




SequoiaDB分布式集群生态工具及容器化部署实战.pdf
50墨值下载

SequoiaDB 分布式集群生态工具及容器化部署实战
本次分享的主要内容为:1)巨杉数据库集群架构简介;2)巨杉数据库分片原理及高可用性;
3)基于 Docker 镜像部署分布式集群实战;4)巨杉数据库周边生态工具。
演讲实录
大家好,我叫杜蓉,今天分享主题是 SequoiaDB 分布式集群容器化部署实战。先做一个简单
的自我介绍,我来巨杉技术社区,之前在网易任职高级 DBA,近几个月与社区技术同学做了
很多沟通交流,对巨杉数据库也有了自己的认识和理解,总结下来分享给大家,欢迎大家多
多交流和支持。
今天的分享从下面四分方面展开,分享一下巨杉数据库的分布式集群架构,以及弹性扩容和
高可用性,然后给大家实战演示一下用 Docker 部署巨杉数据库分布式集群,最后分享一下
巨杉数据库生态工具。
巨杉数据库作为分布式数据库是计算和存储分离架构,有数据库实例层和存储引擎层组成
的。存储引擎层负责数据库核心功能比如数据读写存储以及分布式事务管理。数据库实例层
也就是这里的的 SQL 层负责把应用 sql 请求处理后发存储引擎层处理,并且把存储引擎层响
应结果反馈给应用层。支持结构化实例比如 MySQL 实例/PG 实例/Spark 实例,也支持非结构
化实例 比如 Json 实例/S3 对象存储实例/PosixFs 实例等等。这种架构支持的实例类型比较
多,方便从传统数据库无缝迁移到巨杉数据库,减小了开发学习成本,之前也跟数据库圈同
行交流,他们对架构也是十分认可。
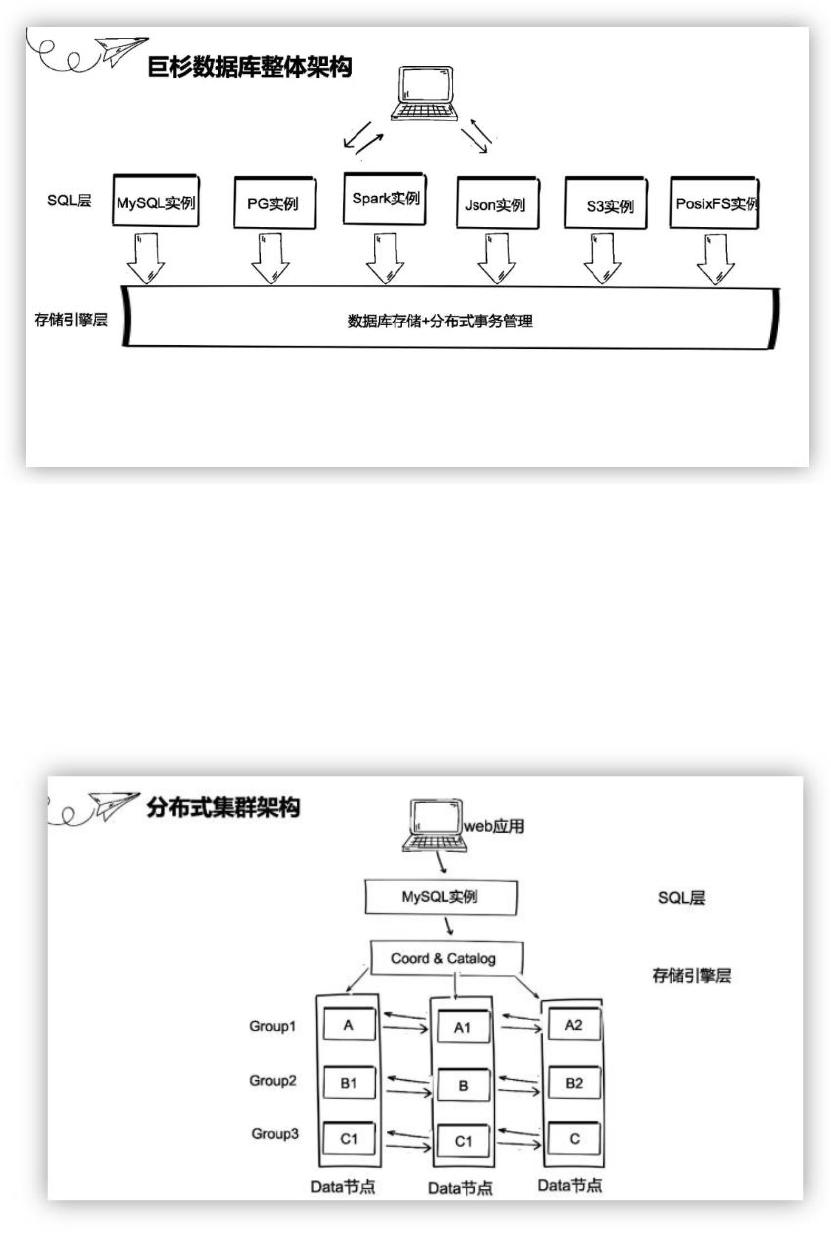
这里给大家展示一下一个具体的巨杉分布式集群架构实例,也是今天要进行 docker 部署集
群架构,这里的 SQL 层采用的是 MySQL 实例,存储引擎层是有三个数据节点和协调节点编
目节点组成。其中数据节点就是用来存储数据的,协调节点不存储数据,是用来把 MySQL
的请求进行路由分发到数据库节点。编目节点用来存储集群的系统信息比如用户信息/分区
信息等等。这里用一个容器来模拟一个物理机或云虚拟机,这里设置的是 Mysql 实例在一个
容器里,编目和节点和协调节点放在了一个容器,三个数据节点分别放在一个容器,三个数
据节点构成了三个数据组,每个数据组三个副本。Web 应用的海量数据是通过分片切分的
方 式 分 散 给 不 同 的 数 据 节 点 , 像 这 里 的 数 据 ABC 通 过 分 片 打 散 到 三 台 机 器 。
这里是数据分片是通过分布式 Hash 算法 DHT 机制实现,DHT 是 distribute Hashing table 缩
写。当写入数据时,首先通过 MySQL 实例把记录下发到协调节点,协调节点会通过分布式
Hash 算法根据每条记录的分区键 partionkey 进行散列,散列完之后协调节点根据分区键判
of 9
50墨值下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

评论