




41-大模型(LLMs)LLM生成SFT数据方法面.pdf
5墨值下载
大模型(LLMs)LLM生成SFT数据方法面
来自: AiGC面试宝典
宁静致远 2023年12月23日 12:23
一、SFT数据集如何生成?
SFT数据集构建通常有两种方法:人工标注和使用LLM(比如GPT-4)来生成的,人工标注对于构
建垂直领域比较合适,可以减少有偏数据,但是成本略高;使用LLM生成,可以在短时间内生成大
量数据。
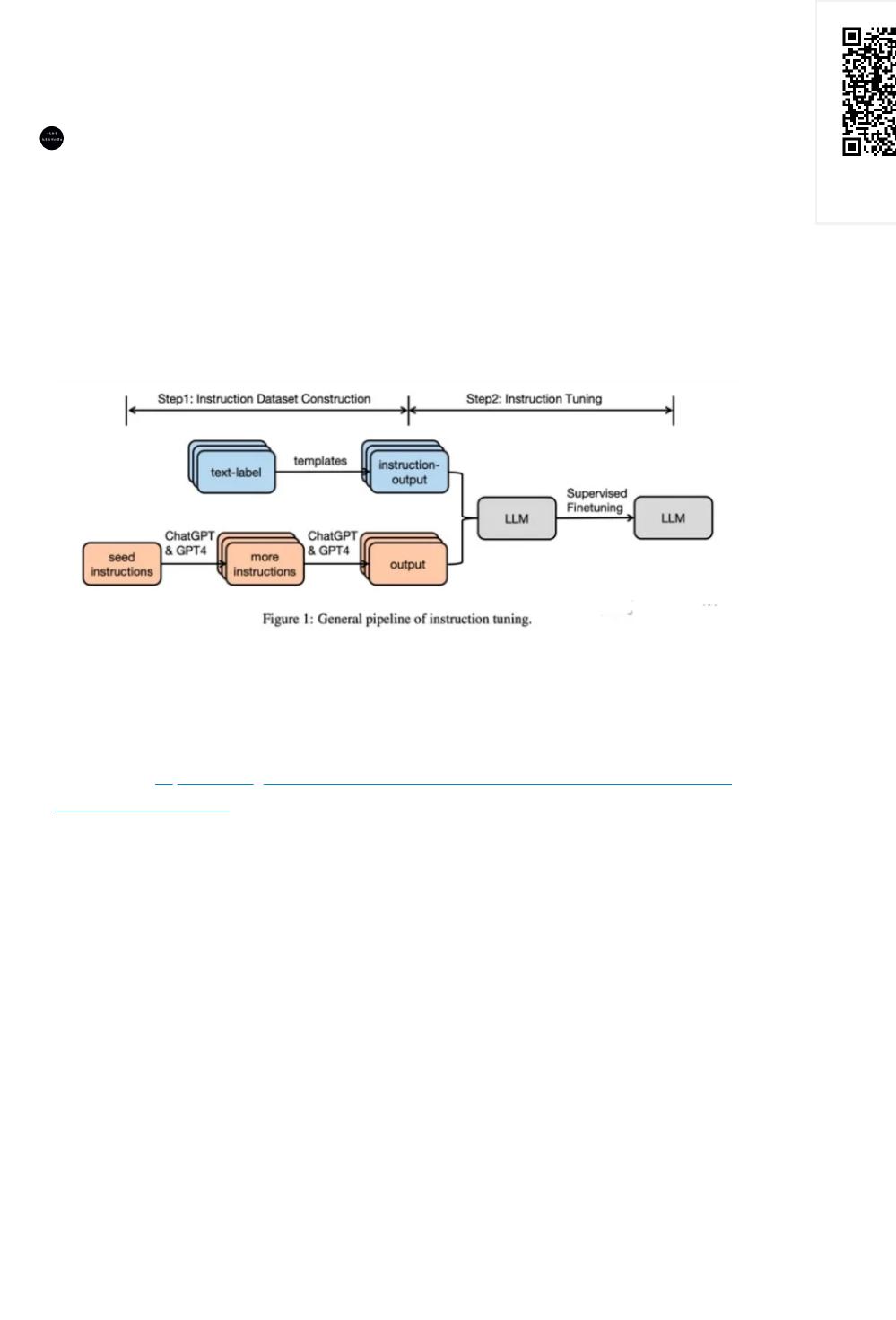
SFT数据集构建以及SFT微调Pipeline如下图所示:
二、Self-Instruct 篇
2.1 什么是 Self-Instruct ?
Self-Instruct(https://arxiv.org/abs/2212.10560):一个通过预训练语言模型自己引导自己来提高
的指令遵循能力的框架。
2.2 Self-Instruct 处理思路?
• 步骤1:作者从 175个种子任务中随机抽取 8 条自然语言指令作为示例,并提示InstructGPT生
成更多的任务指令。
• 步骤2:作者确定步骤1中生成的指令是否是一个分类任务。如果是,他们要求 InstructGPT 根
据给定的指令为输出生成所有可能的选项,并随机选择特定的输出类别,提示 InstructGPT 生
成相应的“输入”内容。对于不属于分类任务的指令,应该有无数的“输出”选项。作者提出了“输
入优先”策略,首先提示 InstructGPT根据给定的“指令”生成“输入”,然后根据“指令”和生成的“输
入”生成“输出”。
• 步骤3:基于第 2 步的结果,作者使用 InstructGPT 生成相应指令任务的“输入”和“输出”,采用
“输出优先”或“输入优先”的策略。
• 步骤4:作者对生成的指令任务进行了后处理(例如,过滤类似指令,去除输入输出的重复数
据),最终得到52K条英文指令
扫码加
查看更多

of 3
5墨值下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

评论