sub-plans are costed and given new cardinality
estimates. When evaluating joins between two relations, the ad-
ditional Bloom lter sub-plans are combined with all compatible
sub-plans from the other relation, and a unique cost and cardi-
nality estimate is computed for each combination. This allows a
completely dierent query plan, relative to a post-processing appli-
cation of Bloom lters, to be built by a bottom-up optimizer.
The optimizer search space is necessarily increased by the in-
clusion of additional Bloom lter sub-plans. Evaluating additional
sub-plans is a common problem that must be addressed by the
optimizer when adding new operators to a DBMS. One method we
adopt is to impose search-space-limiting heuristics. However, one
nuance that applies uniquely to Bloom lter sub-plans, and which
we will describe further in Section 3, is that their row counts cannot
be estimated until the complete set of tables on the build side of the
join that provides the Bloom lter is known. If handled in a naïve
way, this means the extra Bloom lter sub-plans must be main-
tained with unknown cost until computing the join that provides
the required Bloom lter build relation. This naïve approach leads
to an explosion of the search space and an increase in optimization
time that is prohibitive.
Our contributions in this paper include 1) introducing a unique
property of Bloom lter sub-plans in the context of bottom-up CBO
that triggers their special handling, and 2) proposing a two-phased
bottom-up approach that minimizes the increase in optimizer search
space. Our method allows Bloom lters to be considered during
bottom-up CBO, which enables the optimizer to nd dierent join
orderings that may provide an opportunity to apply more Bloom
lters and provide better predicate transfer.
Next, we describe related work (Section 2). In the remaining
sections of the paper, we describe our method in detail (Section 3,
with notations listed in Table 1), demonstrate our results (Section 4),
and conclude with a discussion (Section 5).
2 Related work
The idea that Bloom lters can be used for predicate transfer across
multiple joins is described in [
25
] (Pred-Trans). The authors describe
that a predicate on one table (
𝑇
1
) can be transferred to a joining
table (
𝑇
2
) through a Bloom lter.
𝑇
2
can realize the ltering eects of
the predicate on
𝑇
1
by applying the Bloom lter built from the pre-
ltered
𝑇
1
.
𝑇
2
can further transfer that predicate’s ltering eects
to yet another table (e.g.,
𝑇
3
) by using another Bloom lter, and
so on. This idea has its roots in earlier work showing that semi-
joins can be used to reduce the size of relations prior to joins [
2
],
and minimize data transfer in a distributed context [
1
,
3
]. This
work indicates that nding the best data reduction schedule is its
own optimization problem. The authors of [
5
,
6
] extended this
line of work by using bit vector lters instead of semi-joins for
row reduction. They showed that the positioning and ordering of
bit vector lters applied to a xed execution plan could aect the
amount of data reduction observed; again indicating the need for
optimization of a reduction schedule.
In the Pred-Trans paper, Bloom lters were applied as a pre-
ltering step before any joins were computed. However, the arrange-
ment of Bloom lter application was determined heuristically—they
arranged the tables from small to large, then applied all possible
Bloom lters in one forward pass and one backward pass. The best
join order was found independently after the input tables had been
reduced. This approach was benecial, but likely missed the best
arrangement of Bloom lters for optimal predicate transfer, as no
costed optimization of the reduction schedule was performed. Our
approach diers in that we directly consider the estimated selectiv-
ity and cost of applying Bloom lters when building the join graph,
so that eective join orders can be found that inherently consider
the predicate transferring ability of Bloom lters.
In [
26
], the authors study the join order of star-schema queries
when Bloom lters are built on multiple dimension tables and ap-
plied to a single fact table. They found that with these Bloom lters
applied, the query plans were robust to the join order of the mul-
tiple dimension tables; each join order tested had similar costs.
Ding et al
.
extended this nding to snowake-schema queries, and
demonstrated that the best join order for a query can be dierent
when Bloom lters are applied [
8
]. They proposed a cost model
for Bloom lters and implemented their Bloom lter-aware opti-
mization as a transformation rule into Microsoft SQL Server [
18
], a
top-town, Volcano/Cascades style query optimizer. Their optimizer
704
of 13
免费下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

文档被以下合辑收录
评论