




SequoiaDB 数据分区简介.pdf
50墨值下载

SequoiaDB 数据分区简介
SequoiaDB 数据分区的优势
SequoiaDB 数据分区的含义是,把逻辑上的一个大的数据集合,按某一个或多个字段的值将
一个大的集合划分成若干个小集合,再将这些小集合分别存放在物理上的不同区块上(相同
物理机器上的不同磁盘或不同物理机器上)。数据分区的好处不仅仅能带来数据访问速度的
大幅提升,它还能带来管理和维护上的方便。
高速访问:在数据访问速度上,对集合数据进行数据分区后,当数据库接收到客户端请求访
问该集合中的某一条数据对象时,数据库分两种情况对该请求进行检索,如果该集合已经建
立了索引,并且该索引的索引字段正好包含此次请求的检索条件,数据库可以直接通过索引
文件命中该数据对象。特别的,如果该集合是通过垂直分区的方式进行数据分区,当请求的
检索条件包含主表的分区键时,将直接访问包含该分区键的对应子表,仅仅对该子表进行全
表扫描,而不用对整个集合进行全表扫描。
无索引字段:如果检索条件不包含在任何索引的索引字段中,则数据库将进行全表扫描,在
该集合对应的所有的分区上同时进行数据检索操作,换句话说,也就是在各个分区对应的不
同的物理机器或磁盘上并行的进行数据的检索,这样就完成了将某一个请求映射到不同的物
理磁盘以平衡 IO。从而线性的提高了检索速度。
数据的管理和维护:对数据进行数据分区后,将会让一个大的数据集合,划分为若干个小的
数据集合,这些小的集合分别可以存储在不同的分区组上,如果某个分区组出现意外故障,
则可以只从该复制组的另一台机器上同步该分区的数据过来修复分区即可。不用进行整个集
合的修复的高 IO 耗时操作。
默认情况下即创建集合空间和集合时不指定任何数据分区相关的参数,该集合存储数据时会
将数据存放在一个复制组内。随着集合数据量的增加和频繁的 CURD 操作。将会导致物理机
IO 的增加,从而导致物理机的高负荷压力增加和访问集合数据的速度变慢。
SequoiaDB 分区类型
SequoiaDB 提供三种数据分区类型,即水平分区、垂直分区和混合分区。注意,这里的分区
概念是一种逻辑的概念,通过逻辑分区的概念,方便用户更好的区分和管理数据。
水平分区
水平分区又称为数据库分区或横向分区,水平分区可以将集合按照分区键(包含一个或多个
字段)切分成若干分区,并将分区指定到不同的复制组中,图示如图 1:
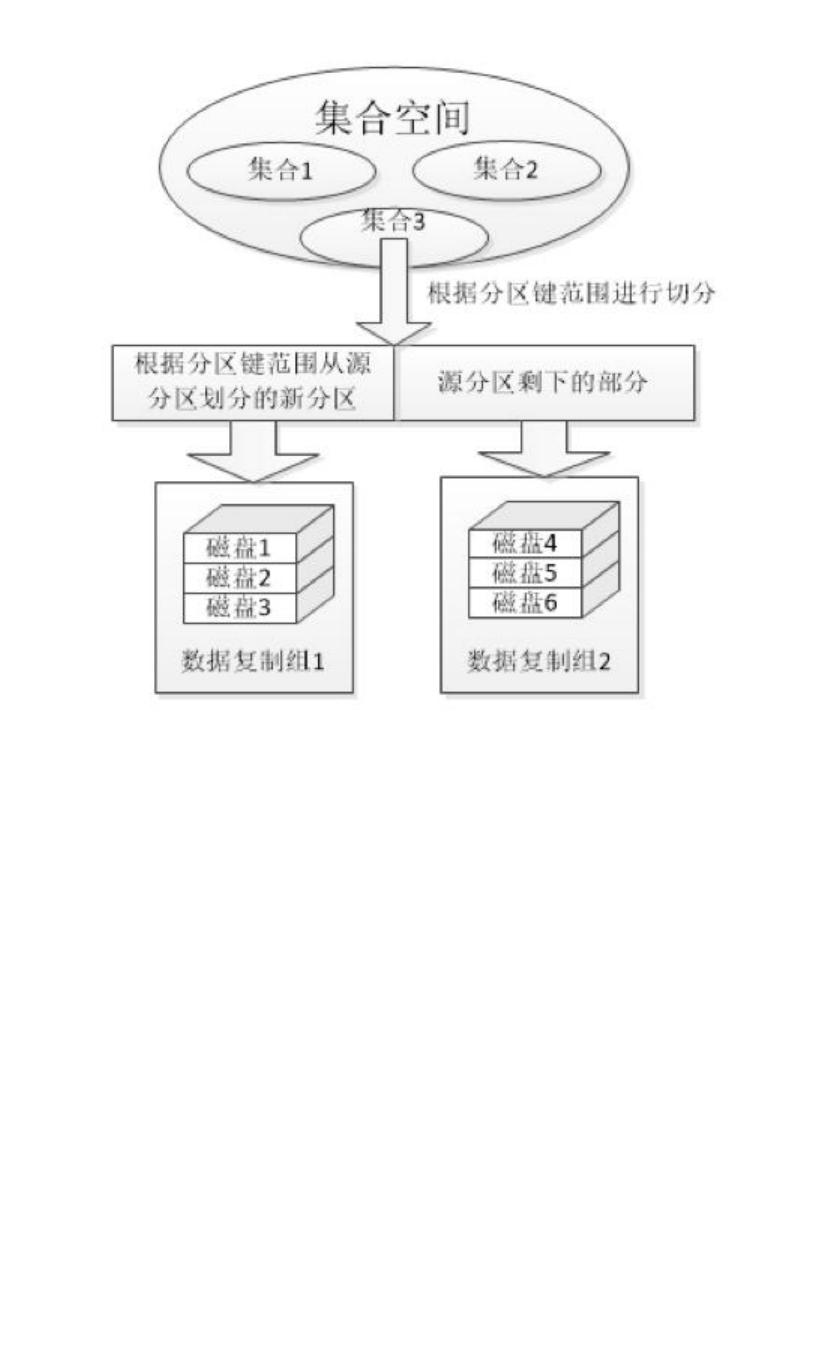
图 1
图中,将集合空间中的集合 2 进行了水平分区,将集合中的数据按照分区键切分到范围为
1-N 的分区中,每个分区可以对应不同的复制组,当请求访问某一条数据对象,就会将请求
分发给不同的复制组,将查询速度平均提高了 N 倍,线性的提高了检索速度。
垂直分区
垂直分区又称为集合分区或纵向分区。SequoiaDB 集群环境中,用户不同与传统关系型数据
库的视图的概念,将几个表的数据通过视图的方式拼合在一起构成一张虚表,从逻辑上层面
上将所需要的数据抽取出来。
SequoiaDB 的垂直分区虽然也是将不同的集合数据通过一个主集合进行统一管理,主集合也
不存放数据记录,只是作为方便维护子集合,不过是通过集合中的某一个或多个字段作为分
区键,将集合划分成若干个子集,并在主集合和子集合上通过分区键范围建立主集合和子集
合之间的关联
协调节点处理客户端的一个数据请求进行检索时,在主表上进行检索,将会根据主表上的分
区键范围,将该数据访问请求分发到映射的各个子集合中,如果查找条件包含主表的分区键
字段,将直接对相应的子表进行查找,直接在该子集合上检索该数据,而不用进行在所有子
of 8
50墨值下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

评论