




12.Rich feature hierarchies for accurate object detection and semantic segmentation.pdf
50墨值下载
Rich feature hierarchies for accurate object detection and semantic segmentation
Tech report (v5)
Ross Girshick Jeff Donahue Trevor Darrell Jitendra Malik
UC Berkeley
{rbg,jdonahue,trevor,malik}@eecs.berkeley.edu
Abstract
Object detection performance, as measured on the
canonical PASCAL VOC dataset, has plateaued in the last
few years. The best-performing methods are complex en-
semble systems that typically combine multiple low-level
image features with high-level context. In this paper, we
propose a simple and scalable detection algorithm that im-
proves mean average precision (mAP) by more than 30%
relative to the previous best result on VOC 2012—achieving
a mAP of 53.3%. Our approach combines two key insights:
(1) one can apply high-capacity convolutional neural net-
works (CNNs) to bottom-up region proposals in order to
localize and segment objects and (2) when labeled training
data is scarce, supervised pre-training for an auxiliary task,
followed by domain-specific fine-tuning, yields a significant
performance boost. Since we combine region proposals
with CNNs, we call our method R-CNN: Regions with CNN
features. We also compare R-CNN to OverFeat, a recently
proposed sliding-window detector based on a similar CNN
architecture. We find that R-CNN outperforms OverFeat
by a large margin on the 200-class ILSVRC2013 detection
dataset. Source code for the complete system is available at
http://www.cs.berkeley.edu/
˜
rbg/rcnn.
1. Introduction
Features matter. The last decade of progress on various
visual recognition tasks has been based considerably on the
use of SIFT [29] and HOG [7]. But if we look at perfor-
mance on the canonical visual recognition task, PASCAL
VOC object detection [15], it is generally acknowledged
that progress has been slow during 2010-2012, with small
gains obtained by building ensemble systems and employ-
ing minor variants of successful methods.
SIFT and HOG are blockwise orientation histograms,
a representation we could associate roughly with complex
cells in V1, the first cortical area in the primate visual path-
way. But we also know that recognition occurs several
stages downstream, which suggests that there might be hier-
1. Input
image
2. Extract region
proposals (~2k)
3. Compute
CNN features
aeroplane? no.
.
.
.
person? yes.
tvmonitor? no.
4. Classify
regions
warped region
.
.
.
CNN
R-CNN: Regions with CNN features
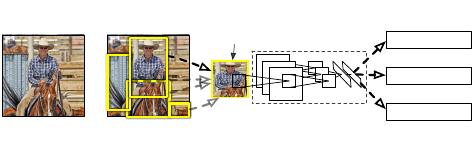
Figure 1: Object detection system overview. Our system (1)
takes an input image, (2) extracts around 2000 bottom-up region
proposals, (3) computes features for each proposal using a large
convolutional neural network (CNN), and then (4) classifies each
region using class-specific linear SVMs. R-CNN achieves a mean
average precision (mAP) of 53.7% on PASCAL VOC 2010. For
comparison, [39] reports 35.1% mAP using the same region pro-
posals, but with a spatial pyramid and bag-of-visual-words ap-
proach. The popular deformable part models perform at 33.4%.
On the 200-class ILSVRC2013 detection dataset, R-CNN’s
mAP is 31.4%, a large improvement over OverFeat [34], which
had the previous best result at 24.3%.
archical, multi-stage processes for computing features that
are even more informative for visual recognition.
Fukushima’s “neocognitron” [19], a biologically-
inspired hierarchical and shift-invariant model for pattern
recognition, was an early attempt at just such a process.
The neocognitron, however, lacked a supervised training
algorithm. Building on Rumelhart et al. [33], LeCun et
al. [26] showed that stochastic gradient descent via back-
propagation was effective for training convolutional neural
networks (CNNs), a class of models that extend the neocog-
nitron.
CNNs saw heavy use in the 1990s (e.g., [27]), but then
fell out of fashion with the rise of support vector machines.
In 2012, Krizhevsky et al. [25] rekindled interest in CNNs
by showing substantially higher image classification accu-
racy on the ImageNet Large Scale Visual Recognition Chal-
lenge (ILSVRC) [9, 10]. Their success resulted from train-
ing a large CNN on 1.2 million labeled images, together
with a few twists on LeCun’s CNN (e.g., max(x, 0) rectify-
ing non-linearities and “dropout” regularization).
The significance of the ImageNet result was vigorously
1
arXiv:1311.2524v5 [cs.CV] 22 Oct 2014
debated during the ILSVRC 2012 workshop. The central
issue can be distilled to the following: To what extent do
the CNN classification results on ImageNet generalize to
object detection results on the PASCAL VOC Challenge?
We answer this question by bridging the gap between
image classification and object detection. This paper is the
first to show that a CNN can lead to dramatically higher ob-
ject detection performance on PASCAL VOC as compared
to systems based on simpler HOG-like features. To achieve
this result, we focused on two problems: localizing objects
with a deep network and training a high-capacity model
with only a small quantity of annotated detection data.
Unlike image classification, detection requires localiz-
ing (likely many) objects within an image. One approach
frames localization as a regression problem. However, work
from Szegedy et al. [38], concurrent with our own, indi-
cates that this strategy may not fare well in practice (they
report a mAP of 30.5% on VOC 2007 compared to the
58.5% achieved by our method). An alternative is to build a
sliding-window detector. CNNs have been used in this way
for at least two decades, typically on constrained object cat-
egories, such as faces [32, 40] and pedestrians [35]. In order
to maintain high spatial resolution, these CNNs typically
only have two convolutional and pooling layers. We also
considered adopting a sliding-window approach. However,
units high up in our network, which has five convolutional
layers, have very large receptive fields (195 × 195 pixels)
and strides (32×32 pixels) in the input image, which makes
precise localization within the sliding-window paradigm an
open technical challenge.
Instead, we solve the CNN localization problem by oper-
ating within the “recognition using regions” paradigm [21],
which has been successful for both object detection [39] and
semantic segmentation [5]. At test time, our method gener-
ates around 2000 category-independent region proposals for
the input image, extracts a fixed-length feature vector from
each proposal using a CNN, and then classifies each region
with category-specific linear SVMs. We use a simple tech-
nique (affine image warping) to compute a fixed-size CNN
input from each region proposal, regardless of the region’s
shape. Figure 1 presents an overview of our method and
highlights some of our results. Since our system combines
region proposals with CNNs, we dub the method R-CNN:
Regions with CNN features.
In this updated version of this paper, we provide a head-
to-head comparison of R-CNN and the recently proposed
OverFeat [34] detection system by running R-CNN on the
200-class ILSVRC2013 detection dataset. OverFeat uses a
sliding-window CNN for detection and until now was the
best performing method on ILSVRC2013 detection. We
show that R-CNN significantly outperforms OverFeat, with
a mAP of 31.4% versus 24.3%.
A second challenge faced in detection is that labeled data
is scarce and the amount currently available is insufficient
for training a large CNN. The conventional solution to this
problem is to use unsupervised pre-training, followed by su-
pervised fine-tuning (e.g., [35]). The second principle con-
tribution of this paper is to show that supervised pre-training
on a large auxiliary dataset (ILSVRC), followed by domain-
specific fine-tuning on a small dataset (PASCAL), is an
effective paradigm for learning high-capacity CNNs when
data is scarce. In our experiments, fine-tuning for detection
improves mAP performance by 8 percentage points. After
fine-tuning, our system achieves a mAP of 54% on VOC
2010 compared to 33% for the highly-tuned, HOG-based
deformable part model (DPM) [17, 20]. We also point read-
ers to contemporaneous work by Donahue et al. [12], who
show that Krizhevsky’s CNN can be used (without fine-
tuning) as a blackbox feature extractor, yielding excellent
performance on several recognition tasks including scene
classification, fine-grained sub-categorization, and domain
adaptation.
Our system is also quite efficient. The only class-specific
computations are a reasonably small matrix-vector product
and greedy non-maximum suppression. This computational
property follows from features that are shared across all cat-
egories and that are also two orders of magnitude lower-
dimensional than previously used region features (cf. [39]).
Understanding the failure modes of our approach is also
critical for improving it, and so we report results from the
detection analysis tool of Hoiem et al. [23]. As an im-
mediate consequence of this analysis, we demonstrate that
a simple bounding-box regression method significantly re-
duces mislocalizations, which are the dominant error mode.
Before developing technical details, we note that because
R-CNN operates on regions it is natural to extend it to the
task of semantic segmentation. With minor modifications,
we also achieve competitive results on the PASCAL VOC
segmentation task, with an average segmentation accuracy
of 47.9% on the VOC 2011 test set.
2. Object detection with R-CNN
Our object detection system consists of three modules.
The first generates category-independent region proposals.
These proposals define the set of candidate detections avail-
able to our detector. The second module is a large convo-
lutional neural network that extracts a fixed-length feature
vector from each region. The third module is a set of class-
specific linear SVMs. In this section, we present our design
decisions for each module, describe their test-time usage,
detail how their parameters are learned, and show detection
results on PASCAL VOC 2010-12 and on ILSVRC2013.
2.1. Module design
Region proposals. A variety of recent papers offer meth-
ods for generating category-independent region proposals.
2
of 21
50墨值下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

评论