




SequoiaDB在线扩容与数据迁移实践.pdf
50墨值下载

巨杉 Tech | SequoiaDB 在线扩容与数据迁移实践
1 前言
1.1 编写背景
随着业务系统非结构化数据年增长量较大并且数据越来越多。在业务系统投产后,由于业务
量的增加使得集群可使用存储容量逐渐变小,因此在业务系统接入集群前需考虑存储容量耗
尽后整个集群的水平扩展。SequoiaDB(巨杉数据库,简称 Sdb,下同)是一款金融级别的分
布式数据库,可以通过集群的扩容实现集群性能的近线性增长。通过扩容后主要解决两个问
题:数据存储的容量问题和整个集群的性能问题。因为数据量的不断增长及上线后的推广使
用,所以需要进行扩容来提升集群性能及增加数据存储空间。
通过阅读本文档,读者可以了解到 Sdb 集群如何实现扩容,以及扩容后如何做数据迁移。
文档中出现的一些专业术语,例如水平分区,垂直分区,数据域,复制组等,可参考巨杉的
官网,网址为:http://www.sequoiadb.com/cn/
2 在线扩容
2.1 生产系统数据模型分类
客户的业务系统中会存在许多数据模型,按数据量与时间维度的关系,可分
为两大类:资料类和流水类。对于上述两类不同的业务模型,其扩容和数据迁移时采用的策
略有所不同。
2.1.1 资料类模型(数据量随时间推移变化不大)
资料类模型的特点是表中数据总量不会有太大的变化,随着时间的推移,新
增的数据量占比很小。主要包含以下几类:
1.资料类:存放客户和用户资料的表,由于客户总数不会有太大的变化,因此这类表中
的数据随着时间的推移,其数据量也不会有太大的变化。
2.账户类:由于账户总数相对稳定,因此这类表中的数据量也不会有太大的变化。
3.余额类:记录每个用户的余额,和账户类的情况类似。
4.维度表:描述模型中的维度信息,数据量很小。
5.其它满足条件的资料类表。
2.1.2 流水类模型(数据量随时间推移呈线性增长)
这类模型的特点是随着时间的推移,数据量变化很大,而且通常都会和时间范围成正比,主
要包含以下几类:
1.用户操作流水
比如营业厅每天的开户,销户,转账等操作流水。随着时间的推移,该类流水表中的记录会
越来越多,而且和时间范围成正比,例如 2018 年的操作流水有 2 亿条,那么 2019 年的操作
流水差不多也有这么多。
2.用户月度账单
和用户操作流水类似,每个月的账单数据量变化不大,随着时间的推移,账单表中的数据量
会越来越多,且和时间范围成正比。
3.余额收支流水
和用户操作流水类似,记录余额的变化过程。
4. 其它满足条件的流水类表
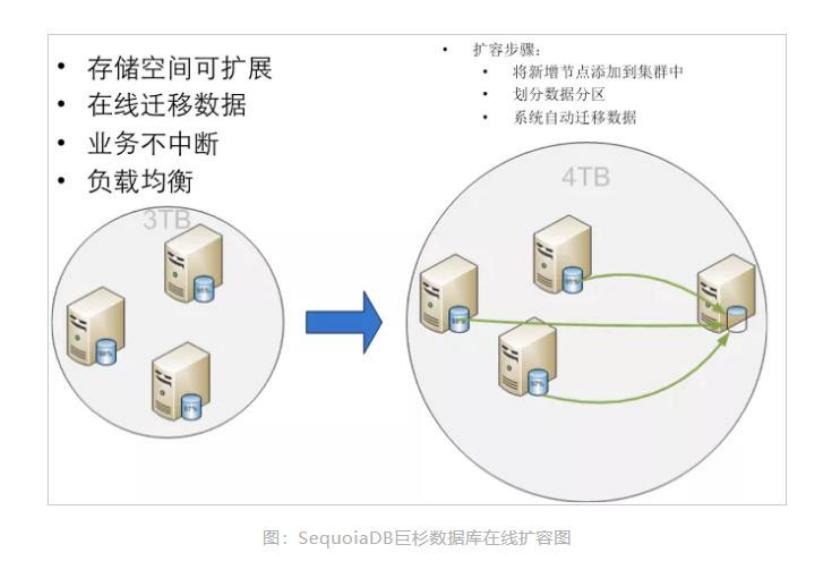
2.2 横向动态在线扩容
SequoiaDB 采用通用的开放式硬件平台,计算能力和容量均可横向扩展。SequoiaDB 可管理
PB 级别的数据。SequoiaDB 扩容同时具备以下特点:
集群扩容过程对应用系统透明,应用系统无需修配置、程序。
集群扩容速度快
支持数据均衡分布(rebalance)
如上图所示,SequoiaDB 巨杉数据库支持在线扩容,系统扩容升级快速简单。
SequoiaDB 巨杉数据库作为一款分布式数据库,在数据库架构设计之初就已经将方便快捷扩
容作为设计标准,用户在系统性能不足时,通过快速扩展集群,提升系统整体性能。
2.3 数据迁移
对于上面提到的资料类模型,通常使用水平分区的方式进行处理,而对于
流水类模型,通常使用水平分区 + 垂直分区,即多维分区表的方式进行处理。
2.3.1 数据迁移应用场景概述
数据迁移针对的对象分为两大类:资料类模型和流水类模型。
对于资料类模型,由于没有使用多维分区表,因此建议通过集合的 Split 操作将数据迁移到
新的机器上。对于流水类模型,由于使用了多维分区表的方式,因此建议在新的机器上创建
of 20
50墨值下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

评论