




hbase 架构
5墨值下载
HBase 架构简介
一、概览
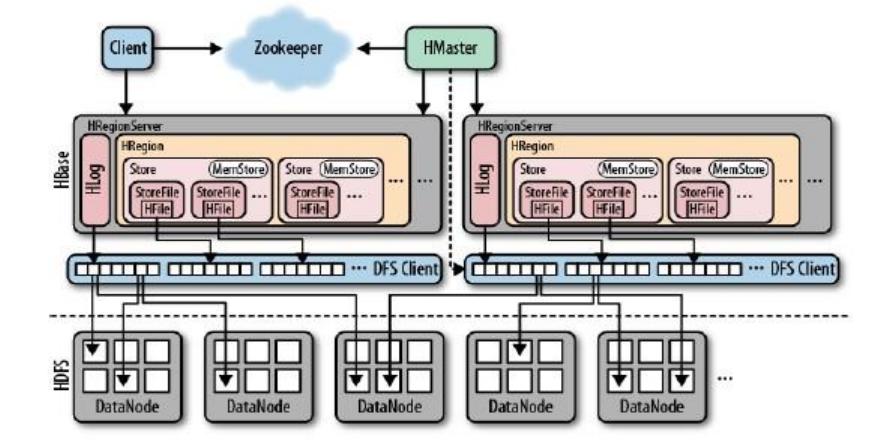
图 1
图 1 指出了在 HBase 中其实有两种文件,一种是 write-ahead log,而另一种
则是真正存储数据的地方。而这些文件都被 HRegionServers 来处理。从图中可以
看出,文件最后在 HDFS 中存在不同的 block 中。
基本的通信流程是这样的:当一个 client 需要查询某一特点的 row 时,它会
先连到 Zookeeper(事实上是 ZK 管理的集群),并且从 zookeeper 获取持有-ROOT-
的 region 的 server name,有了这个信息以后,我们就可以去寻找包含刚刚我们
查询的 row 的.META.的 region 的 server name。这些信息都会被客户端缓存下来。
最后,我们可以通过.META.找到持有我们所查询的 rowkey 的 region。一旦获取
了这个 row 在哪个 region 中,这个信息也会被客户端缓存下来,所以下次再访
问的时候,就可以直接访问那个 region 了。过了一段时间后,客户端就会搜集到
相当全面的信息:查询某 row 时应到哪个 region 去找,从而不需要去查询.META.
了。
当 HBase 启动时,HMaster 负责向各个 RS 分配 region,其中当然也包括了
-ROOT-和.META.某 RS 打开一个 Region,这时会创建一个相应的 HRegion 对象,
当 HRegion 打开时,它会为每一个 HColumnFamily 创建一个 Store,每一个 Store
都会有一个或者多个 StoreFile 的实例,它是对真正的存储文件 HFile 的轻量级封
装。每一个 Store 都会有一个 MemStore,并且整个 RS 会共享一个 HLog 实例。
二、写
当一个 client 向 RS 发起一个 HTable.put(Put)的请求时,第一步先把数据写入
write-ahead-log(WAL),被 HLog 所表示,这个 WAL 是一个标准的 Hadoo SequenceFile,
当 Server 挂掉以后再重启, WAL 可以继续将未被持久化的数据持久化。
一旦数据被写入 WAL,它就被放到 MemStore 中,与此同时,会检查 MemStore
是否已经满了,假如已经满了,那么就需要把 MemStore 中的数据 flush 到磁盘
上,这个动作由 RS 中一个独立的线程来完成,它会把数据存入 HDFS 上的一个
新的 HFile 中。同时它也会记录最后一次被写入的 Sequence number,这样就能
知道到目前为止,哪些数据已经被持久化了。
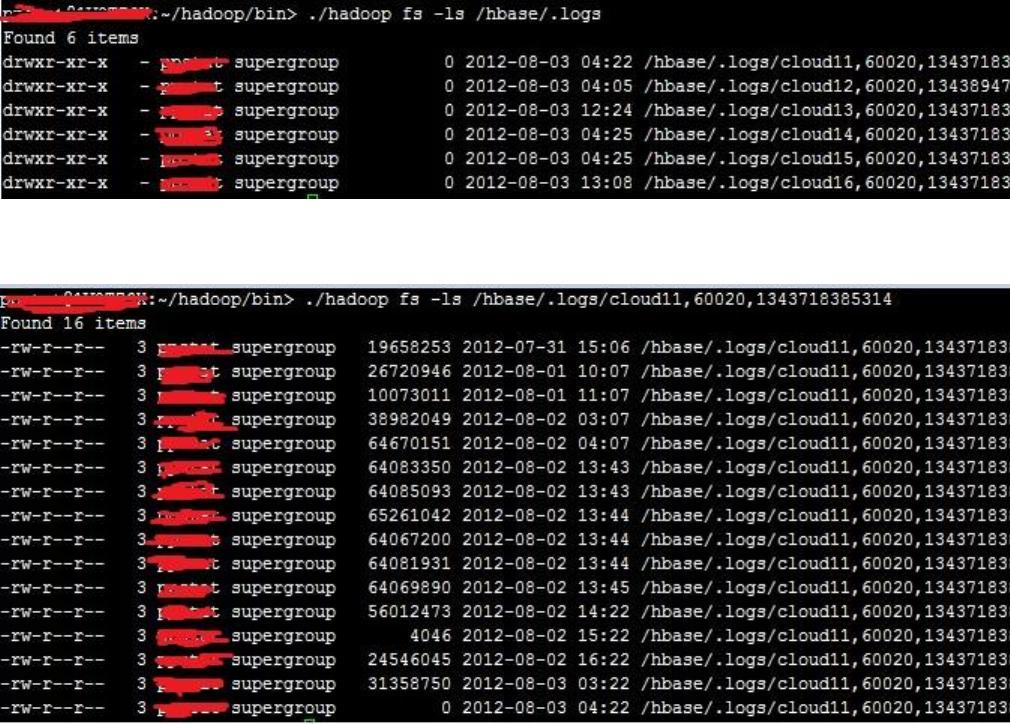
HBase 在 HDFS 有一个可配置的目录,默认是/hbase,你可以使用 hadoop fs –lsr
查看 hbase 所存储的各个文件。
首当其冲的就是 WAL 文件,它们被放在根目录下的.logs 文件夹下,假如我
这边有 6 台 rs 组成的测试环境,结构如下:
每个 rs 的子目录中存有若干个 HFiles。为什么会有多个?(答:log rotation)
这台 rs 上的所有 region 共享相同的 HLog files。我们注意到有 log 文件的大小为 0,
这其实是在这个文件刚刚创建时相当正常的情况。因为 hdfs 用它内置的 append
操作来向文件里写,只有当这个 block 写完的时候才会让客户端看到。
当一个 log 文件的所有数据都被持久化后而不再需要被使用时,它就会被放
到.oldlogs 中,同样的,这个目录也在根目录下。
of 5
5墨值下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

评论