




26-大模型(LLMs)参数高效微调(PEFT) 面.pdf
5墨值下载
大模型(LLMs)参数高效微调(PEFT) 面
来自: AiGC面试宝典
宁静致远 2023年09月18日 20:55
1. 微调方法是啥?如何微调?
fine-tune,也叫全参微调,bert微调模型一直用的这种方法,全部参数权重参与更新以适配领域数据,效果好。
prompt-tune, 包括p-tuning、lora、prompt-tuning、adaLoRA等delta tuning方法,部分模型参数参与微调,训练
快,显存占用少,效果可能跟FT(fine-tune)比会稍有效果损失,但一般效果能打平。
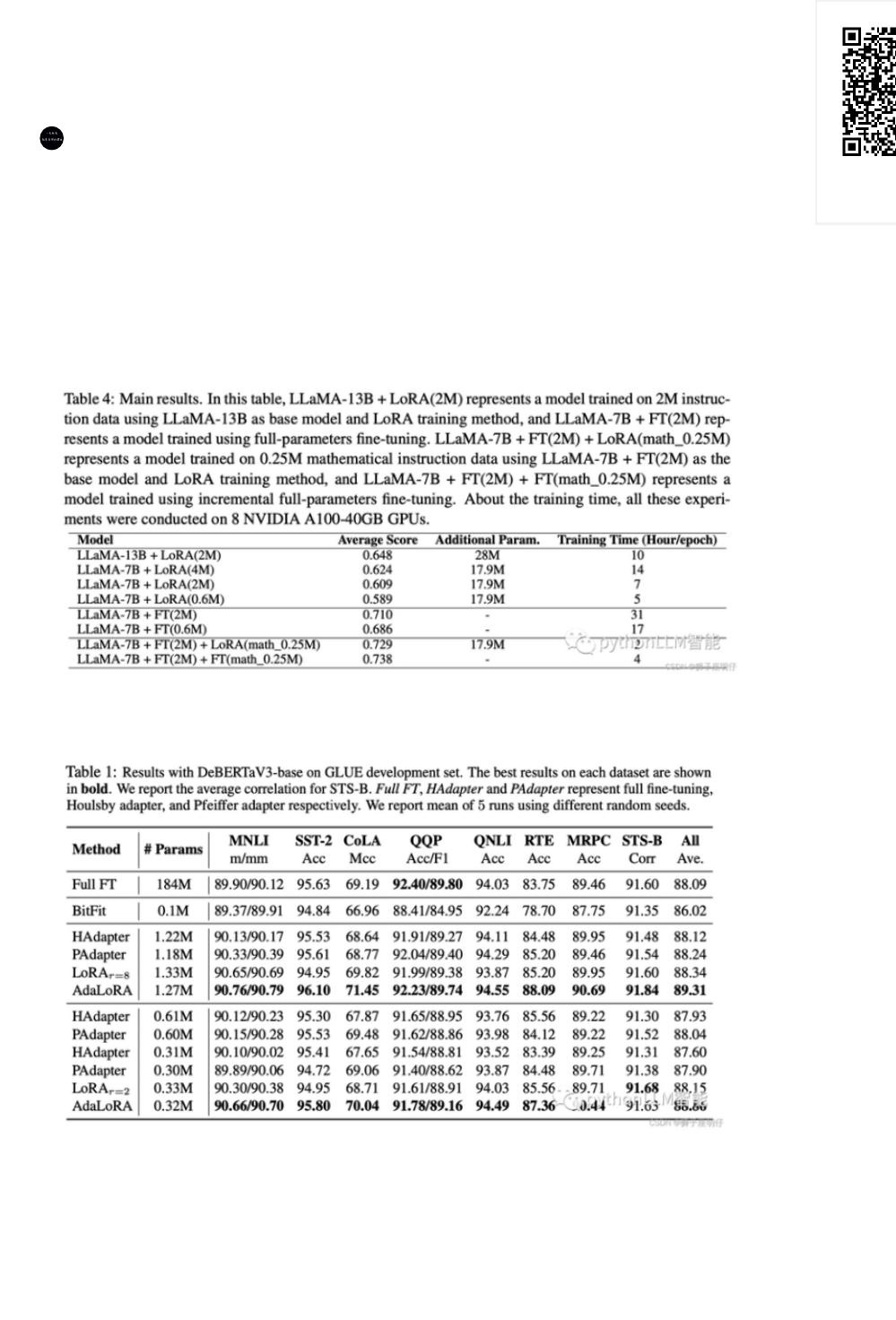
链家在BELLE的技术报告《A Comparative Study between Full-Parameter and LoRA-based Fine-Tuning on
Chinese Instruction Data for Instruction Following Large Language Model》中实验显示:FT效果稍好于LoRA。
peft的论文《ADAPTIVE BUDGET ALLOCATION FOR PARAMETER- EFFICIENT FINE-TUNING》显示的结
果:AdaLoRA效果稍好于FT。
2. 为什么需要 PEFT?
在面对特定的下游任务时,如果进行Full FineTuning(即对预训练模型中的所有参数都进行微调),太过低效;
而如果采用固定预训练模型的某些层,只微调接近下游任务的那几层参数,又难以达到较好的效果。
3. 介绍一下 PEFT?
扫码加
查看更多
PEFT技术旨在通过最小化微调参数的数量和计算复杂度,来提高预训练模型在新任务上的性能,从而缓解大型
预训练模型的训练成本。这样一来,即使计算资源受限,也可以利用预训练模型的知识来迅速适应新任务,实现
高效的迁移学习。
4. PEFT 有什么优点?
PEFT技术可以在提高模型效果的同时,大大缩短模型训练时间和计算成本,让更多人能够参与到深度学习研究
中来。除此之外,FEFT可以缓解全量微调带来灾难性遗忘的问题。
5. 微调方法批处理大小模式GPU显存速度?
微调方法批处理大小模式GPU显存速度
6. Peft 和 全量微调区别?
所谓的 fune-tine 只能改变风格, 不能改变知识, 是因为我们的 fine-tune, 像是 LoRA 本来就是低秩的, 没办法对模
型产生决定性的改变. 要是全量微调, 还是可以改变知识的.
7. 多种不同的高效微调方法对比
像P-Tuning v2、LoRA等都是综合评估很不错的高效微调技术。如果显存资源有限可以考虑QLoRA;如果只是解
决一些简单任务场景,可以考虑P-Tuning、Prompt Tuning也行。
下表从参数高效方法类型、是否存储高效和内存高效、以及在减少反向传播成本和推理开销的计算高效五个维度
比较了参数高效微调方法。
LoRA (r=8) 16 FP16 28GB 8ex/s
LoRA (r=8) 8 FP16 24GB 8ex/s
LoRA (r=8) 4 FP16 20GB 8ex/s
LoRA (r=8) 4 INT8 10GB 8ex/s
LoRA (r=8) 4 INT4 8GB 8ex/s
P-Tuning (p=16) 4 FP16 20GB 8ex/s
P-Tuning (p=16) 4 INT8 16GB 8ex/s
P-Tuning (p=16) 4 INT4 12GB 8ex/s
Freeze (l=3) 4 FP16 24GB 8ex/s
Freeze (l=3) 4 INT8 12GB 8ex/s
of 4
5墨值下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

评论