




巨杉Tech SequoiaDB数据域及存储规划.pdf
50墨值下载
巨杉 Tech | SequoiaDB 数据域及存储规划
1 背景
近年来,企业的各项业务发展迅猛,客户数目不断增加,后台服务系统压力也越
来越大,系统的各项硬件资源也变得非常紧张。因此,在技术风险可控的基础上,
希望引入大数据技术,利用大数据技术优化现有 IT 系统实现升级改造,搭建一
个统一存储和管理历史、近线数据的服务平台,同时能够对外支持高并发、低延
时的数据查询服务,以提高 IT 系统的计算能力,降低 IT 系统的建设成本,优化
IT 系统的服务体系,为各个业务部门提供更加优质的 IT 服务。
这类服务平台在整个 IT 系统架构中实质上是一个为核心业务系统减负的系统。
SequoiaDB 巨杉数据库支持海量分布式数据存储,并且支持垂直分区和水平分
区,利用这些特性可以将历史、近线数据存储到 SequoiaDB 中,并能够对外支
持高并发、低延时的数据查询服务。本文主要讲解如何利用巨杉数据库域的特性
在历史、近线数据应用场景下进行存储规划已满足业务系统对性能、存储、维护
等方便的要求。
2 相关概念
多维度数据分区
SequoiaDB 支持水平和垂直方式分区。采用散列(hash)或范围(range)水平分区
是将数据分布至多个节点,加大数据吞吐量, 加速数据查询和写入;采用范围
(range)垂直分区是在一个节点内将数据逻辑划分为多个区间,每个区间作为
独立的存储单元,减少查询时网络 I/O, 进一步加速查询。
水平分区
散列水平分区,原理是将选择的分区键进行 hash 运算,根据 hash 值将数据分
发至相应分区。范围水平分区则是直接匹配分区键和所对应的范围,存放到相应
的分区。两种分区方式各有适用的场景,和运行的业务息息相关。一般不建议采
用范围水平分区,除范围分区键(如月)能保证数据均衡(如每月的数据量级一
致)。如图 2-1 所示。
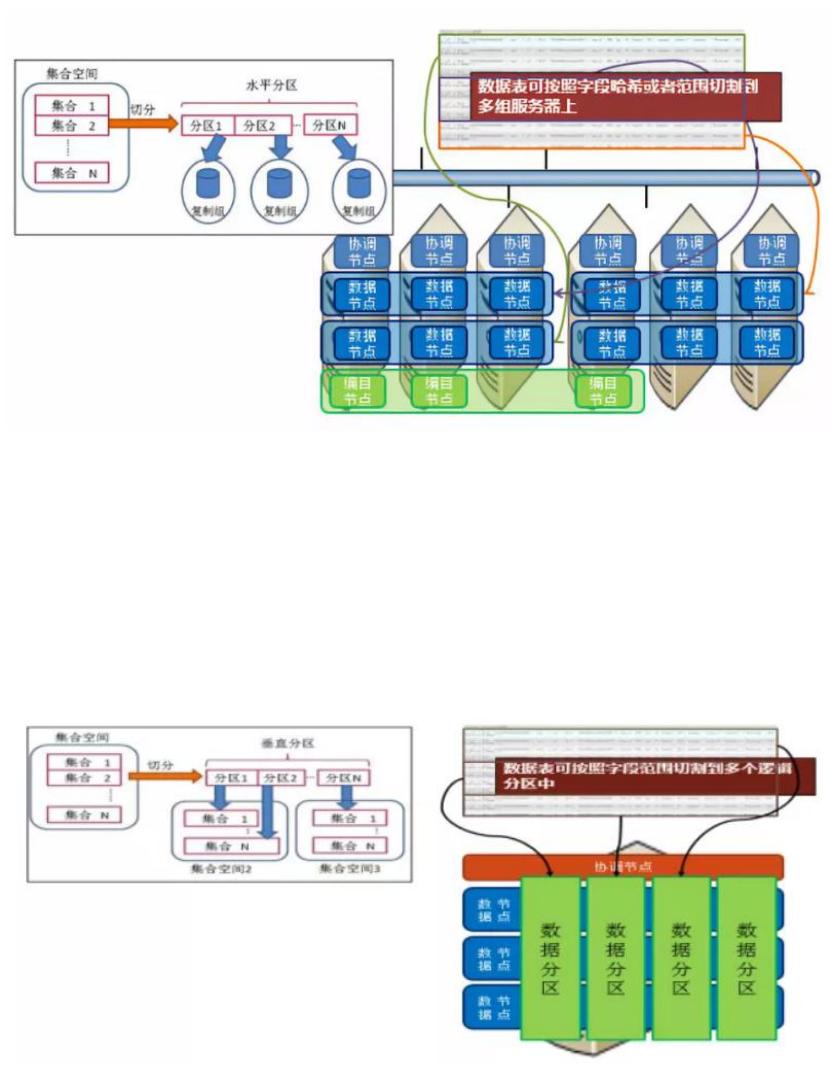
图 2-1. SequoiaDB 水平分区
垂直分区
垂直分区是指在一个节点内集合数据按某字段,分成成多个数据段。每个范围代
表一个垂直分区。数据查询、写入时自动分发至相应分区中。垂直分区极大减少
硬盘数据访问,降低网络 I/O,加速查询。垂直分区共享资源(同一台物理机),
出发点在于将冷热数据隔离,如图 2-2 所示。
图 2-2. SequoiaDB 垂直分区
复制组和域
分区组又被称为复制组,一个复制组内可以包含一个或多个数据节点(或编目节
点),节点之间的数据使用异步日志复制机制,保持最终一致。
域(Domain)是由若干个复制组(ReplicaGroup)组成的逻辑单元。每个域都可
以根据定义好的策略自动管理所属数据,如数据切片和数据隔离等。
of 6
50墨值下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

评论