




14.Fast R-CNN.pdf
50墨值下载

Fast R-CNN
Ross Girshick
Microsoft Research
rbg@microsoft.com
Abstract
This paper proposes a Fast Region-based Convolutional
Network method (Fast R-CNN) for object detection. Fast
R-CNN builds on previous work to efficiently classify ob-
ject proposals using deep convolutional networks. Com-
pared to previous work, Fast R-CNN employs several in-
novations to improve training and testing speed while also
increasing detection accuracy. Fast R-CNN trains the very
deep VGG16 network 9× faster than R-CNN, is 213× faster
at test-time, and achieves a higher mAP on PASCAL VOC
2012. Compared to SPPnet, Fast R-CNN trains VGG16 3×
faster, tests 10× faster, and is more accurate. Fast R-CNN
is implemented in Python and C++ (using Caffe) and is
available under the open-source MIT License at https:
//github.com/rbgirshick/fast-rcnn.
1. Introduction
Recently, deep ConvNets [14, 16] have significantly im-
proved image classification [14] and object detection [9, 19]
accuracy. Compared to image classification, object detec-
tion is a more challenging task that requires more com-
plex methods to solve. Due to this complexity, current ap-
proaches (e.g., [9, 11, 19, 25]) train models in multi-stage
pipelines that are slow and inelegant.
Complexity arises because detection requires the ac-
curate localization of objects, creating two primary chal-
lenges. First, numerous candidate object locations (often
called “proposals”) must be processed. Second, these can-
didates provide only rough localization that must be refined
to achieve precise localization. Solutions to these problems
often compromise speed, accuracy, or simplicity.
In this paper, we streamline the training process for state-
of-the-art ConvNet-based object detectors [9, 11]. We pro-
pose a single-stage training algorithm that jointly learns to
classify object proposals and refine their spatial locations.
The resulting method can train a very deep detection
network (VGG16 [20]) 9× faster than R-CNN [9] and 3×
faster than SPPnet [11]. At runtime, the detection network
processes images in 0.3s (excluding object proposal time)
while achieving top accuracy on PASCAL VOC 2012 [7]
with a mAP of 66% (vs. 62% for R-CNN).
1
1.1. R-CNN and SPPnet
The Region-based Convolutional Network method (R-
CNN) [9] achieves excellent object detection accuracy by
using a deep ConvNet to classify object proposals. R-CNN,
however, has notable drawbacks:
1. Training is a multi-stage pipeline. R-CNN first fine-
tunes a ConvNet on object proposals using log loss.
Then, it fits SVMs to ConvNet features. These SVMs
act as object detectors, replacing the softmax classi-
fier learnt by fine-tuning. In the third training stage,
bounding-box regressors are learned.
2. Training is expensive in space and time. For SVM
and bounding-box regressor training, features are ex-
tracted from each object proposal in each image and
written to disk. With very deep networks, such as
VGG16, this process takes 2.5 GPU-days for the 5k
images of the VOC07 trainval set. These features re-
quire hundreds of gigabytes of storage.
3. Object detection is slow. At test-time, features are
extracted from each object proposal in each test image.
Detection with VGG16 takes 47s / image (on a GPU).
R-CNN is slow because it performs a ConvNet forward
pass for each object proposal, without sharing computation.
Spatial pyramid pooling networks (SPPnets) [11] were pro-
posed to speed up R-CNN by sharing computation. The
SPPnet method computes a convolutional feature map for
the entire input image and then classifies each object pro-
posal using a feature vector extracted from the shared fea-
ture map. Features are extracted for a proposal by max-
pooling the portion of the feature map inside the proposal
into a fixed-size output (e.g., 6 × 6). Multiple output sizes
are pooled and then concatenated as in spatial pyramid pool-
ing [15]. SPPnet accelerates R-CNN by 10 to 100× at test
time. Training time is also reduced by 3× due to faster pro-
posal feature extraction.
1
All timings use one Nvidia K40 GPU overclocked to 875 MHz.
arXiv:1504.08083v2 [cs.CV] 27 Sep 2015
SPPnet also has notable drawbacks. Like R-CNN, train-
ing is a multi-stage pipeline that involves extracting fea-
tures, fine-tuning a network with log loss, training SVMs,
and finally fitting bounding-box regressors. Features are
also written to disk. But unlike R-CNN, the fine-tuning al-
gorithm proposed in [11] cannot update the convolutional
layers that precede the spatial pyramid pooling. Unsurpris-
ingly, this limitation (fixed convolutional layers) limits the
accuracy of very deep networks.
1.2. Contributions
We propose a new training algorithm that fixes the disad-
vantages of R-CNN and SPPnet, while improving on their
speed and accuracy. We call this method Fast R-CNN be-
cause it’s comparatively fast to train and test. The Fast R-
CNN method has several advantages:
1. Higher detection quality (mAP) than R-CNN, SPPnet
2. Training is single-stage, using a multi-task loss
3. Training can update all network layers
4. No disk storage is required for feature caching
Fast R-CNN is written in Python and C++ (Caffe
[13]) and is available under the open-source MIT Li-
cense at https://github.com/rbgirshick/
fast-rcnn.
2. Fast R-CNN architecture and training
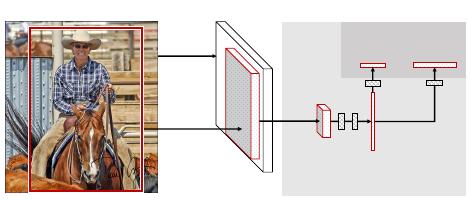
Fig. 1 illustrates the Fast R-CNN architecture. A Fast
R-CNN network takes as input an entire image and a set
of object proposals. The network first processes the whole
image with several convolutional (conv) and max pooling
layers to produce a conv feature map. Then, for each ob-
ject proposal a region of interest (RoI) pooling layer ex-
tracts a fixed-length feature vector from the feature map.
Each feature vector is fed into a sequence of fully connected
(fc) layers that finally branch into two sibling output lay-
ers: one that produces softmax probability estimates over
K object classes plus a catch-all “background” class and
another layer that outputs four real-valued numbers for each
of the K object classes. Each set of 4 values encodes refined
bounding-box positions for one of the K classes.
2.1. The RoI pooling layer
The RoI pooling layer uses max pooling to convert the
features inside any valid region of interest into a small fea-
ture map with a fixed spatial extent of H × W (e.g., 7 × 7),
where H and W are layer hyper-parameters that are inde-
pendent of any particular RoI. In this paper, an RoI is a
rectangular window into a conv feature map. Each RoI is
defined by a four-tuple (r, c, h, w) that specifies its top-left
corner (r, c) and its height and width (h, w).
Deep
ConvNet
Conv
feature map
RoI
projection
RoI
pooling
layer
FCs
RoI feature
vector
softmax
bbox
regressor
Outputs:
FC
FC
For each RoI
Figure 1. Fast R-CNN architecture. An input image and multi-
ple regions of interest (RoIs) are input into a fully convolutional
network. Each RoI is pooled into a fixed-size feature map and
then mapped to a feature vector by fully connected layers (FCs).
The network has two output vectors per RoI: softmax probabilities
and per-class bounding-box regression offsets. The architecture is
trained end-to-end with a multi-task loss.
RoI max pooling works by dividing the h × w RoI win-
dow into an H × W grid of sub-windows of approximate
size h/H × w/W and then max-pooling the values in each
sub-window into the corresponding output grid cell. Pool-
ing is applied independently to each feature map channel,
as in standard max pooling. The RoI layer is simply the
special-case of the spatial pyramid pooling layer used in
SPPnets [11] in which there is only one pyramid level. We
use the pooling sub-window calculation given in [11].
2.2. Initializing from pre-trained networks
We experiment with three pre-trained ImageNet [4] net-
works, each with five max pooling layers and between five
and thirteen conv layers (see Section 4.1 for network de-
tails). When a pre-trained network initializes a Fast R-CNN
network, it undergoes three transformations.
First, the last max pooling layer is replaced by a RoI
pooling layer that is configured by setting H and W to be
compatible with the net’s first fully connected layer (e.g.,
H = W = 7 for VGG16).
Second, the network’s last fully connected layer and soft-
max (which were trained for 1000-way ImageNet classifi-
cation) are replaced with the two sibling layers described
earlier (a fully connected layer and softmax over K + 1 cat-
egories and category-specific bounding-box regressors).
Third, the network is modified to take two data inputs: a
list of images and a list of RoIs in those images.
2.3. Fine-tuning for detection
Training all network weights with back-propagation is an
important capability of Fast R-CNN. First, let’s elucidate
why SPPnet is unable to update weights below the spatial
pyramid pooling layer.
The root cause is that back-propagation through the SPP
layer is highly inefficient when each training sample (i.e.
RoI) comes from a different image, which is exactly how
R-CNN and SPPnet networks are trained. The inefficiency
of 9
50墨值下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

评论