




22.Fully Convolutional Networks for Semantic Segmentation.pdf
50墨值下载
Fully Convolutional Networks for Semantic Segmentation
Jonathan Long
∗
Evan Shelhamer
∗
Trevor Darrell
UC Berkeley
{jonlong,shelhamer,trevor}@cs.berkeley.edu
Abstract
Convolutional networks are powerful visual models that
yield hierarchies of features. We show that convolu-
tional networks by themselves, trained end-to-end, pixels-
to-pixels, exceed the state-of-the-art in semantic segmen-
tation. Our key insight is to build “fully convolutional”
networks that take input of arbitrary size and produce
correspondingly-sized output with efficient inference and
learning. We define and detail the space of fully convolu-
tional networks, explain their application to spatially dense
prediction tasks, and draw connections to prior models. We
adapt contemporary classification networks (AlexNet [19],
the VGG net [31], and GoogLeNet [32]) into fully convolu-
tional networks and transfer their learned representations
by fine-tuning [4] to the segmentation task. We then de-
fine a novel architecture that combines semantic informa-
tion from a deep, coarse layer with appearance information
from a shallow, fine layer to produce accurate and detailed
segmentations. Our fully convolutional network achieves
state-of-the-art segmentation of PASCAL VOC (20% rela-
tive improvement to 62.2% mean IU on 2012), NYUDv2,
and SIFT Flow, while inference takes less than one fifth of a
second for a typical image.
1. Introduction
Convolutional networks are driving advances in recog-
nition. Convnets are not only improving for whole-image
classification [19, 31, 32], but also making progress on lo-
cal tasks with structured output. These include advances in
bounding box object detection [29, 12, 17], part and key-
point prediction [39, 24], and local correspondence [24, 9].
The natural next step in the progression from coarse to
fine inference is to make a prediction at every pixel. Prior
approaches have used convnets for semantic segmentation
[27, 2, 8, 28, 16, 14, 11], in which each pixel is labeled with
the class of its enclosing object or region, but with short-
comings that this work addresses.
∗
Authors contributed equally
96
384
256
4096
4096
21
21
backward/learning
forward/inference
pixelwise prediction
segmentation g.t.
256
384
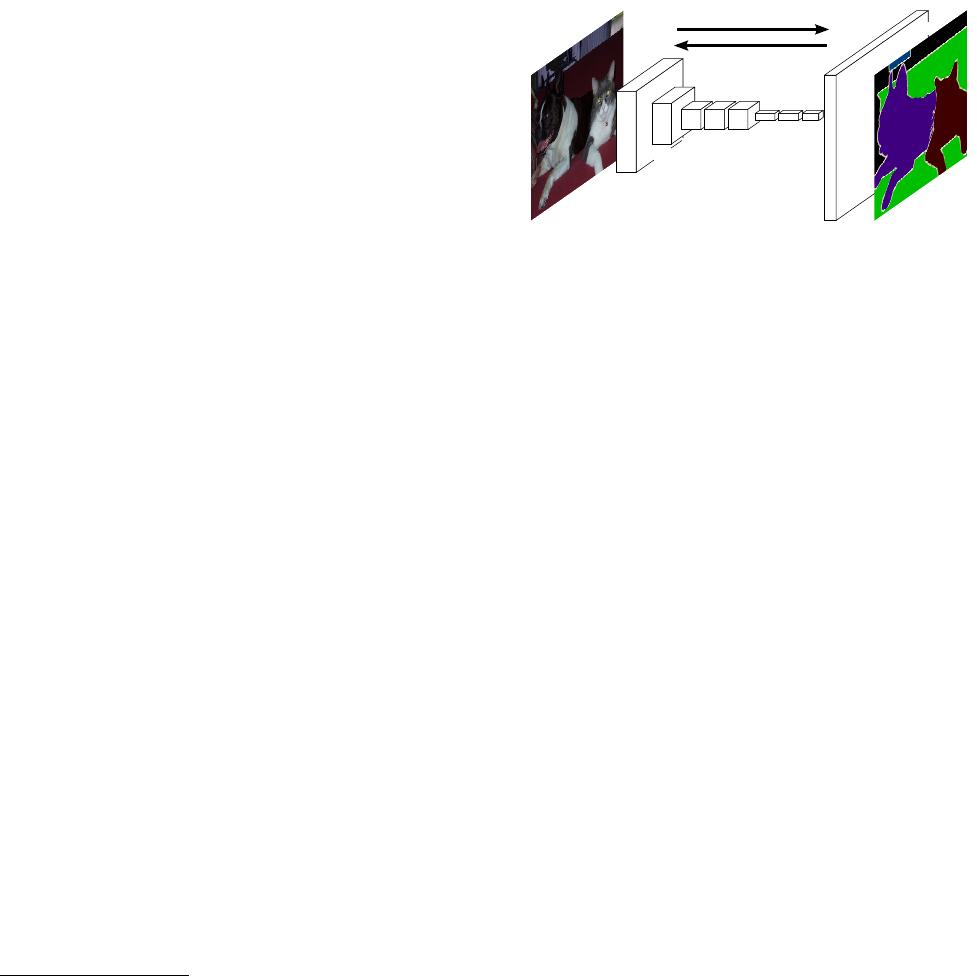
Figure 1. Fully convolutional networks can efficiently learn to
make dense predictions for per-pixel tasks like semantic segmen-
tation.
We show that a fully convolutional network (FCN),
trained end-to-end, pixels-to-pixels on semantic segmen-
tation exceeds the state-of-the-art without further machin-
ery. To our knowledge, this is the first work to train FCNs
end-to-end (1) for pixelwise prediction and (2) from super-
vised pre-training. Fully convolutional versions of existing
networks predict dense outputs from arbitrary-sized inputs.
Both learning and inference are performed whole-image-at-
a-time by dense feedforward computation and backpropa-
gation. In-network upsampling layers enable pixelwise pre-
diction and learning in nets with subsampled pooling.
This method is efficient, both asymptotically and abso-
lutely, and precludes the need for the complications in other
works. Patchwise training is common [27, 2, 8, 28, 11], but
lacks the efficiency of fully convolutional training. Our ap-
proach does not make use of pre- and post-processing com-
plications, including superpixels [8, 16], proposals [16, 14],
or post-hoc refinement by random fields or local classifiers
[8, 16]. Our model transfers recent success in classifica-
tion [19, 31, 32] to dense prediction by reinterpreting clas-
sification nets as fully convolutional and fine-tuning from
their learned representations. In contrast, previous works
have applied small convnets without supervised pre-training
[8, 28, 27].
Semantic segmentation faces an inherent tension be-
tween semantics and location: global information resolves
what while local information resolves where. Deep feature
1
arXiv:1411.4038v2 [cs.CV] 8 Mar 2015
hierarchies jointly encode location and semantics in a local-
to-global pyramid. We define a novel “skip” architecture
to combine deep, coarse, semantic information and shallow,
fine, appearance information in Section 4.2 (see Figure 3).
In the next section, we review related work on deep clas-
sification nets, FCNs, and recent approaches to semantic
segmentation using convnets. The following sections ex-
plain FCN design and dense prediction tradeoffs, introduce
our architecture with in-network upsampling and multi-
layer combinations, and describe our experimental frame-
work. Finally, we demonstrate state-of-the-art results on
PASCAL VOC 2011-2, NYUDv2, and SIFT Flow.
2. Related work
Our approach draws on recent successes of deep nets
for image classification [19, 31, 32] and transfer learning
[4, 38]. Transfer was first demonstrated on various visual
recognition tasks [4, 38], then on detection, and on both
instance and semantic segmentation in hybrid proposal-
classifier models [12, 16, 14]. We now re-architect and fine-
tune classification nets to direct, dense prediction of seman-
tic segmentation. We chart the space of FCNs and situate
prior models, both historical and recent, in this framework.
Fully convolutional networks To our knowledge, the
idea of extending a convnet to arbitrary-sized inputs first
appeared in Matan et al. [25], which extended the classic
LeNet [21] to recognize strings of digits. Because their net
was limited to one-dimensional input strings, Matan et al.
used Viterbi decoding to obtain their outputs. Wolf and Platt
[37] expand convnet outputs to 2-dimensional maps of de-
tection scores for the four corners of postal address blocks.
Both of these historical works do inference and learning
fully convolutionally for detection. Ning et al. [27] define
a convnet for coarse multiclass segmentation of C. elegans
tissues with fully convolutional inference.
Fully convolutional computation has also been exploited
in the present era of many-layered nets. Sliding window
detection by Sermanet et al. [29], semantic segmentation
by Pinheiro and Collobert [28], and image restoration by
Eigen et al. [5] do fully convolutional inference. Fully con-
volutional training is rare, but used effectively by Tompson
et al. [35] to learn an end-to-end part detector and spatial
model for pose estimation, although they do not exposit on
or analyze this method.
Alternatively, He et al. [17] discard the non-
convolutional portion of classification nets to make a
feature extractor. They combine proposals and spatial
pyramid pooling to yield a localized, fixed-length feature
for classification. While fast and effective, this hybrid
model cannot be learned end-to-end.
Dense prediction with convnets Several recent works
have applied convnets to dense prediction problems, includ-
ing semantic segmentation by Ning et al. [27], Farabet et al.
[8], and Pinheiro and Collobert [28]; boundary prediction
for electron microscopy by Ciresan et al. [2] and for natural
images by a hybrid neural net/nearest neighbor model by
Ganin and Lempitsky [11]; and image restoration and depth
estimation by Eigen et al. [5, 6]. Common elements of these
approaches include
• small models restricting capacity and receptive fields;
• patchwise training [27, 2, 8, 28, 11];
• post-processing by superpixel projection, random field
regularization, filtering, or local classification [8, 2,
11];
• input shifting and output interlacing for dense output
[28, 11] as introduced by OverFeat [29];
• multi-scale pyramid processing [8, 28, 11];
• saturating tanh nonlinearities [8, 5, 28]; and
• ensembles [2, 11],
whereas our method does without this machinery. However,
we do study patchwise training 3.4 and “shift-and-stitch”
dense output 3.2 from the perspective of FCNs. We also
discuss in-network upsampling 3.3, of which the fully con-
nected prediction by Eigen et al. [6] is a special case.
Unlike these existing methods, we adapt and extend deep
classification architectures, using image classification as su-
pervised pre-training, and fine-tune fully convolutionally to
learn simply and efficiently from whole image inputs and
whole image ground thruths.
Hariharan et al. [16] and Gupta et al. [14] likewise adapt
deep classification nets to semantic segmentation, but do
so in hybrid proposal-classifier models. These approaches
fine-tune an R-CNN system [12] by sampling bounding
boxes and/or region proposals for detection, semantic seg-
mentation, and instance segmentation. Neither method is
learned end-to-end.
They achieve state-of-the-art results on PASCAL VOC
segmentation and NYUDv2 segmentation respectively, so
we directly compare our standalone, end-to-end FCN to
their semantic segmentation results in Section 5.
3. Fully convolutional networks
Each layer of data in a convnet is a three-dimensional
array of size h × w × d, where h and w are spatial dimen-
sions, and d is the feature or channel dimension. The first
layer is the image, with pixel size h × w, and d color chan-
nels. Locations in higher layers correspond to the locations
in the image they are path-connected to, which are called
their receptive fields.
Convnets are built on translation invariance. Their ba-
sic components (convolution, pooling, and activation func-
tions) operate on local input regions, and depend only on
relative spatial coordinates. Writing x
ij
for the data vector
at location (i, j) in a particular layer, and y
ij
for the follow-
of 10
50墨值下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

评论