




Tuning AIO in PostgreSQL 18.pdf
免费下载

Tomas Vondra
blog about Postgres code and community
Blog About Talks Tags
Tuning AIO in PostgreSQL 18
PostgreSQL 18 was stamped earlier this week, and as usual there’s a lot of improvements. One of
the big architectural changes is asynchronous I/O (AIO), allowing asynchronous scheduling of I/O,
giving the database more control and better utilizing the storage.
I’m not going to explain how AIO works, or present detailed benchmark results. There have been
multiple really good blog posts about that. There’s also a great talk from pgconf.dev 2025 about
AIO, and a recent “Talking Postgres” podcast episode with Andres, discussing various aspects of
the whole project. I highly suggest reading / watching those.
I want to share a couple suggestions on how to tune the AIO in Postgres 18, and explain some
inherent (but not immediately obvious) trade-offs and limitations.
Ideally, this tuning advice would be included in the docs. But that requires a clear consensus on the
suggestions, usually based on experience from the field. And because AIO is a brand new feature,
it’s too early for that. We have done a fair amount of benchmarking during development, and we
used that to pick the defaults. But that can’t substitute experience from running actual production
systems.
So here’s a blog post with my personal opinions on how to (maybe) tweak the defaults, and what
trade offs you’ll have to consider.
io_method / io_workers
There’s a handful of parameters relevant to AIO (or I/O in general). But you probably need to worry
about just these two, introduced in Postgres 18:
io_method = worker (options: sync, io_uring)
io_workers = 3
The other parameters (like io_combine_limit) have reasonable defaults. I don’t have great
suggestions on how to tune them, so just leave those alone. In this post I’ll focus on the two
important ones.
io_method
The io_method determines AIO actually handles requests - what process performs the I/O, and
how is the I/O scheduled. It has three possible values:
sync - This is a “backwards compatibility” option, doing synchronous I/O with posix_fadvice
where supported. This prefetches data into page cache, not into shared buffers.
worker - Creates a pool of “IO workers”, doing the actual I/O. When a backend needs to read a
block from a data file, it inserts a request into a queue in shared memory. An I/O worker wakes
up, does the pread, puts it into shared buffers and notifies the backend.
io_uring - Each backend has a io_uring instance (a pair of queues) and uses it to perform
the I/O. Except that instead of doing pread it submits the requests through io_uring.
The default is io_method = worker. We did consider defaulting both to sync or io_uring, but I
think worker is the right choice. It’s actually “asynchronous”, and it’s available everywhere
(because it’s our implementation).
sync was seen as a “fallback” choice, in case we run into issues during beta/RC. But we did not,
and it’s not certain using sync would actually help, because it still goes through the AIO
infrastructure. You can still use sync if you prefer to mimic older releases.
io_uring is a popular way to do async I/O (and not just disk I/O!). And it’s great, very efficient and
lightweight. But it’s specific to Linux, while we support a lot of platforms. We could have used
platform-specific defaults (similarly to wal_sync_method). But it seemed like unnecessary
complexity.
Note:Note:Note:Note: Even on Linux it’s hard to verify io_uring. Some container runtimes (e.g. containerd)
disabled io_uring support a while back, because of security risks.
None of the io_method options is “universally superior.” There’ll always be workloads where A
outperforms B and vice versa. In the end, we wanted most systems to use AIO and get the benefits,
and we wanted to keep things simple, so we kept worker.
AdviceAdviceAdviceAdvice: My advice is to stick to io_method = worker, and to adjust the io_workers value (as
explained in the following section).
io_workers
The Postgres defaults are very conservative. It will start even on a tiny machine like Raspberry Pi.
Which is great! The flip side is it’s terrible for typical database servers which tend to have much
more RAM/CPU. To get good performance on such larger machines, you need to adjust a couple
parameters (shared_buffers, max_wal_size, …).
I wish we had an automated way to pick “good” initial values for these basic parameters, but it’s
way harder than it looks. It depends a lot on the context (e.g. other stuff might be running on the
same system). At least there are tools like PGTune that will recommend sensible values …
This certainly applies to the io_workers = 3 default, which creates just 3 I/O workers. That may
be fine on a small machine with 8 cores, but it’s definitely not enough for 128 cores.
I can actually demonstrate this using results from a benchmark I did as input for picking the
io_method default. The benchmark generates a synthetic data set, and then runs queries matching
parts of the data (while forcing a particular scan type).
NoteNoteNoteNote: The benchmark (along with scripts, a lot of results and a much more detailed explanation)
was originally shared in the pgsql-hackers thread about the
io_method
default. Look at that thread
for more details and feedback from various other people. The presented results are from a small
workstation with Ryzen 9900X (12 cores/24 threads), and 4 NVMe SSDs (in RAID0).
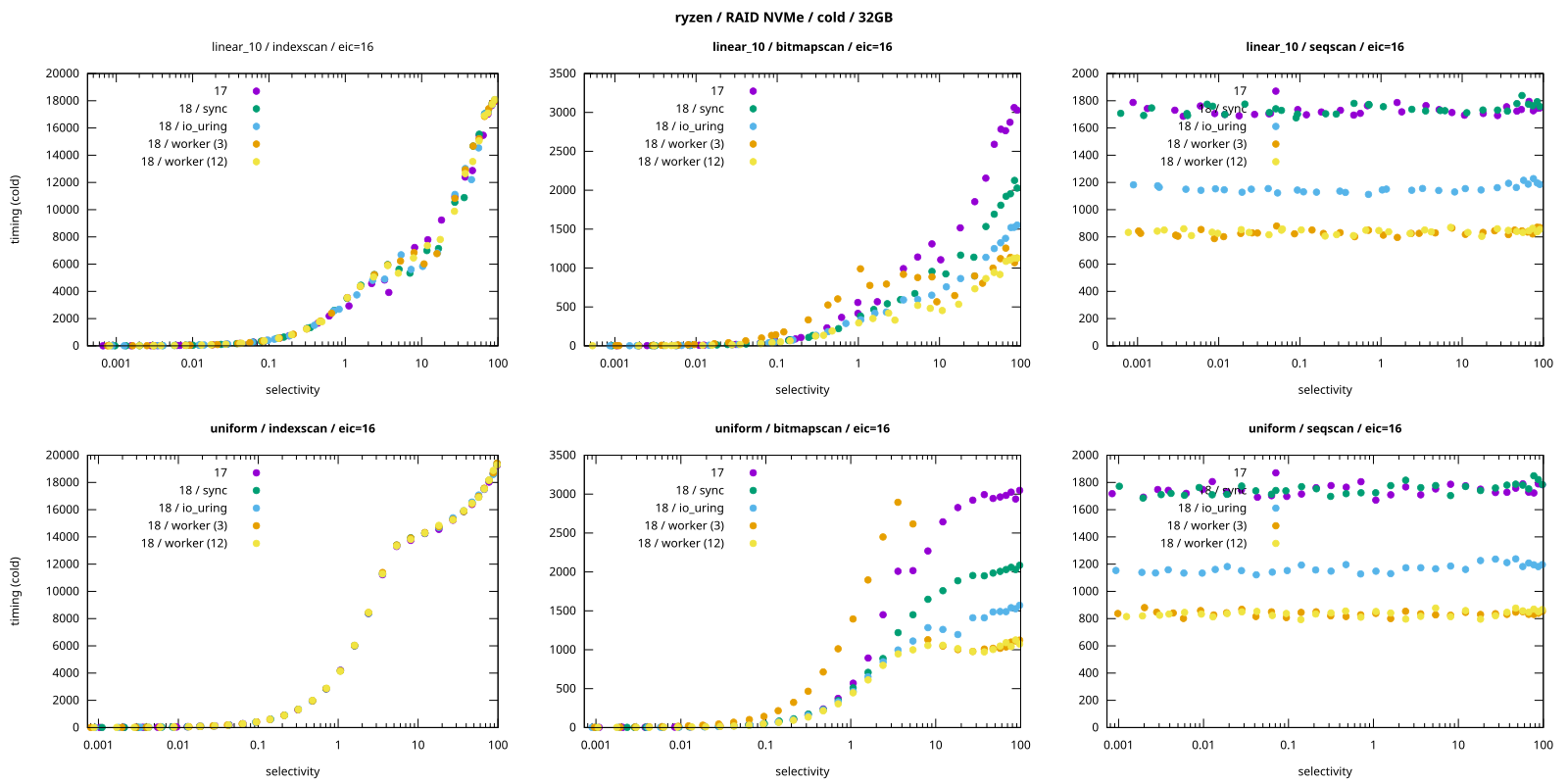
Here’s a chart comparing query timing for different io_method options [PDF]:
Each color is a different io_method value (17 is “Postgres 17”). There are two data data series for
“worker”, with different numbers of workers (3 and 12). This is for two data sets:
uniform - uniform distribution (so the I/O is entirely random)
linear_10 - sequential with a bit of randomness (imperfect correlation)
The charts show a couple very interesting things:
index scansindex scansindex scansindex scans - io_method has no effect, which makes perfect sense because index scans do
not use AIO yet (all the I/O is synchronous).
bitmap scansbitmap scansbitmap scansbitmap scans - The behavior is a lot messier. The worker method performs best, but only with
12 workers. With the default 3 workers it actually performs poorly for low selectivity queries.
sequential scanssequential scanssequential scanssequential scans - There’s a clear difference between the methods. worker is the fastest,
about twice as faster than sync (and PG17). io_uring is somewhere in between.
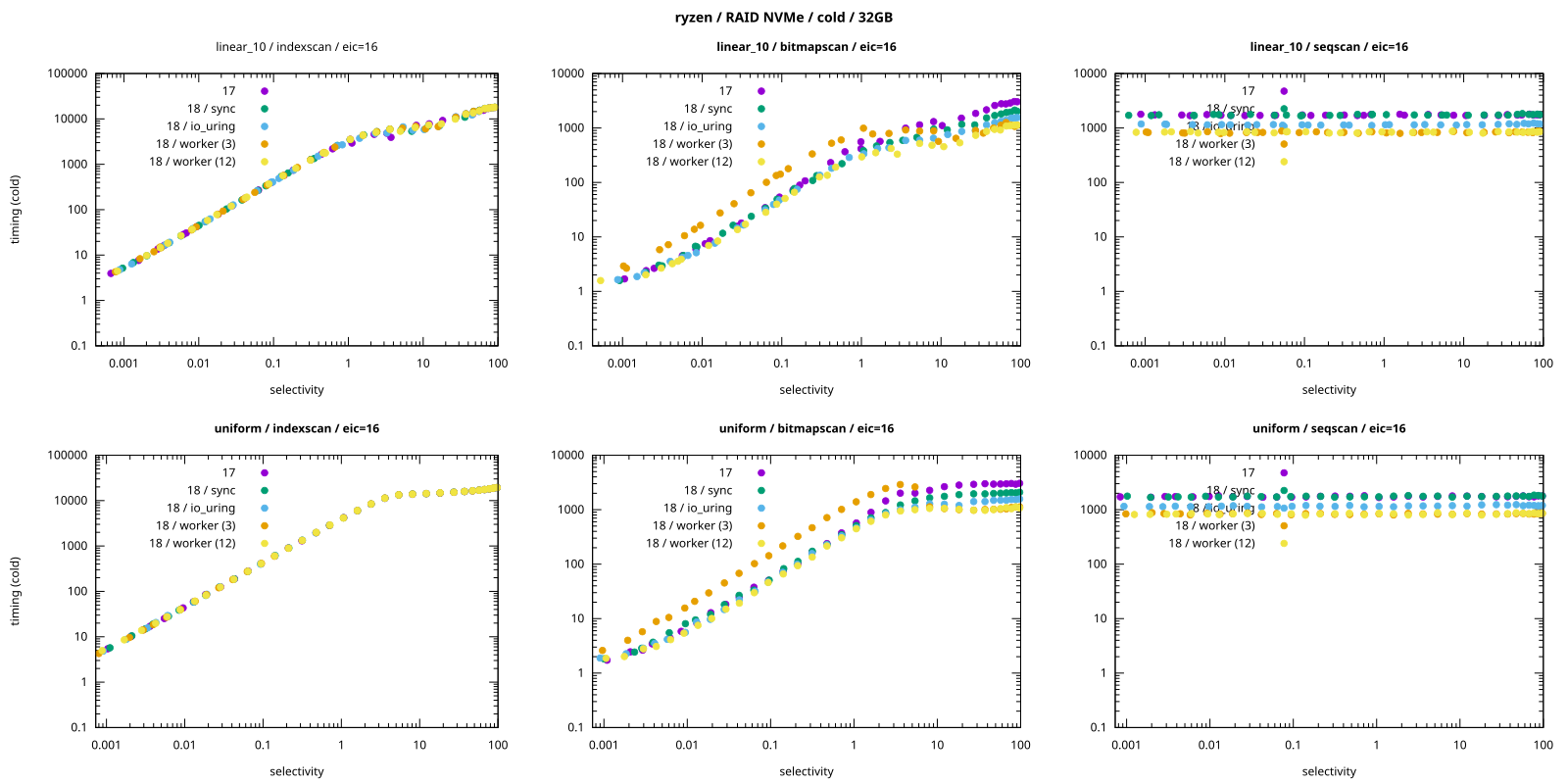
The poor performance of worker with 3 I/O workers for bitmap scans is even more visible with log-
scale y-axis [PDF]:
The io_workers=3 configuration is consistently the slowest (in the linear chart this was almost
impossible to notice).
The good thing is that while I/O workers are not free, they are not too expensive either. So if you
have extra workers, that’s probably better than having too few.
In the future, we’ll probably make this “adaptive” by starting/stopping workers based on demand.
So we’d always have just the right number. There’s even a WIP patch, but it didn’t make it into
Postgres 18. (This would be a good time to take a look and review it!)
AdviceAdviceAdviceAdvice: Consider increasing io_workers. I don’t have a great value or formula to use, maybe
something like 1/4 of cores would work?
Trade offs
There’s no universally optimal configuration. I saw suggestions to “use io_uring for maximum
efficiency”, but the earlier benchmark clearly shows io_uring being significantly slower than
worker for sequential scans.
Don’t get me wrong. I love io_uring, it’s a great interface. And the advice is not “wrong” either.
Any tuning advice is a simplification, and there will be cases contradicting it. The world is never as
simple as the advice makes it seem. It hides the grotty complexity behind a much simpler rule,
that’s the whole point of having such advice.
So what are the trade offs and differences between the AIO methods?
bandwidth
One big difference between io_uring and worker is where the work happens. With io_uring, all
the work happens in the backend itself, while with worker this happens in a separate process.
This may have some interesting consequences on bandwidth, depending on how expensive it’s to
handle the I/O. And it can be fairly expensive, because it involves:
the actual I/O
verifying checksums (which are enabled by default in Postgres 18)
copying the data into shared buffers
With io_uring, all of this happens in the backend itself. The I/O part may be more efficient, but the
checksums / memcpy can be a bottleneck. With worker, this work is effectively divided between
the workers. If you have one backend and 3 workers, the limits are 3x higher.
Of course, this goes the other way too. If you have 16 connections, then with io_uring this is 16
processes that can verify checksums, etc. With worker, the limit is whatever io_workers is set to.
This is where my advice to set io_workers to ~25% of the cores comes from. I can imagine going
higher, possibly up to one IO worker per core. In any case, 3 seems clearly too low.
Note:Note:Note:Note: I believe the ability to spread costs over multiple processes is why worker outperforms
io_uring for sequential scans. The ~20% difference seems about right for checksums and
memcpy in this benchmark.
signals
Another important detail is the cost of inter-process communication between the backend and the
IO worker(s), which is based on UNIX signals. Performing an I/O looks like this:
1. backend adds a read request to a queue in shared memory
2. backend sends a signal to a IO worker, to wake it up
3. IO worker performs the I/O requested by the backend, and copies the data into shared buffers
4. IO worker sends a signal the backend, notifying it about the I/O completion
In the worst case, this means a round trip with 2 signals per 8K block. The trouble is, signals are not
free - a process can only do a finite number of those per second.
I wrote a simple benchmark, sending signals between two processes. On my machines, this reports
250k-500k round trips per second. If each 8K block needs a round trip, this means 2-4GB/s. That’s
not a lot, especially considering the data may already be in page cache, not just for cold data read
from storage. According to a test copying data from page cache, a process can do 10-20GB/s, so
about 4x more. Clearly, signals may be a bottleneck.
NoteNoteNoteNote: The exact limits are hardware-specific, and may be much lower on older machines. But the
general observation holds on all machines I have access to.
The good thing is this only affects a “worst case” workload, reading 8KB pages one by one. Most
regular workloads don’t look like this. Backends usually find a lot of buffers in shared memory
already (and then no I/O is needed). Or the I/O happens in larger chunks thanks to look-ahead,
which amortizes the signal cost over many blocks. I don’t expect this to be a serious problem.
There’s a longer discussion about the AIO overheads (not just due to signals) in the index
prefetching thread.
file limit
The io_uring doesn’t need any IPC, so it’s not affected by the signal overhead, or anything like
that. But io_uring has limits too, just in a different place.
For example, each process is subject to per-process bandwidth limits (e.g. how much memcpy can
a single process do). But judging by the page-cache test, those limits are fairly high - 10-20GB/s, or
so.
Another thing to consider is that io_uring may need a fair number of file descriptors. As explained
in this pgsql-hackers thread:
The issue is that, with io_uring, we need to create one FD for each possible child
process, so that one backend can wait for completions for IO issued by another
backend [1]. Those io_uring instances need to be created in postmaster, so they’re
visible to each backend. Obviously that helps to much more quickly run into an
unadjusted soft RLIMIT_NOFILE, particularly if max_connections is set to a
higher value.
So if you decide to use io_uring, you may need to adjust ulimit -n too.
NoteNoteNoteNote: This is not the only place in Postgres code where you may run into the limit on file
descriptors. About a year ago I posted a patch idea related to file descriptor cache. Each backend
keeps up to
max_files_per_process
open file descriptors, and by default that GUC is set to
1000. That used to be enough, but with partitioning (or schema per tenant) it’s fairly easy to trigger
a storm of expensive open/close calls. That’s a separate (but similar) issue.
Summary
AIO is a massive architectural change, and in Postgres 18 it has various limitations. It only supports
reads, and some operations still use the old synchronous I/O. Those limitations are not permanent,
and should be addressed in future releases.
Based on the discussion in this blog post, my tuning advice is to:
Keep the Keep the Keep the Keep the io_method = worker default default default default, unless you can demonstrate the io_uring actually
works better for your workload. Use sync only if you need a behavior as close to Postgres 17 as
possible (even if it means being slower in some cases).
Increase Increase Increase Increase io_workers to a value considering the total number of cores. Something like 25%
cores seems reasonable, possibly even 100% in extreme cases.
If you come up with some interesting observations, please report them either to me or (even better)
to the pgsql-hackers, so that we can consider that when adding tuning advice to the docs.
September 24, 2025 postgres aio tuning performance io_method io_workers worker
io_uring signal file descriptor
Do you have feedback on this post? Please reach out by e-mail to tomas@vondra.me.
2025 © Tomas Vondra | Ink theme on Hugo
of 1
免费下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

{kind=link}
{kind=link}
文档被以下合辑收录
评论