




28.An Associate-Predict Model for Face Recognition.pdf
50墨值下载
An Associate-Predict Model for Face Recognition
Qi Yin
1,3
1
Department of Information Engineering
The Chinese University of Hong Kong
Xiaoou Tang
1,2
2
Shenzhen Institutes of Advanced Technology
Chinese Academy of Sciences, China
Jian Sun
3
3
Microsoft Research Asia
Abstract
Handling intra-personal variation i s a major challenge
in face recognition. It is difficult how to appropriately
measure the simil arity between human faces under signif-
icantly different settings (e.g., pose, illumination, and ex-
pression). In this paper, we propose a new model, called
“Associate-Predict” (AP) model, to address this issue. The
associate-predict model is built on an extra generic identity
data set, in which each identity contains multiple images
with large intra-personal variation. When considering two
faces under significantly different settings (e.g., non-frontal
and frontal), we first “associate” one input face with alike
identities from the generic identity date set. Using the ass o-
ciated faces, we generatively “predict” the appearance of
one input face under the setting of another input face, or
discriminatively “predict” the likelihood whether two input
faces are from the same person or not. We call the two pro-
posed prediction methods as “appearance-prediction” and
“likelihood-prediction”. By leveraging an extra data set
(“memory”) and the “associate-predict” model, the intra-
personal variation can be effectively handled.
To improve the generalization ability of our model, we
further add a switching mechanism - we directly com-
pare the appearances of two faces if they have close intra-
personal settings; otherwise, we use the associate-predict
model for the recognition. Experiments on two public face
benchmarks (Multi-PIE and LFW) demonstrated that our
final model can substantially improve the performance of
most existing face recognition methods
1. Introduction
In the past two decades, the appearance-based ap-
proaches [7, 9, 12, 13, 20, 23, 28, 30, 32, 34] have dom-
inated the face recognition field due to their good perfor-
mance and simplicity. However, large intra-personal varia-
tion, like pose, illumination, and expression, remains an in-
evitable obstacle because it results in significant appearance
change, geometric misalignment, and self-occlusion. For
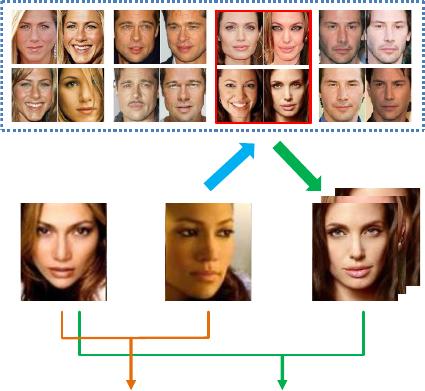
example, A and B in Figure 1 are two photos of the same
A
B B’
“Associate” “Predict”
Appearance-based
matching
Prediction-based
matching
Memory
Figure 1. The ”Associate-Predict” model. A and B are two faces of
“Jennifer Lopez”, with significantly different settings (e.g., pose,
lighting, and expression). Conventional methods (“Appearance-
based matching”) compare them directly. In our model, we asso-
ciate a similar generic identity of the face B at the first step. Then,
we predict the new appearance (B’) of B under the similar setting
of A. Using the predicted new face(s), we perform “Prediction-
based matching”. Note that this figure is only for the illustration
purpose. We use facial components (instead of the whole face
shown here) as the basic element.
person. The appearances of the two faces are so different
that any appearance-based approach may draw a conclusion
that they are not the same person. But why our human brain
has the ability to recognize faces with large intra-personal
variation?
Built upon the studies of brain theories, Jeff Hawkins [8]
gave his definition on the intelligence: “your brain receives
patterns from the outside world, stores them as memories,
and makes predictions by combining what it has seen before
and what is happening now.”. In a nutshell, he measures the
497

intelligence by the capacity to remember and predict pat-
terns in the world. Despite that this definition is arguable,
we may still get useful inspirations from it.
In this paper, we conjecture that our brain adopts prior
knowledge/memories to predict the possible transition be-
tween two faces under significantly different settings. For
example, our brain may be able to associate similar facial
patterns from all face images we have seen in our life, and
imagine the reasonable appearance of the input face under
a different setting (for example, predict from a non-frontal
face to its frontal version). After the association and pre-
diction, our brain can do direct appearance comparison be-
tween two faces with consistent settings.
Based on the above conjecture, we propose an
“Associate-Predict” (AP) model for face recognition. The
model is built on a prior identity data set (“memory”), where
each identity has multiple face images with large intra-
personal variation. This data set is treated as a critical
“bridge” to reveal how the same face may vary under dif-
ferent intra-personal settings. If we are going to compare a
face pair, we first associate the input face with a few of most
similar identities from the “memory”, and then predict the
new appearance of the input face under different settings
(“appearance-prediction”) or directly predict the recogni-
tion output (“likelihood-prediction”), as shown in Figure 3.
In the “appearance-prediction”, given two input faces,
we select a specific face image from the associated identity
to replace one input face. The selected face is required to
have the consistent intra-personal setting with the other in-
put face. The selected face is our predicted/imagined image
from one setting to the other setting. As a result, the two
input faces are “transited” into the same setting, and we can
appropriately use any existing appearance-based approach
to match them. For example, suppose face A is frontal while
face B is left-oriented. To compare them, we select a left-
oriented face A’ from the associated identity of A to replace
the original face A and compute the appearance-based sim-
ilarity between A’ and B.
In the “likelihood-prediction”, we first ass ociate a few
most similar identities of one input face. Then, we con-
struct a discriminative classifier using the associated faces
of these identities as positive samples and a fixed set of
“background” face images as negative samples. The trained
person-specific classifier is used to tell if two input faces
are from the same person. Since the associated positive
samples cover wider intra-personal variation, the resulting
classifier can preserve person-specific discriminative infor-
mation better and be more robust to apparent intra-personal
variation.
In the above text, we refer the term “face” as our ba-
sic matching element for clarity. In our system, we use
twelve facial components as the basic elements for the asso-
ciation/prediction since it is easier to associate a very alike
generic identity at the component level than at the holistic
face level.
Our associate-predict model works best when the setting
of two input faces are quiet different. But due to the lim-
ited size of our identity data set, our model may be less
discriminative than the direct appearance comparison when
two input faces have similar settings. This is true and ver-
ified in our experiments. Here, we make the second con-
jecture that our brain does direct appearance matching be-
tween two faces under similar settings.
To realize the second conjecture, we enhance our model
with a switching mechanism - we do direct appearance
matching if two faces have close intra-personal settings;
otherwise, we apply the associate-predict model to handle
the large intra-personal variation. This hybrid model helps
us to get the best of both worlds.
With the associate-predict model and the switching
mechanism, our approach significantly improves over the
current appearance-based systems. The evaluations on two
complementary benchmarks, Multi-PIE and LFW, demon-
strated that our system can consistently achieve the leading
performance
1
, while maintaining very good generalization
ability.
2. Related Works
The descriptor-based methods [3, 5, 9, 16, 18, 24, 31, 32]
and subspace-based methods [1, 14, 15, 17, 19, 26, 28,
29, 30, 35] are two representative appearance-based ap-
proaches. The descriptor-based methods extract discrimi-
native information from the facial micro-structures, and the
subspace-based algorithms learn an optimal subspace for
recognition. Generally, all the appearance-based methods
confront the tradeoff between the discriminative ability and
the invariance to intra-personal variation.
To cope with the intra-personal variation, many current
researches [10, 21, 27, 32, 33] apply prior knowledge in
face recognition. Blanz et al. [2] used the prior morphable
3D models to simulate the 3D appearance transformation of
the input face. Wolf et al. [32, 33] proposed to train binary
classifier using a single positive sample and a set of prior
background negative samples. To solve the problem of lim-
ited positive s amples, Kim et al. [ 10] and Wang et al. [21]
adopted manually designed transformation to generate vir-
tual positive samples. But the virtual positive samples are
usually limited in quality and variation degree.
Our work is also related to an interesting face-sketch
transformation idea proposed in [25]. In order to compare
one person’s photo with another person’s sketch, an iden-
tity database of photo-sketch pairs was constructed. An in-
put photo is reconstructed by a linear combination of the
1
Since we use an extra identity date set as prior knowledge, it may be
unfair to be compared with some approaches without requiring extra data.
But our cross-data experiments show that we do not overfit the data.
498
of 8
50墨值下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

评论