




MultiNet Real-time Joint Semantic Reasoning for Autonomous Driving.pdf
50墨值下载

MultiNet: Real-time Joint Semantic Reasoning for Autonomous Driving
Marvin Teichmann
123
, Michael Weber
2
, Marius Z
¨
ollner
2
, Roberto Cipolla
3
and Raquel Urtasun
14
1
Department of Computer Science, University of Toronto
2
FZI Research Center for Information Technology, Karlsruhe
3
Department of Engineering, University of Cambridge
4
Uber Advanced Technologies Group
marvin.teichmann@googlemail.com, Michael.Weber@fzi.de,
zoellner@fzi.de, rc10001@cam.ac.uk, urtasun@cs.toronto.edu
Abstract— While most approaches to semantic reasoning
have focused on improving performance, in this paper we argue
that computational times are very important in order to enable
real time applications such as autonomous driving. Towards this
goal, we present an approach to joint classification, detection
and semantic segmentation using a unified architecture where
the encoder is shared amongst the three tasks. Our approach is
very simple, can be trained end-to-end and performs extremely
well in the challenging KITTI dataset. Our approach is also
very efficient, allowing us to perform inference at more then
23 frames per second.
Training scripts and trained weights to reproduce
our results can be found here:
https://github.com/
MarvinTeichmann/MultiNet
I. INTRODUCTION
Current advances in the field of computer vision have
made clear that visual perception is going to play a key role
in the development of self-driving cars. This is mostly due to
the deep learning revolution which begun with the introduc-
tion of AlexNet in 2012 [29]. Since then, the accuracy of new
approaches has been increasing at a vertiginous rate. Causes
of this are the existence of more data, increased computation
power and algorithmic developments. The current trend is to
create deeper networks with as many layers as possible [22].
While performance is already extremely high, when deal-
ing with real-world applications, running time becomes im-
portant. New hardware accelerators as well as compression,
reduced precision and distillation methods have been ex-
ploited to speed up current networks.
In this paper we take an alternative approach and design
a network architecture that can very efficiently perform
classification, detection and semantic segmentation simulta-
neously. This is done by incorporating all three tasks into a
unified encoder-decoder architecture. We name our approach
MultiNet.
The encoder is a deep CNN, producing rich features that
are shared among all task. Those features are then utilized
by task-specific decoders, which produce their outputs in
real-time. In particular, the detection decoder combines the
fast regression design introduced in Yolo [45] with the size-
adjusting ROI-align of Faster-RCNN [17] and Mask-RCNN
[21], achieving a better speed-accuracy ratio.
Fig. 1: Our goal: Solving street classification, vehicle detec-
tion and road segmentation in one forward pass.
We demonstrate the effectiveness of our approach in the
challenging KITTI benchmark [15] and show state-of-the-
art performance in road segmentation. Importantly, our ROI-
align implementation can significantly improve detection
performance without requiring an explicit proposal gener-
ation network. This gives our decoder a significant speed
advantage compared to Faster-RCNN [46]. Our approach is
able to benefit from sharing computations, allowing us to
perform inference in less than 45 ms for all tasks.
II. RELATED WORK
In this section we review current approaches to the
tasks that MultiNet tackles, i.e., detection, classification and
semantic segmentation. We focus our attention on deep
learning based approaches.
a) Classification: After the development of AlexNet
[29], most modern approaches to image classification utilize
deep learning. Residual networks [22] constitute the state-
of-the-art, as they allow to train very deep networks without
problems of vanishing or exploding gradients. In the context
of road classification, deep neural networks are also widely
employed [37]. Sensor fusion has also been exploited in this
context [50]. In this paper we use classification to guide other
semantic tasks, i.e., segmentation and detection.
b) Detection: Traditional deep learning approaches to
object detection follow a two step process, where region
proposals [31], [25], [24] are first generated and then scored
using a convolutional network [18], [46]. Additional perfor-
mance improvements can be gained by using convolutional
neural networks (CNNs) for the proposal generation step
[10], [46] or by reasoning in 3D [6], [5]. Recently, several
2018 IEEE Intelligent Vehicles Symposium (IV)
Changshu, Suzhou, China, June 26-30, 2018
978-1-5386-4451-5/18/$31.00 ©2018 IEEE 1013
Segmentation
Decoder
Encoded
Features
39 x 12 x 512
Image
1248x384x3
Features
Scale 2
78 x 24 x 256
Features
Scale 3
156 x 48 x 128
CNN
Encoder
Prediction
1248x384x2
ROI
Align
Prediction
Scale 3
Scale 3
156 x 48 x 2
Scale 2
78 x 24 x 256
Scale 1
39 x 12 x 2
Prediction
Scale 2
Conv: 1 x 1
Prediction
Scale 3
Prediction
Scale 2
Bottleneck
37 x 10 x 30
FC with Softmax:
11100 x 2
Classification
Decoder
Prediction
1x2
Bottleneck
39 x 12 x 500
Conv: 1 x 1
Concatenated
features
39 x 12 x 1526
Conv: 1 x 1
Conv: 3 x 3
Conv: 1 x 1
Conv: 1 x 1
Add Add
Conv: 1x1
Prediction
39 x 12 x 6
Delta Prediction
39 x 12 x 6
Detection
Decoder
ROI
Align
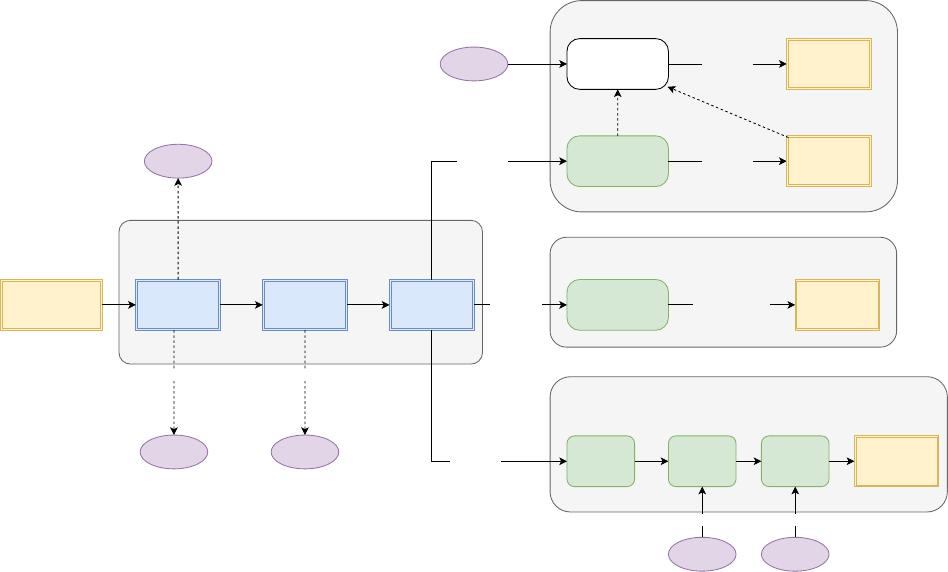
Fig. 2: MultiNet architecture.
methods have proposed to use a single deep network that
is trainable end-to-end to directly perform detection [51],
[33], [54], [33]. Their main advantage over proposal-based
methods is that they are much faster at both training and
inference time, and thus more suitable for real-time detection
applications. However, so far they lag far behind in per-
formance. In this paper we propose an end-to-end trainable
detector which reduces significantly the performance gap. We
argue that the main advantage of proposal-based methods is
their ability to have size-adjustable features. This inspired
our ROI pooling implementation.
c) Segmentation: Inspired by the successes of deep
learning, CNN-based classifiers were adapted to the task of
semantic segmentation. Early approaches used the inherent
efficiency of CNNs to implement implicit sliding-window
[19], [32]. FCN were proposed to model semantic segmen-
tation using a deep learning pipeline that is trainable end-
to-end. Transposed convolutions [59], [9], [26] are utilized
to upsample low resolution features. A variety of deeper
flavors of FCNs have been proposed since [1], [40], [47],
[42]. Very good results are achieved by combining FCN
with conditional random fields (CRFs) [61], [3], [4]. [61],
[49] showed that mean-field inference in the CRF can be
cast as a recurrent net allowing end-to-end training. Dilated
convolutions were introduced in [57] to augment the recep-
tive field size without losing resolution. The aforementioned
techniques in conjunction with residual networks [22] are
currently the state-of-the-art.
d) Multi-Task Learning: Multi-task learning techniques
aim at learning better representations by exploiting many
tasks. Several approaches have been proposed in the context
of CNNs [36], [34]. An important application for multi-task
learning is face recognition [60], [56], [44].
Learning semantic segmentation in order to perform de-
tection or instance segmentation has been studied [16], [7],
[43]. In those systems, the main goal is to perform an
instance level task. Semantic annotation is only viewed as an
intermediate result. Systems like [51], [55] and many more
design one system which can be fine-tuned to perform tasks
like classification, detection or semantic segmentation. In this
kind of approaches, a different set of parameters is learned
for each task. Thus, joint inference is not possible in this
models. The system described in [20] is closest to our model.
However this system relies on existing object detectors and
does not fully leverage the rich features learned during
segmentation for both tasks. To the best of our knowledge
our system is the first one proposed which is able to do this.
III. MULTINET FOR JOINT SEMANTIC REASONING
In this paper we propose an efficient and effective feed-
forward architecture, which we call MultiNet, to jointly
reason about semantic segmentation, image classification and
object detection. Our approach shares a common encoder
over the three tasks and has three branches, each implement-
ing a decoder for a given task. We refer the reader to Fig.
2
for an illustration of our architecture. MultiNet can be trained
end-to-end and joint inference over all tasks can be done in
less than 45ms. We start our discussion by introducing our
joint encoder, followed by the task-specific decoders.
1014
of 8
50墨值下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

评论