




Oracle 表连接NESTED LOOPS、HASH JOIN、排序合并.pdf
10墨值下载
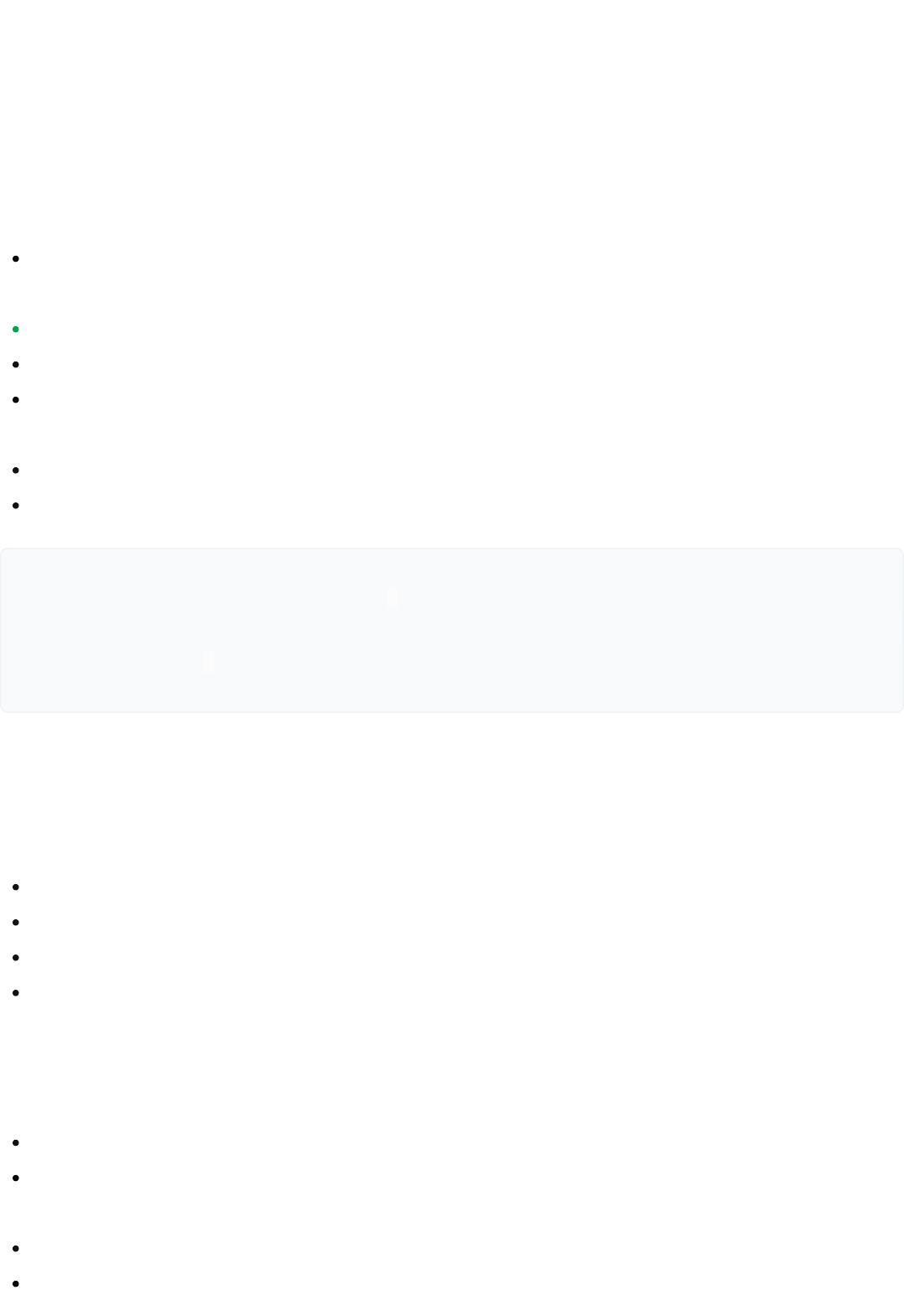
有驱动顺序,驱动表(结果集)返回多少记录,被驱动表(结果集)就被访问多少次,无须排序。
一、NESTED LOOPS
嵌套循环算法
特点
1、高度依赖索引,被驱动表索引只能为:INDEX UNIQUE SCAN、INDEX RANGE SCAN,才能保障性能高
效;
2、小结果集做驱动表,大结果集做被驱动表,才能保障性能高效;
3、DBLINK永远不能作为NL的被驱动表;
4、两表使用外连接进行关联,如果是NESTED LOOPS,那么无法更改驱动表,驱动表将会被固
定在主表;
5、连接条件是instr、LIKE、substr、regexp_like只能走NESTED LOOPS;
6、HINT写法:t1为驱动表,t2为被驱动表
select /*+leading(t1) use_nl(t2)*/ * 1
from t1 2
join t2 on t1.id=t2.id;3
二、HASH JOIN
HASH连接算法
1、Build 阶段:读取小表(Build Input)生成Hash表;
2、Probe 阶段:读取大表(Probe Input)探查Hash表并进行连接;
3、Build 操作在PGA中进行,不够时使用临时表空间;
4、被驱动表(被驱动表不需要读入PGA中),对被驱动表的连接列也进行hash运算,然后到PGA中去探测Hash
表进行连接;
特点
1、当表数据太大PGA放不下,会使用临时表空间,从而影响性能;
2、驱动顺序:小的结果集先访问,大的结果集后访问,才能保证被驱动表的访问次数降到最低,
才能保障性能;
3、驱动表和被驱动表都只会访问0次(索引能返回数据,就不需要再回表)或者1次;
4、HASH连接的驱动表与被驱动表的连接列都不需要创建索引;
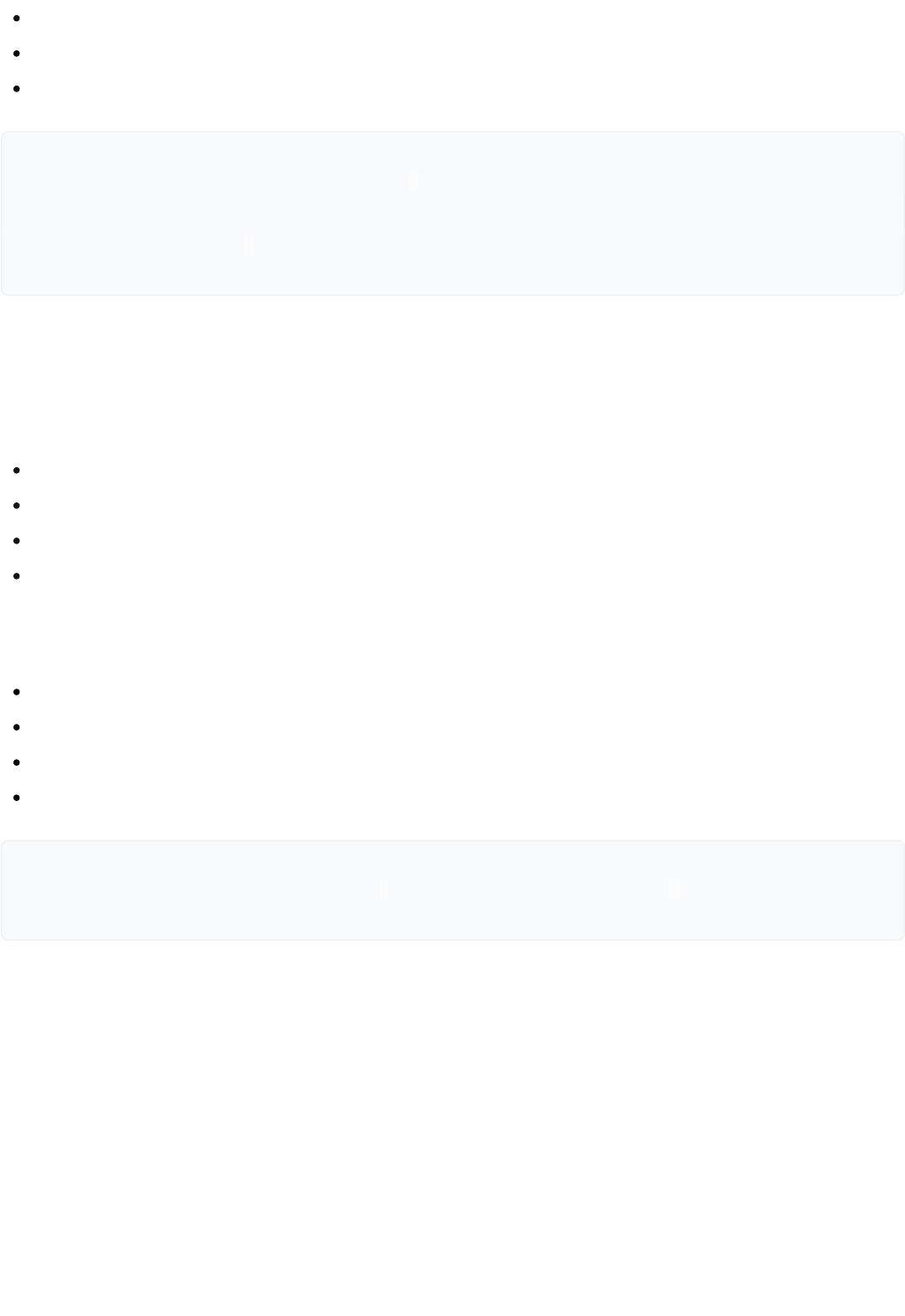
1、等值关联:返回数据量少:NESTED LOOPS,返回数据量大:HASH JOIN
2、非等值关联:SORT JOIN & MERGE JOIN(排序合并)
3、隐含参数:_hash_join_enabled :用于控制优化器是否考虑使用哈希连接(Hash Join)作为表连接
方式,该参数默认值为TRUE,表示Oracle优化器在生成执行计划时会考虑使用哈希连接。
5、HASH连接主要用于处理两表等值关联;
6、海量数据连接非常快;
7、HINT用法:
SELECT /*+leading(t1) use_hash(t2)*/ * 1
FROM T1 2
INNER JOIN ON T1.ID = T2.ID;3
三、SORT JOIN & MERGE JOIN(排序合并)
连接算法
1、Sort 阶段:两边集合按照连接字段进行排序
2、Merge 阶段:排序好的两边集合进行相互合并(Merge)操作。
3、两张表只会访问0次(索引能返回数据,就不需要再回表)或者1次;
4、Sort 、Merge 均在PGA中操作,PGA空间不够时会使用临时表空间。
特点
1、支持排序合并连接的连接条件:支持>、>=和<、<=、<>之类的连接条件。
2、排序合并连接就是为了解决:非等值关联,并行返回数据量大的情况
3、Sort Merge join 用在没有索引,并且数据已经排序的情况
3、HINT用法:
SELECT /*+ordered use_merge(t2)*/ * FROM T1 INNER JOIN ON T1.ID = T2.ID1
四、总结(适用大部分场景,特殊除外)
of 7
10墨值下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

文档被以下合辑收录
评论