




21.R-FCN_ Object Detection via Region-based Fully Convolutional Networks.pdf
50墨值下载

R-FCN: Object Detection via
Region-based Fully Convolutional Networks
Jifeng Dai
Microsoft Research
Yi Li
∗
Tsinghua University
Kaiming He
Microsoft Research
Jian Sun
Microsoft Research
Abstract
We present region-based, fully convolutional networks for accurate and efficient
object detection. In contrast to previous region-based detectors such as Fast/Faster
R-CNN [
6
,
18
] that apply a costly per-region subnetwork hundreds of times, our
region-based detector is fully convolutional with almost all computation shared on
the entire image. To achieve this goal, we propose position-sensitive score maps
to address a dilemma between translation-invariance in image classification and
translation-variance in object detection. Our method can thus naturally adopt fully
convolutional image classifier backbones, such as the latest Residual Networks
(ResNets) [
9
], for object detection. We show competitive results on the PASCAL
VOC datasets (e.g., 83.6% mAP on the 2007 set) with the 101-layer ResNet.
Meanwhile, our result is achieved at a test-time speed of 170ms per image, 2.5-20
×
faster than the Faster R-CNN counterpart. Code is made publicly available at:
https://github.com/daijifeng001/r-fcn.
1 Introduction
A prevalent family [
8
,
6
,
18
] of deep networks for object detection can be divided into two subnetworks
by the Region-of-Interest (RoI) pooling layer [
6
]: (i) a shared, “fully convolutional” subnetwork
independent of RoIs, and (ii) an RoI-wise subnetwork that does not share computation. This
decomposition [
8
] was historically resulted from the pioneering classification architectures, such
as AlexNet [
10
] and VGG Nets [
23
], that consist of two subnetworks by design — a convolutional
subnetwork ending with a spatial pooling layer, followed by several fully-connected (fc) layers. Thus
the (last) spatial pooling layer in image classification networks is naturally turned into the RoI pooling
layer in object detection networks [8, 6, 18].
But recent state-of-the-art image classification networks such as Residual Nets (ResNets) [
9
] and
GoogLeNets [
24
,
26
] are by design fully convolutional
2
. By analogy, it appears natural to use
all convolutional layers to construct the shared, convolutional subnetwork in the object detection
architecture, leaving the RoI-wise subnetwork no hidden layer. However, as empirically investigated
in this work, this naïve solution turns out to have considerably inferior detection accuracy that does
not match the network’s superior classification accuracy. To remedy this issue, in the ResNet paper
[
9
] the RoI pooling layer of the Faster R-CNN detector [
18
] is unnaturally inserted between two sets
of convolutional layers — this creates a deeper RoI-wise subnetwork that improves accuracy, at the
cost of lower speed due to the unshared per-RoI computation.
We argue that the aforementioned unnatural design is caused by a dilemma of increasing translation
invariance for image classification vs. respecting translation variance for object detection. On one
hand, the image-level classification task favors translation invariance — shift of an object inside an
image should be indiscriminative. Thus, deep (fully) convolutional architectures that are as translation-
invariant as possible are preferable as evidenced by the leading results on ImageNet classification
∗
This work was done when Yi Li was an intern at Microsoft Research.
2
Only the last layer is fully-connected, which is removed and replaced when fine-tuning for object detection.
arXiv:1605.06409v2 [cs.CV] 21 Jun 2016
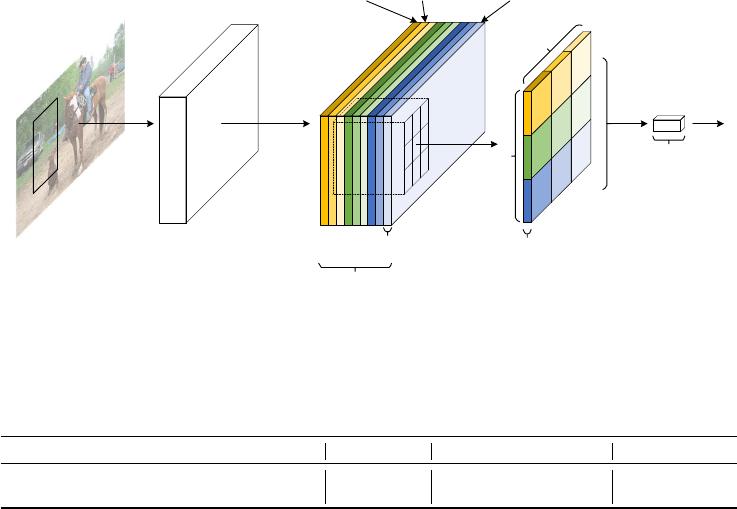
image
conv
position-sensitive
score maps
feature
maps
k
2
(C+1)-d
conv
k
2
(C+1)
…...
bottom-right
RoI
C+1
pool
top-left top-center
k
k
C+1
vote
C+1
softmax
Figure 1: Key idea of
R-FCN
for object detection. In this illustration, there are
k × k = 3 × 3
position-sensitive score maps generated by a fully convolutional network. For each of the
k × k
bins
in an RoI, pooling is only performed on one of the k
2
maps (marked by different colors).
Table 1: Methodologies of region-based detectors using ResNet-101 [9].
R-CNN [7] Faster R-CNN [19, 9] R-FCN [ours]
depth of shared convolutional subnetwork 0 91 101
depth of RoI-wise subnetwork 101 10 0
[
9
,
24
,
26
]. On the other hand, the object detection task needs localization representations that are
translation-variant to an extent. For example, translation of an object inside a candidate box should
produce meaningful responses for describing how good the candidate box overlaps the object. We
hypothesize that deeper convolutional layers in an image classification network are less sensitive
to translation. To address this dilemma, the ResNet paper’s detection pipeline [
9
] inserts the RoI
pooling layer into convolutions — this region-specific operation breaks down translation invariance,
and the post-RoI convolutional layers are no longer translation-invariant when evaluated across
different regions. However, this design sacrifices training and testing efficiency since it introduces a
considerable number of region-wise layers (Table 1).
In this paper, we develop a framework called Region-based Fully Convolutional Network (R-FCN)
for object detection. Our network consists of shared, fully convolutional architectures as is the case of
FCN [
15
]. To incorporate translation variance into FCN, we construct a set of position-sensitive score
maps by using a bank of specialized convolutional layers as the FCN output. Each of these score
maps encodes the position information with respect to a relative spatial position (e.g., “to the left of
an object”). On top of this FCN, we append a position-sensitive RoI pooling layer that shepherds
information from these score maps, with no weight (convolutional/fc) layers following. The entire
architecture is learned end-to-end. All learnable layers are convolutional and shared on the entire
image, yet encode spatial information required for object detection. Figure 1 illustrates the key idea
and Table 1 compares the methodologies among region-based detectors.
Using the 101-layer Residual Net (ResNet-101) [9] as the backbone, our R-FCN yields competitive
results of 83.6% mAP on the PASCAL VOC 2007 set and 82.0% the 2012 set. Meanwhile, our results
are achieved at a test-time speed of 170ms per image using ResNet-101, which is 2.5
×
to 20
×
faster
than the Faster R-CNN + ResNet-101 counterpart in [
9
]. These experiments demonstrate that our
method manages to address the dilemma between invariance/variance on translation, and fully convolu-
tional image-level classifiers such as ResNets can be effectively converted to fully convolutional object
detectors. Code is made publicly available at: https://github.com/daijifeng001/r-fcn.
2 Our approach
Overview.
Following R-CNN [
7
], we adopt the popular two-stage object detection strategy [
7
,
8
,
6
,
18
,
1
,
22
] that consists of: (i) region proposal, and (ii) region classification. Although methods that
do not rely on region proposal do exist (e.g., [
17
,
14
]), region-based systems still possess leading
2
of 11
50墨值下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

评论